Clear Sky Science · en
An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma
Why this matters for patients and families
For people who undergo surgery to remove liver cancer, one of the most pressing questions is, “Will the cancer come back soon?” Today, doctors can offer only rough estimates, often based on broad staging systems that treat many different patients as if they were the same. This study presents a new way to use information that hospitals already collect—routine blood tests and scan results—together with interpretable artificial intelligence to give each patient a clearer, more personalized picture of their short‑term risk that the cancer will return.
A common cancer with a stubborn comeback rate
Hepatocellular carcinoma is the most common type of primary liver cancer and a major cause of cancer deaths worldwide. Even when surgeons completely remove visible tumors, more than 70% of patients see the disease return within five years. Early recurrence—within about two years after surgery—is especially worrisome, because it usually reflects aggressive cancer cells that have already spread inside the liver, and it sharply worsens survival. Existing clinical staging systems, such as TNM or Barcelona Clinic Liver Cancer (BCLC), can roughly sort patients into broad categories but often fail to pinpoint who is truly at high risk of an early comeback.
Turning everyday test results into a risk score
The researchers drew on records from 1,120 patients who had apparently curative liver surgery at two major hospitals in China between 2014 and 2024. They focused only on information available before the operation: age and sex, imaging features like how big the largest tumor was and whether there were multiple tumors, and a wide panel of standard laboratory tests performed in the days leading up to surgery. From these, they screened for nine key predictors linked to the chance of recurrence. Rather than rely on a single mathematical formula, they combined three different machine learning approaches and averaged their outputs into one risk score between 0 and 1. Patients were then grouped into low-, moderate-, and high‑risk categories based on this score. 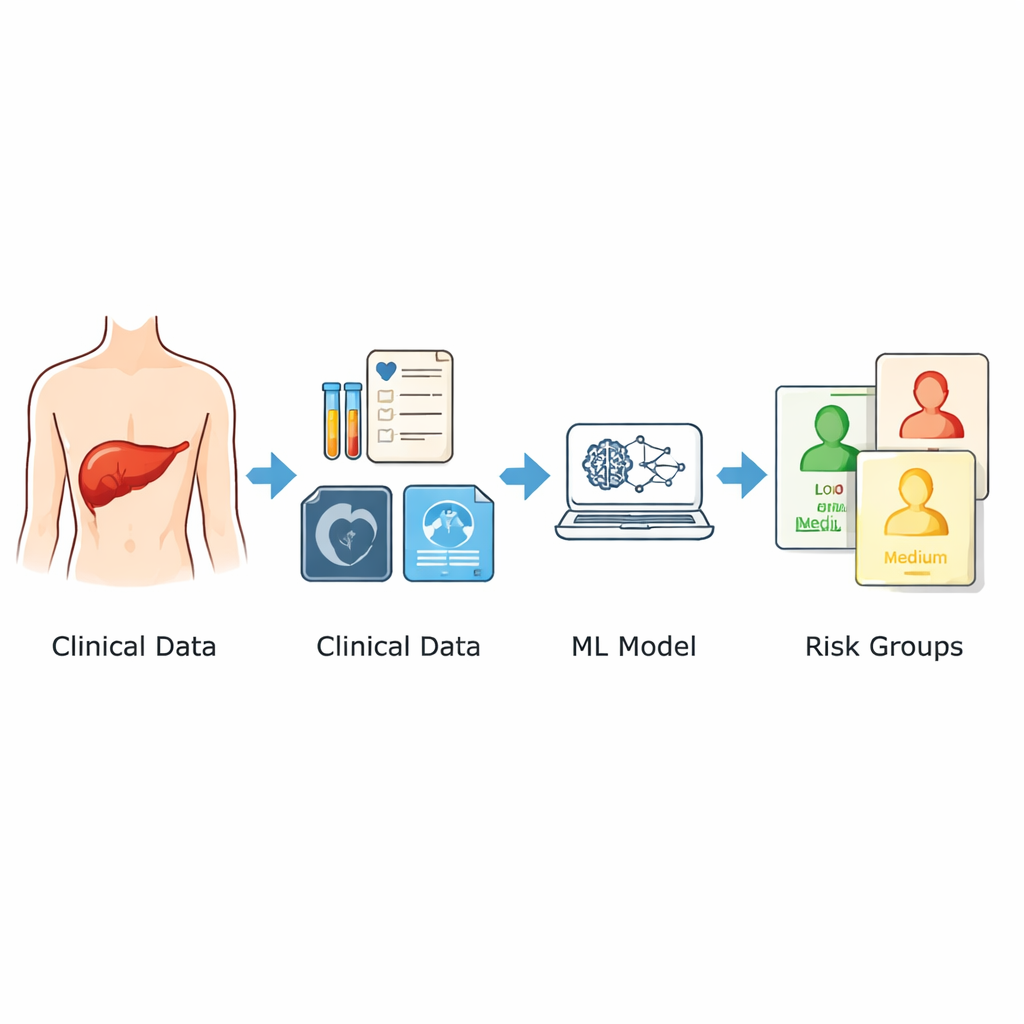
Outperforming standard staging systems
To test how well the model worked, the team first evaluated it in a “hold‑out” set of patients from the original hospital and then in an independent group from the second hospital. In both settings, the new model was clearly better than traditional staging systems at distinguishing who would stay cancer‑free and who would recur within 24 months. In the internal test group, the model’s accuracy over time, measured by a standard statistic called the area under the curve, was about 0.76, compared with roughly 0.55 to 0.64 for common staging methods. People in the high‑risk group had the worst recurrence‑free survival, those in the moderate‑risk group had their hazard of recurrence cut by about 60%, and those in the low‑risk group had about a 90% lower hazard than the high‑risk group. These strong differences held up in the external hospital as well and remained consistent across most subgroups, such as younger and older patients, men and women, and those with large or small tumors.
