Clear Sky Science · en
Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom
Why phone fraud matters to everyone
Every time we make a call, send a text, or use mobile data, we trust that the bill reflects what we actually used. But criminals can exploit phone networks by opening lines with fake identities, racking up huge unpaid charges, and even using those lines for other crimes. This study focuses on Ethio Telecom, Ethiopia’s national operator, and shows how advanced data-driven methods can spot suspicious subscriptions far more accurately than traditional tools, helping keep phone services affordable and secure for millions of users.
The hidden cost of fake phone accounts
Subscription fraud happens when someone signs up for phone service with false or stolen details and never intends to pay. Around the world this is one of the most damaging forms of telecom fraud, costing the industry tens of billions of dollars each year. For Ethio Telecom alone, fraud is estimated to drain about a billion dollars annually, with bogus subscriptions responsible for roughly 40% of that loss. Beyond lost revenue, these lines can be used for scams, international call reselling, or other illicit activities, posing risks to both customers and national security.
From hand-made rules to learning from data
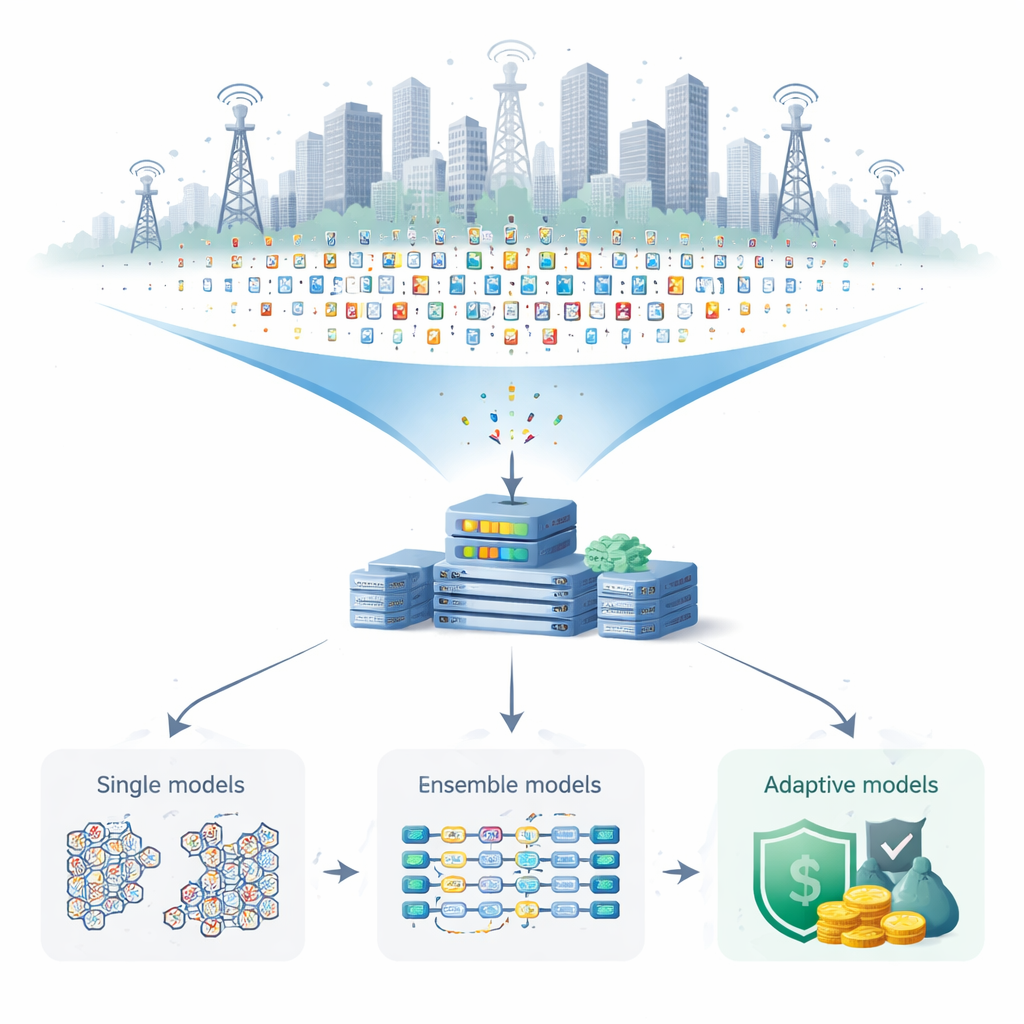
Like many operators, Ethio Telecom traditionally relied on experts crafting fixed rules to flag suspicious behavior—for example, blocking a line after too many international calls in a short time. These rule-based systems are easy to understand but struggle when fraudsters change tactics or when usage patterns are complex. The authors argue that machine learning, which learns patterns directly from past data, can respond more quickly and sensitively. Instead of depending on a single model, they explore “ensemble” methods that combine several models, and “adaptive” methods that keep updating as new data flows in.
