Clear Sky Science · en
SAT: shift alignment transformer for video denoising without flow estimation
Sharper videos from noisy scenes
Anyone who has tried to film indoors at night or on a phone with limited light knows the result: grainy, flickering video where details seem to crawl and colors look wrong. This paper presents a new way to clean up such videos, turning them into clearer, more stable sequences without relying on the heavy-duty motion-tracking software that usually makes this possible. The method, called the Shift Alignment Transformer, is designed to keep fine details while still running efficiently enough to be practical.
Why cleaning video is so hard
Removing noise from a single photograph is already a challenge; doing the same for video is even harder. On the one hand, each frame is corrupted by random speckles and color shifts. On the other hand, the frames are linked over time: objects move, the camera shakes, and details appear and disappear. Traditional video denoising methods have leaned on estimating motion between frames, often through a tool called optical flow, which tries to track where each pixel moves from one frame to the next. While powerful, those motion estimates can easily break down when the video is extremely noisy or the motion is fast and complex, and they also add a large computational burden that can slow systems to a crawl.
A new way to align without tracking
Instead of explicitly trying to follow every pixel, the Shift Alignment Transformer (SAT) takes a different route: it lets the network implicitly discover how frames are related by carefully shifting and comparing features. The model is built around a modern architecture known as a Transformer, which excels at finding long-range connections in data. Within this framework, the authors introduce a Spatial-Temporal Shift Module that gently shuffles information across both time and space. In time, the model cyclically shifts frame features so that, layer by layer, each frame can “see” farther into the past and future. In space, it splits features into many small groups and nudges each group in different directions. This combination effectively mimics how objects might move across the video, allowing the network to align information from different frames without ever computing an explicit motion field.
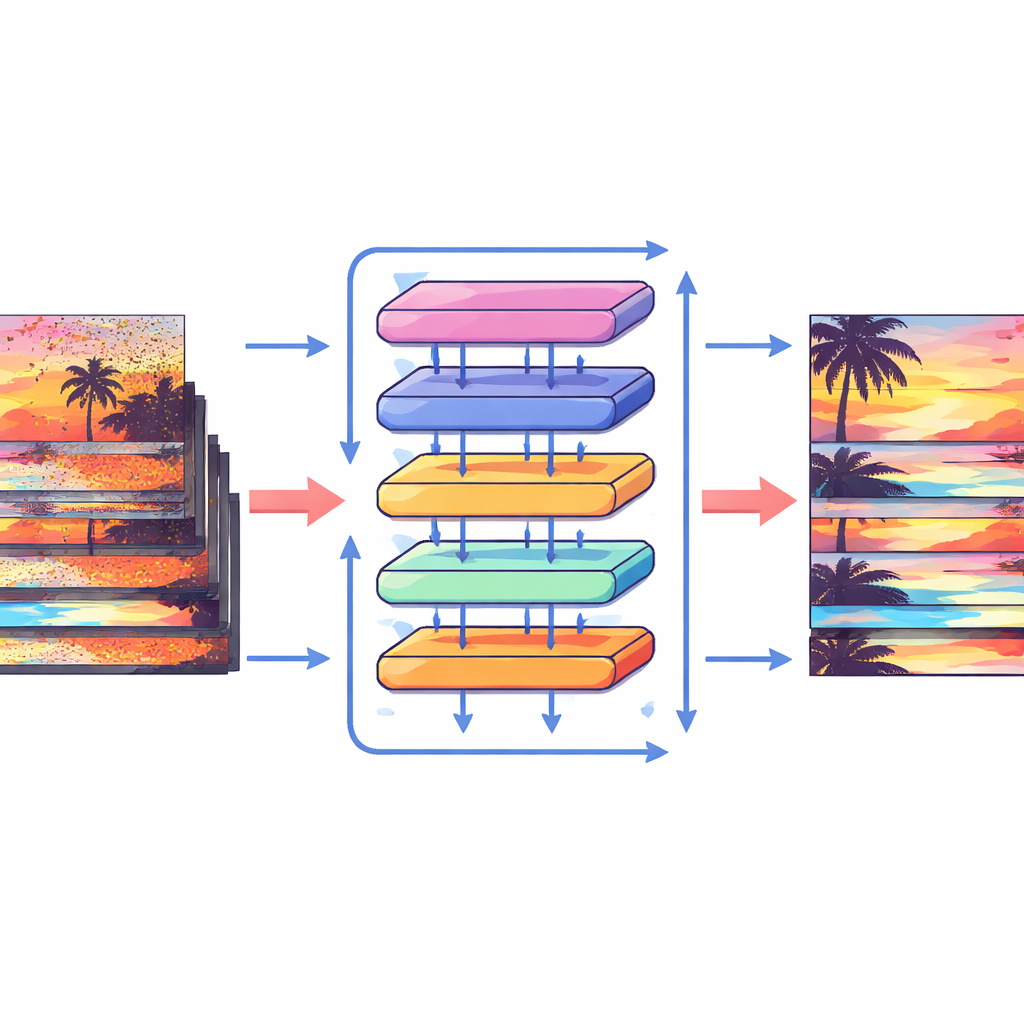
How the new building blocks work
To make the most of these shifts, the authors design a special attention block that mixes information within and across frames. First, the shifted features from neighboring frames are brought together and compared through a cross-attention operation: the model learns which regions in other frames best support the current frame at each location. At the same time, a separate attention operation focuses on relationships within each single frame, reinforcing local structure and texture. These two streams are then merged and passed through simple processing layers in a multi-scale U-shaped network, which goes from coarse to fine resolution and back. This layout lets the system handle both large camera motions and tiny details such as thin edges or small patterns, gradually reconstructing a clean version of every frame.