Opening the black box of artificial intelligence
A frequent criticism of machine learning in medicine is that it behaves like a black box: it may predict well, but even specialists cannot see why. To tackle this, the authors applied a method called SHapley Additive exPlanations, or SHAP, which breaks down each prediction into contributions from each input factor. The analysis showed that tumor size was the single strongest driver of higher risk across all three algorithms, followed by features such as the number of tumors and blood‑based indicators of liver function and inflammation. Interestingly, blood chloride level tended to push the risk in the opposite direction, acting as a protective factor in this dataset. For individual patients, the model can generate simple bar‑style graphics that show, for example, how a large tumor diameter and unfavorable blood markers push the risk score upward, while better liver function pulls it down. 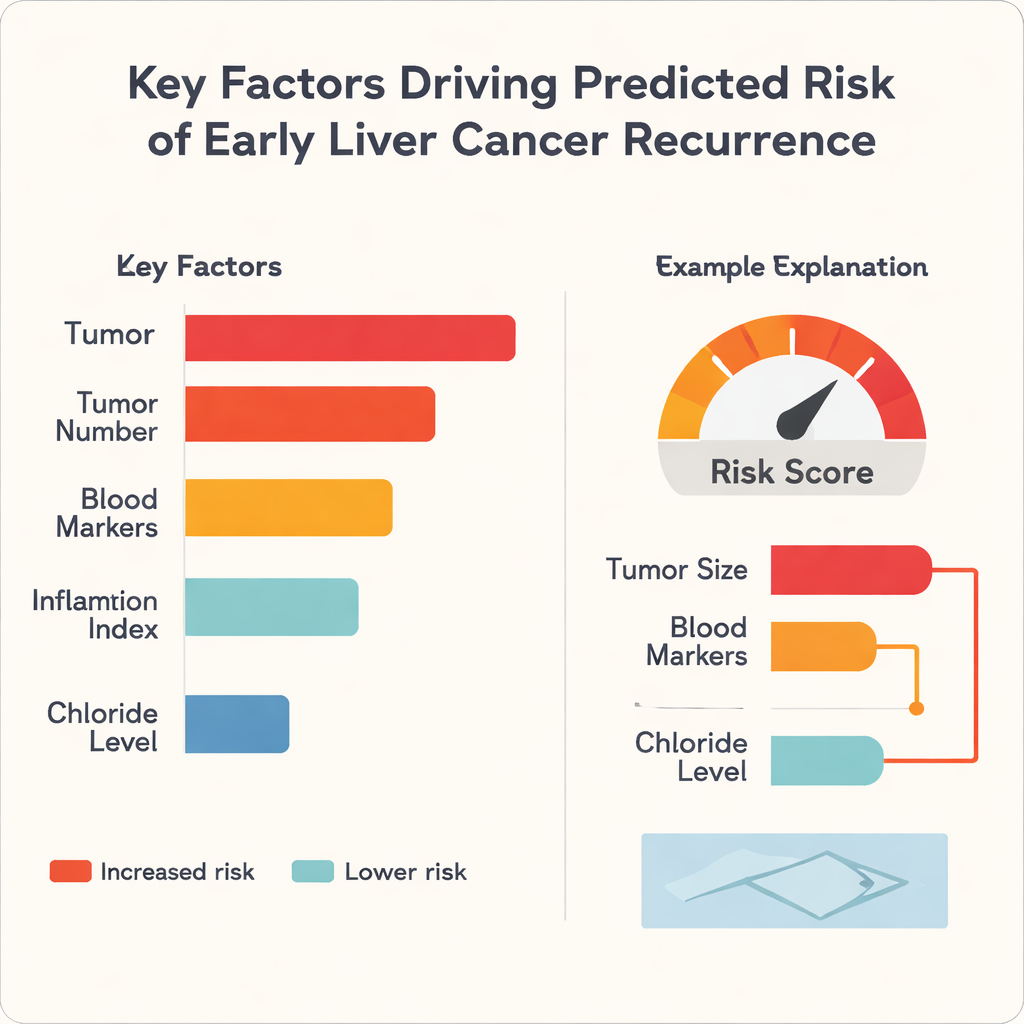
What this could mean in the clinic
Because the model runs on data that hospitals already collect and does not require special scans or expensive genetic tests, it could be deployed in many different care settings, including those with limited resources. Before surgery, doctors could use it to identify people who need more intensive follow‑up schedules or might benefit from added treatments after surgery, while sparing genuinely low‑risk patients from unnecessary tests and anxiety. The authors note that their study is retrospective and drawn from a specific patient population, so prospective trials in more diverse settings are still needed. Nonetheless, their work illustrates how transparent, explainable AI can turn familiar lab numbers and scan findings into meaningful, individualized forecasts that support shared decision‑making between patients and their care teams.
Citation: Guo, DF., Wen, Q., Zhang, X. et al. An interpretable machine learning model using routine clinical data for early recurrence prediction in hepatocellular carcinoma. Sci Rep 16, 7520 (2026). https://doi.org/10.1038/s41598-026-38484-w
Keywords: liver cancer recurrence, machine learning model, clinical risk prediction, interpretable AI, hepatocellular carcinoma