What the researchers built from real call records
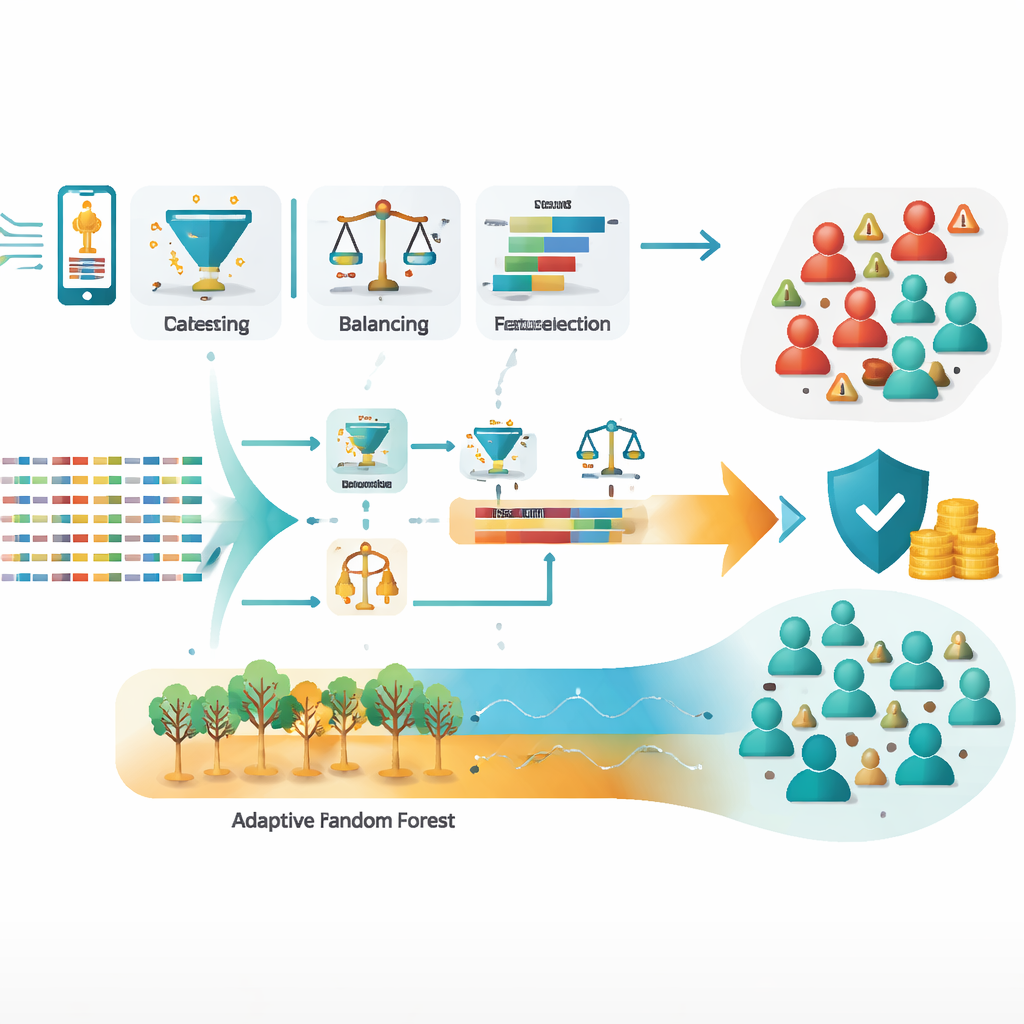
The team worked with a large set of call detail records—logs of who called whom, for how long, and under what conditions—from a two‑month period known for intense fraud activity. Starting from about one million raw records, they cleaned the data, removed errors and duplicates, balanced the heavily skewed classes (many more honest users than fraudsters), and engineered new features that better capture suspicious behavior. Particularly important were measures such as how many international numbers a subscriber dialled, the share of all calls that were international, and the ratio of unique numbers called to total calls. These distilled signals often distinguish normal use from organized abuse much better than simple counts or demographics.
How combining models boosts detection
The researchers tested three standard models—decision trees, logistic regression, and artificial neural networks—alongside several ensemble strategies such as bagging (Random Forest), boosting (XGBoost), voting, and stacking, plus adaptive models designed for continuous data streams (Hoeffding Tree and Adaptive Random Forest). After careful tuning of each model’s settings, the stacking approach, which learns how to blend the strengths of multiple base models, achieved about 99.3% accuracy on unseen data. The Adaptive Random Forest was almost as strong, with about 99.2% accuracy, while also being able to adjust as fraud patterns shift over time. Both approaches sharply reduced the most dangerous error—missing actual fraud—compared with single models alone.
Keeping up with changing tricks in real time
Because fraudsters constantly change their methods, a static model can quickly become outdated. To handle this, the authors used an online feature selection technique that continuously re‑evaluates which signals matter most, without having to rebuild the system from scratch. They also stress the importance of privacy: all personal identifiers in the data were anonymized before analysis, and they recommend strict access controls and audit trails. For practical deployment, the study sketches a real-time architecture in which new call records stream through tools like Apache Kafka into adaptive models that update on the fly while monitoring for sudden shifts in behavior.
What this means for phone users and providers
In plain terms, the study shows that letting multiple intelligent models “vote” together, and allowing them to learn continuously, can catch fake subscriptions with remarkable accuracy while keeping false alarms at manageable levels. For Ethio Telecom, this could translate into substantial savings, more stable pricing, and stronger protection against criminal misuse of the network. For customers, it means that unusual but legitimate usage is less likely to be misread as fraud, while genuinely risky lines are detected and closed faster. The authors conclude that ensemble and adaptive learning, grounded in carefully chosen, context‑specific indicators, provide a powerful and scalable blueprint for modern telecom fraud detection.
Citation: Desta, E.A., Azale, K.W., Hailu, A.A. et al. Enhancing subscription fraud detection through ensemble learning the case of Ethio telecom. Sci Rep 16, 7867 (2026). https://doi.org/10.1038/s41598-026-38790-3
Keywords: telecom fraud, subscription fraud, ensemble learning, adaptive random forest, call detail records