Clear Sky Science · en
A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy
Why protecting health data still matters
Hospitals and health agencies now rely on artificial intelligence to forecast outbreaks of flu, COVID-19, and other infections days or weeks in advance. These predictions can guide vaccine campaigns, staffing, and emergency planning. Yet the same detailed patient records that make forecasts accurate are also extremely sensitive. Laws and public concern often prevent data from being pooled across institutions, which weakens the power of these models. This paper introduces a way to train high-quality infectious disease prediction systems while keeping each hospital’s data locked safely on site.
Learning from many hospitals without sharing charts
The authors build on a technique called federated learning, in which several hospitals train a shared prediction model together. Instead of copying raw patient records to a central server, each site trains the model locally and only sends back numerical updates to the model’s internal settings. A central server combines these updates and sends the improved model back out. This loop repeats many times. In theory, federated learning protects privacy because personal information never leaves the building. In practice, however, clever attackers can sometimes infer details about the underlying data from the shared updates, so extra protection is needed. 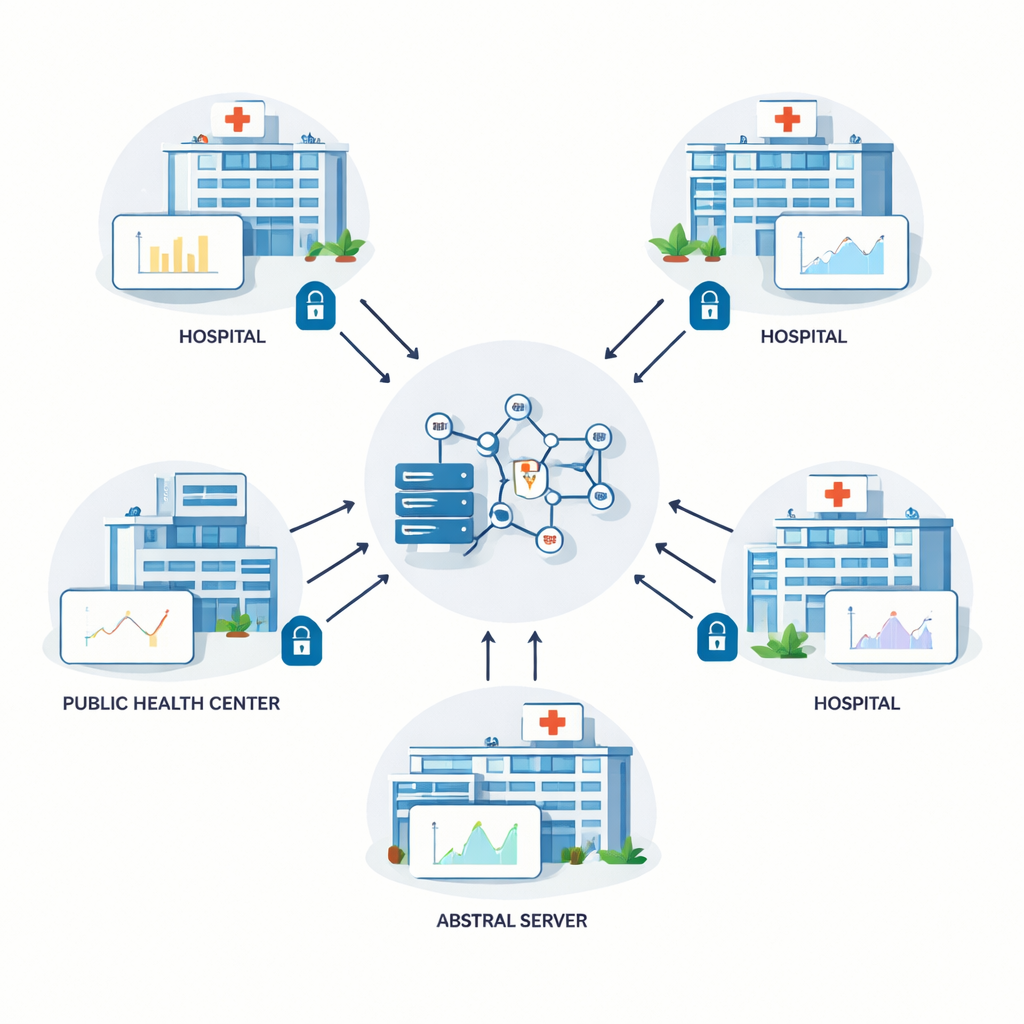
Locking the numbers with smart encryption
To harden security, the team uses homomorphic encryption—a form of digital lock that allows computations to be performed directly on encrypted numbers, without ever seeing them in plain form. Traditional schemes of this kind are very safe but notoriously slow and data-hungry, making them hard to use with large, complex models such as those based on Long Short-Term Memory (LSTM) networks. The researchers design a hybrid scheme that treats different parts of the model differently. The most revealing components are protected with a strong but heavy form of encryption, while less sensitive parts use a lighter, faster lock. On top of this, a pre-planned random schedule decides in which training rounds sites actually send encrypted updates, allowing them to skip redundant communication. Tests show that this combination speeds up training by about 25 percent compared with using the heavy encryption everywhere, while keeping data protected under strong cryptographic assumptions.
