Clear Sky Science · en
Facial expression recognition via variational inference
Reading Feelings from Faces
Our faces constantly broadcast how we feel, but those signals are rarely simple. A smile can hide nervousness, and a “neutral” look may mix boredom with irritation. This study introduces POSTER-Var, a new artificial intelligence (AI) system that aims to read such subtle, mixed emotions more accurately than today’s facial expression tools, potentially improving everything from human–computer interaction to mental health monitoring.
Why Emotions Are Not Just On or Off
Most existing facial expression recognition systems treat emotions as neat, separate boxes: happy, sad, angry, and so on. In reality, psychology shows that expressions are blends of basic emotions, with different strengths appearing at once in a single face. Traditional AI models usually force each image into one hard label, ignoring uncertainty and the continuous, graded nature of feelings. This makes them brittle in messy real-world settings, where lighting, pose, and even inconsistent human labels add noise. The authors argue that future systems must acknowledge that a face can hint at several emotions at different intensities, and that computers should reason in terms of probabilities rather than yes-or-no decisions.
Letting the Model Embrace Uncertainty
To better match this messy reality, the team builds on a technique from modern probabilistic modeling called variational inference. Instead of producing a single fixed score for each emotion, their POSTER-Var system maps facial features into a “latent space” where each emotion is represented by a probability distribution, typically shaped like a bell curve. During training, the system draws samples from these learned distributions, encouraging it to explore a range of possible interpretations of each face. At test time, however, it simply uses the centers of these distributions to make stable predictions. Crucially, POSTER-Var removes extra decoding and fully connected layers used in earlier variational designs, treating the probabilistic representation itself as the final decision signal. This streamlined “Variational Inference-based Classification Head,” or VICH, lets the model quantify uncertainty while staying efficient and accurate.
Seeing the Face at Multiple Scales
Recognizing expressions also requires looking at different parts of the face and at different levels of detail: the curve of the mouth, the shape of the eyes, and the overall configuration all matter. POSTER-Var extends a strong prior system (POSTER++) by improving how these multi-scale features are combined. It uses several attention mechanisms to fuse information from a standard image backbone and a facial landmark detector, which tracks key points like eye corners and mouth edges. A “layer embedding” marks each feature map with its position and semantic level in the processing pyramid, helping the network understand which details come from where. Nonlinear transformations and an enhanced channel-attention block then re-balance these features, boosting those that are most informative for expressions while suppressing distractions such as background clutter or identity-specific quirks.
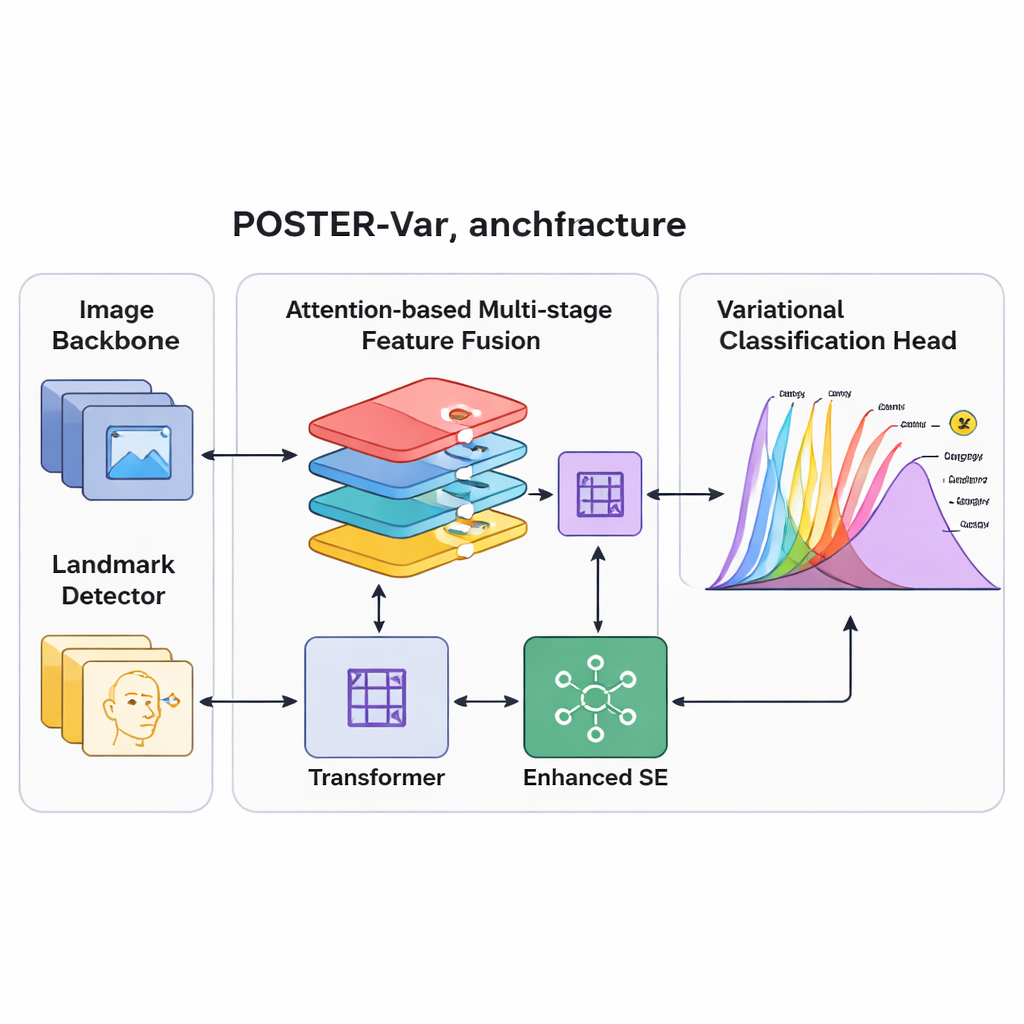
Putting the System to the Test
The researchers evaluated POSTER-Var on three widely used real-world datasets: RAF-DB, AffectNet, and FER+. These collections include hundreds of thousands of faces captured in uncontrolled conditions, each labeled with one of several basic emotions. Across all benchmarks, POSTER-Var either matched or surpassed the current state-of-the-art methods. For example, it reached about 93% accuracy on RAF-DB and roughly 92% on FER+, and slightly improved results on both 7-class and 8-class versions of AffectNet. Ablation experiments, where individual components were removed, showed that both the layer embedding and the variational head noticeably contributed to performance, with the variational component particularly helpful on harder, more imbalanced datasets. Visualizations of attention maps revealed that POSTER-Var focuses on broader, more meaningful facial regions than the baseline, and plots of its learned emotion distributions illustrated how it better separates, for instance, “sad” from “neutral” in ambiguous cases.
What This Means for Real-World Applications
In plain terms, POSTER-Var teaches machines to treat facial expressions less like traffic lights and more like weather forecasts: there can be a main “sunny” mood with scattered “cloudy” hints, and the forecast should acknowledge uncertainty. By modeling full distributions over emotions rather than a single guess, the system becomes more robust to noisy labels and subtle, blended expressions. The study suggests that such probabilistic approaches could underpin the next generation of affect-aware technologies, making virtual assistants, social robots, and behavioral research tools more attuned to the complex emotional lives that our faces only imperfectly reveal.
Citation: Lv, G., Zhang, J. & Tsoi, C. Facial expression recognition via variational inference. Sci Rep 16, 7323 (2026). https://doi.org/10.1038/s41598-026-38734-x
Keywords: facial expression recognition, emotion AI, probabilistic modeling, variational inference, computer vision