Clear Sky Science · en
An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation
Why tiny sign-language tools matter
Billions of daily conversations depend on hand movements, facial expressions, and body language rather than spoken words. Yet most phones, tablets, and public devices still cannot understand sign languages, especially outside English‑speaking countries. This paper introduces TinyMSLR, a compact and explainable sign-language recognition system designed to run in real time on small, low‑power devices. It aims to turn ordinary hardware into affordable, trustworthy communication aids for Deaf and hard‑of‑hearing people around the world.
Bringing more languages into the conversation
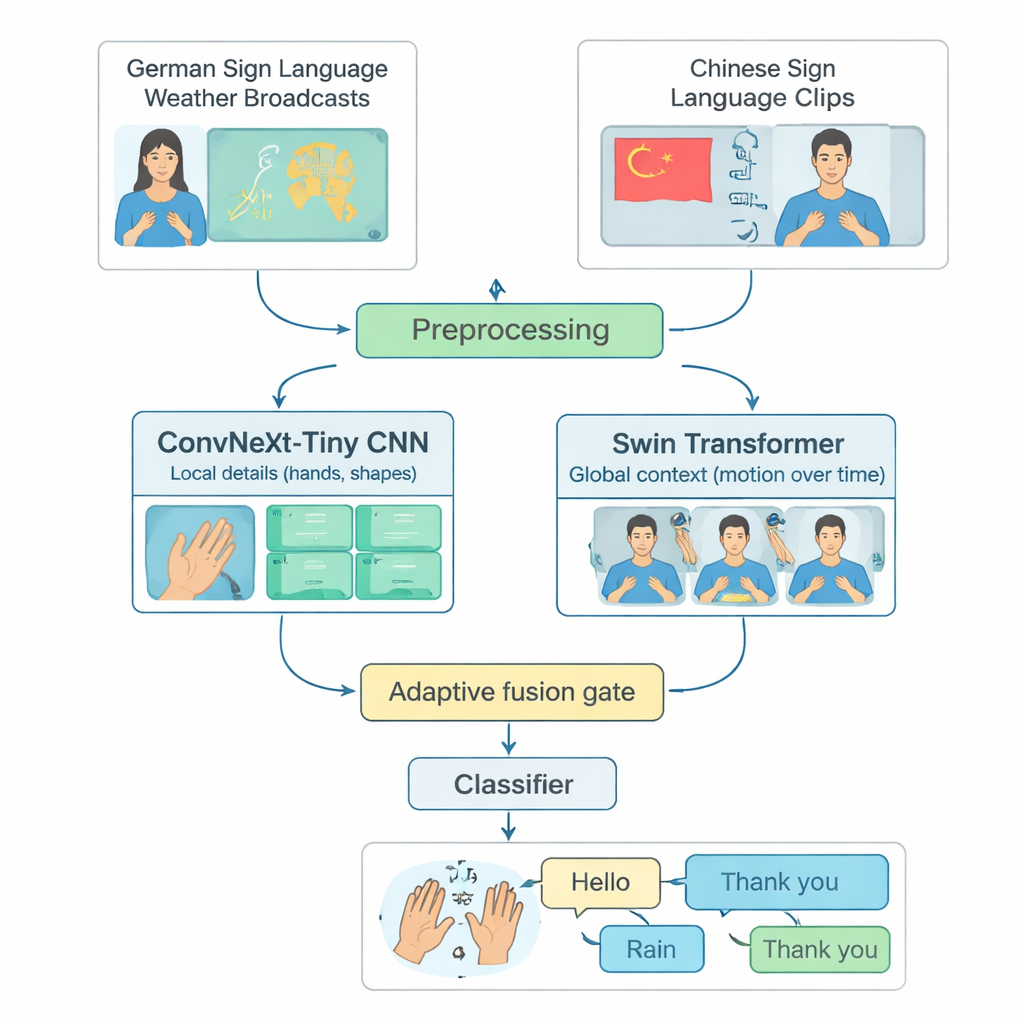
Many advanced sign-language recognition systems focus on a single language, most often American Sign Language, and run only on powerful computers. That leaves out people who use other sign languages or live in regions with limited computing resources. The authors tackle this gap by building a shared testbed from two different languages: German Sign Language weather broadcasts and a large Chinese Sign Language collection. They carefully select 20 common everyday signs—such as Hello, Weather, Rain, Happy, Yes, and Thank you—that exist in both languages. By trimming long videos into short clips containing just one sign, and balancing the number of examples per class and per signer, they create a fair, reproducible way to judge how well a model can recognize isolated signs across languages.