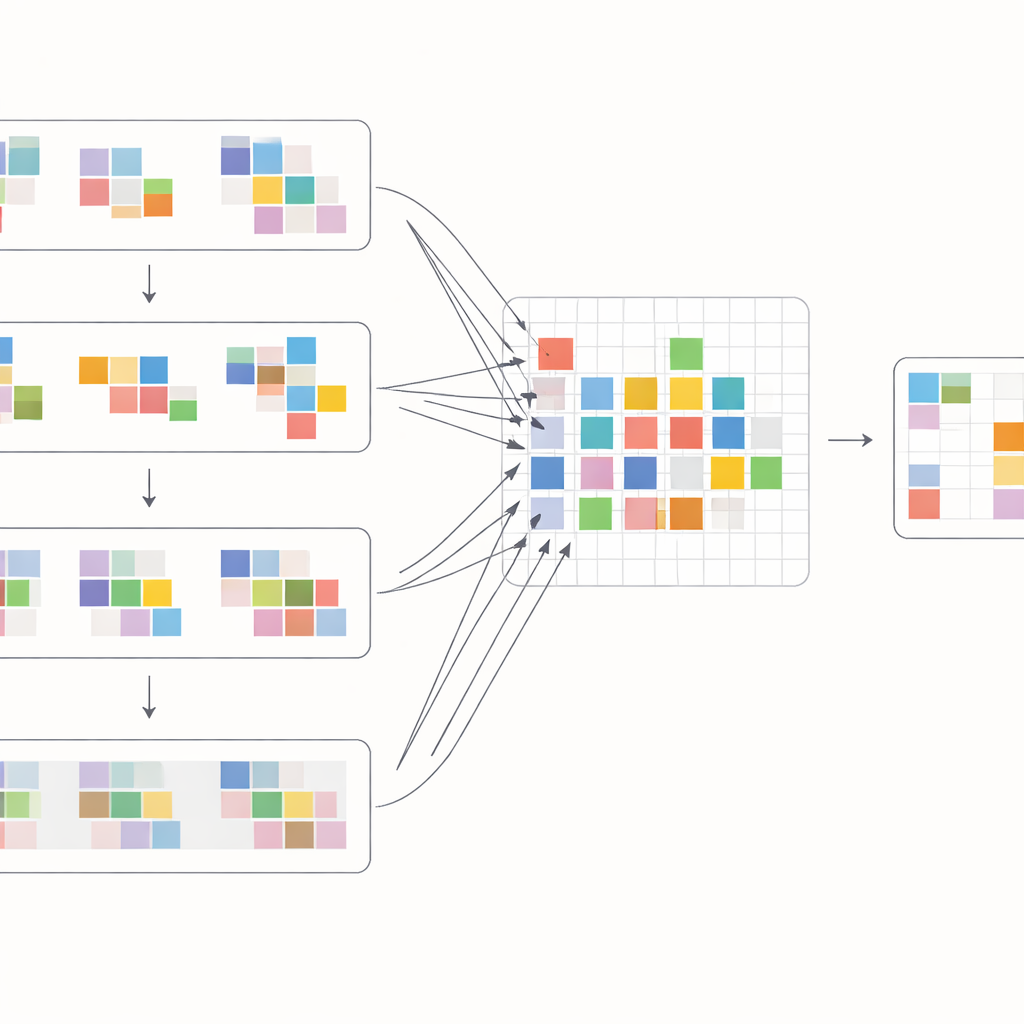
How well it works in practice
The researchers test their approach on two demanding benchmarks. The first involves clean videos that have been artificially corrupted with different levels of random noise, letting them precisely measure how closely the restored frames match the originals. Here, the new method consistently matches or exceeds the quality of earlier convolutional and recurrent networks, and comes close to the best existing Transformer-based models while using less computation. The second benchmark uses real footage captured from image sensors in low light, where noise is uneven, colored, and far less predictable. On this more realistic test, the Shift Alignment Transformer decisively outperforms previous state-of-the-art methods, producing videos that look cleaner, sharper, and more stable over time, with fewer color shifts and fewer remaining artifacts.
What this means for future video tools
In simple terms, the authors show that it is possible to denoise videos effectively without explicitly tracking motion, by combining smart shifts in time and space with attention-based feature matching. Their Shift Alignment Transformer offers a strong balance between accuracy and efficiency, especially for real-world low-light footage, where traditional motion estimation is fragile. As attention-based models become more efficient, methods like this could make their way into everyday cameras and streaming services, helping turn noisy, hard-to-watch clips into smooth, sharp videos with minimal fuss for the user.
Citation: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
Keywords: video denoising, transformer, image noise, low light video, computer vision