Sending only the updates that truly matter
Even with smarter locking, shipping every tiny change in the model back and forth between institutions wastes time and network bandwidth. The authors therefore propose a new training rule called Data Selection–Distributed Selection Stochastic Gradient Descent (DS-DSSGD). During training, the algorithm measures how much each part of the model changes from one step to the next. Only updates that cross a preset threshold are transmitted; small, low-impact changes are simply ignored. At the same time, the algorithm tracks which data points are responsible for the largest, most informative changes. These influential records are collected into a refined dataset used for a final round of training. Experiments on three years of real infection reports from Yichang City, combined with local web search trends, show that DS-DSSGD cuts training time by roughly 10 percent compared with several standard methods, without any meaningful loss in predictive accuracy.
A practical platform for secure collaboration
Technical advances matter only if hospitals and laboratories can actually use them. To close this gap, the team integrates their methods into a real computing environment called the Yi Shu Fang XDP Privacy Security Computing Platform. XDP manages the full journey of health data, from collection and cleaning to encrypted analysis and sharing of results. It supports familiar tools used by statisticians, bioinformaticians, and clinicians, and allows researchers from different institutions to collaborate inside a controlled workspace without ever downloading raw data. Within this platform, the hybrid encryption scheme and DS-DSSGD algorithm run as pluggable components, turning the theoretical framework into a working system. 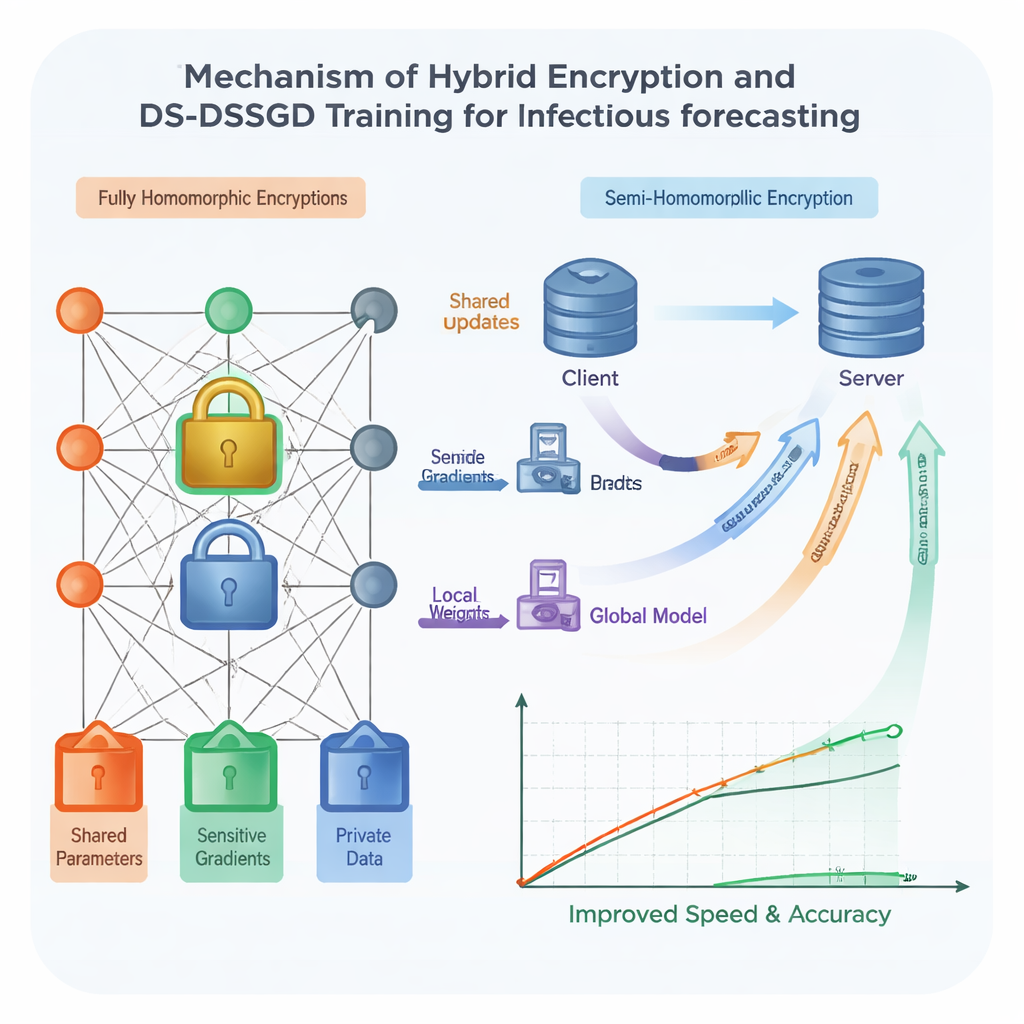
What this means for future outbreak prediction
In everyday terms, this study shows that it is possible to “have it both ways” for infectious disease forecasting: protecting patient privacy while still training fast, accurate models on data drawn from many institutions. By encrypting different parts of the model with just the right level of strength, sending updates only when necessary, and wrapping everything inside a secure collaboration platform, the authors reduce the cost of privacy from a crippling burden to a manageable overhead. If adopted widely, such approaches could allow hospitals and public health agencies to pool their knowledge against the next epidemic without ever exposing individual medical records.
Citation: Wang, X., Jiang, Y., Pan, G. et al. A data privacy protection method for infectious disease prediction models with balanced training speed and accuracy. Sci Rep 16, 7415 (2026). https://doi.org/10.1038/s41598-026-38906-9
Keywords: infectious disease forecasting, health data privacy, federated learning, homomorphic encryption, deep learning