How the hybrid model sees hands and motion
TinyMSLR combines two complementary ways of looking at video. One branch uses a modern convolutional network (ConvNeXt‑Tiny) that excels at spotting fine details, like finger shapes and subtle textures. The second branch uses a Swin Transformer, a newer family of models that shines at tracking patterns across space and time—how hands, face, and upper body move over several frames. Every short video clip is standardized to 32 frames of 224×224 pixels, gently augmented (for example, small rotations or brightness changes), and then fed to both branches in parallel. Each branch produces a 768‑number summary of what it sees; together, these two summaries capture both crisp local details and broader motion and context.
Letting the model decide what matters most
Because some signs are distinguished mainly by handshape while others rely on broader arm movements or facial cues, TinyMSLR does not fix a single recipe for combining its two views. Instead, it uses a small “fusion gate” that learns, for each input clip, how much to trust the detail‑focused branch versus the context‑focused branch. The gate looks at both feature summaries and outputs two weights that always add up to one; the final representation is a weighted blend of the two. During training, each branch also gets its own small classifier so it learns to be useful on its own, and a pair of larger “teacher” networks (one CNN, one Transformer) gently guide the tiny model by showing not just the right label but also which alternative labels look similar. This technique, called knowledge distillation, helps the compact system approach the accuracy of heavier models while keeping its size and speed suitable for edge devices.
Seeing why the system makes each decision
Beyond raw accuracy, the authors emphasize that users and developers should be able to inspect what the model is paying attention to. They adopt SHAP, a family of tools that assigns an importance value to each part of the input. In practice, they compute these explanations on intermediate features and map them back onto frames as heatmaps and temporal plots. This reveals, for example, which frames and regions drive the decision between visually similar signs like Rain and Snow or Cold and Bad. Aggregating many explanations shows broader patterns: non‑manual cues such as facial expression and head movement, as well as wrist orientation and handshape, emerge as especially influential. These insights help verify that the system relies on meaningful aspects of the signing rather than background artifacts.

Speed, frugality, and room to grow
On the 20‑sign bilingual benchmark, TinyMSLR reaches around 99% training and validation accuracy and an F1 score near 99%, while using fewer than 2.7 million parameters and about 1.9 billion operations per clip. On a modern GPU it processes a sign in roughly 13.5 milliseconds and draws under 30 millijoules of energy; the stored model is only about 7.2 megabytes. These numbers suggest that real‑time, on‑device sign recognition is feasible on low‑cost boards and embedded systems. The authors are careful to note that their work covers only short, isolated signs and two languages, and treats facial expressions implicitly rather than as a separate signal. Extending the approach to richer vocabularies, continuous sentences, more languages, and explicit modeling of facial and head movements is left for future work. Still, TinyMSLR offers a compelling proof of concept: accurate, efficient, and interpretable tools for understanding sign languages need not be confined to the cloud—they can live directly on everyday devices.
Citation: Lamaakal, I., Yahyati, C., Maleh, Y. et al. An explainable hybrid CNN–transformer model for sign language recognition on edge devices using adaptive fusion and knowledge distillation. Sci Rep 16, 7143 (2026). https://doi.org/10.1038/s41598-026-38478-8
Keywords: sign language recognition, tiny machine learning, edge AI, explainable AI, multilingual models