Clear Sky Science · en
Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1
Why this matters for doctors and patients
Artificial intelligence is rapidly entering medical classrooms and clinics, but most tests of these tools focus on English. This study asks a question that matters to millions of Persian speakers: how well do advanced AI chatbots, specifically GPT‑4o and GPT‑5.1, handle complex rheumatology exam questions written in Persian? The answer helps educators, trainees, and patients understand where these tools can safely assist learning and where human expertise remains essential.
Putting AI to the test
The researchers gathered 204 multiple‑choice questions from the official Iranian Rheumatology Board exams of 2023 and 2024, the same exams specialists must pass to be certified. After removing seven flawed questions, 197 items were used. Each question, including any accompanying images or graphs, was entered in Persian into GPT‑4o and GPT‑5.1 in separate fresh chats. The models were asked to pick the best answer and explain their reasoning, mirroring how a trainee might query an AI tool while studying.
Checking both answers and reasoning
Performance was judged in two ways. First, the models’ chosen options were compared with the official answer key, yielding a simple right‑or‑wrong accuracy measure. Second, six board‑certified rheumatologists independently rated the quality of each explanation on a five‑point scale, from clearly wrong reasoning to complete and clinically sound reasoning. Each model’s answers were scored by two different rheumatologists who were blinded to each other’s ratings and to the official answer key. This allowed the researchers to see not only whether the AI “guessed right,” but whether its logic resembled the way specialists think.
How the newer model performed
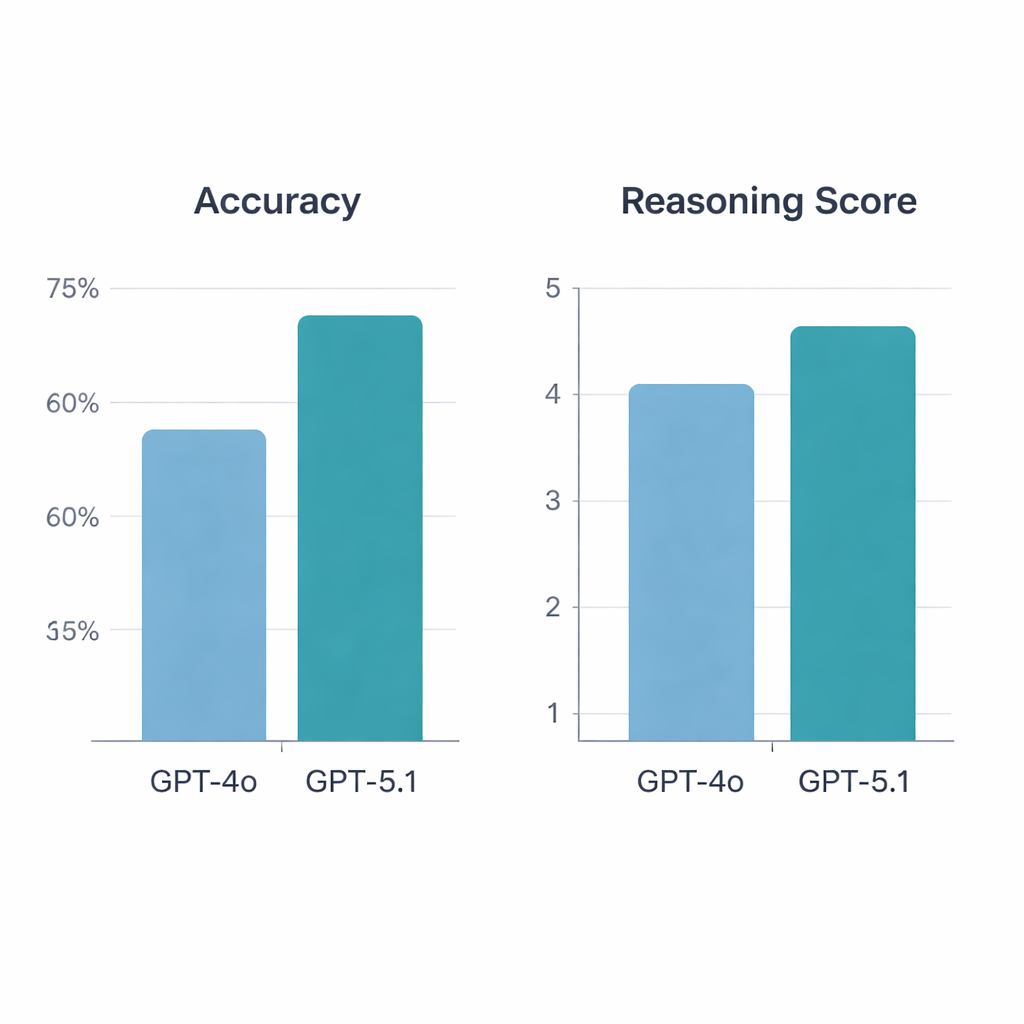
GPT‑5.1 clearly outperformed GPT‑4o. On the 197 valid questions, GPT‑4o answered 64.5% correctly, while GPT‑5.1 reached 76% accuracy—a statistically significant jump. Both models got 113 questions right and 34 wrong, but GPT‑5.1 alone solved 36 additional questions that GPT‑4o missed; GPT‑4o was uniquely correct on only 13. When rheumatologists graded the explanations, GPT‑5.1 again came out ahead, with an average reasoning score of 4.47 out of 5 compared with 4.13 for GPT‑4o, and it received more top‑score ratings. Unlike GPT‑4o, whose reasoning quality varied depending on whether a question focused on basic science, case vignettes, diagnosis, or treatment, GPT‑5.1 maintained more even performance across all categories.
Strengths, gaps, and human disagreements
The study uncovered important nuances. Even when a model’s final answer was wrong, specialists sometimes judged its reasoning to be fairly coherent, highlighting a gap between exam scoring and real‑world clinical thinking. At the same time, the agreement between rheumatologist raters was only modest, underscoring that clinicians themselves differ on what counts as “good reasoning.” Language also appeared to matter: earlier work in English and Spanish has reported higher scores for similar models, suggesting that AI still handles major world languages better than Persian. The authors stress that these chatbots can generate convincing explanations that may hide factual errors, and that their performance may change as the systems are updated.
What this means going forward
For lay readers, the message is that the newest generation of AI chatbots is getting better at handling specialist medical exams in Persian, but it is not ready to replace rigorous training or expert judgment. GPT‑5.1 can be a helpful study partner for rheumatology trainees—summarizing topics, walking through cases, and offering structured explanations—but it should not be trusted as the final word for high‑stakes decisions about diagnosis or treatment. The authors call for larger, multilingual studies, repeated testing over time, and realistic clinical simulations to determine how these tools can be safely woven into medical education and, eventually, into day‑to‑day patient care.
Citation: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
Keywords: rheumatology, Persian medical education, large language models, clinical reasoning, board examinations