Clear Sky Science · en
MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection
Sharper Eyes in the Sky
From traffic monitoring to disaster response, drones and satellites increasingly watch over our world. Yet the very things we care about most in these images—tiny cars, people, boats, and aircraft—often appear as just a handful of pixels. The paper on MDI‑YOLO tackles a simple but crucial question: how can computers reliably spot these tiny objects in real time, even on low‑power devices carried by drones themselves?
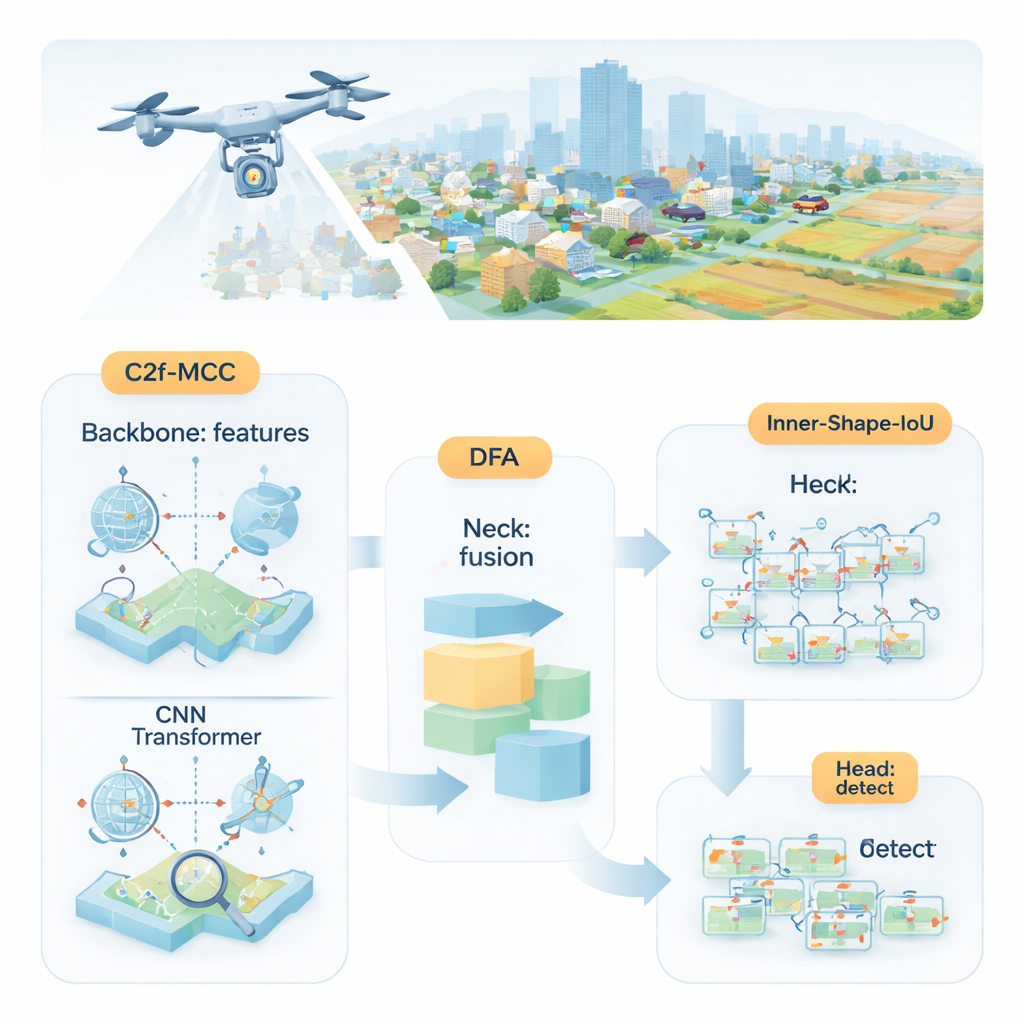
Why Small Objects Are Hard to Spot
In aerial and satellite views, objects of interest are usually very small, often crowded together, and partly hidden by buildings, trees, or shadows. Standard detection systems face a trade‑off: lightweight models run fast on edge devices like onboard drone computers but miss many small targets; heavier, more accurate models are too slow and resource‑hungry to be practical in the field. Small objects also tend to blend into complex backgrounds—think gray cars on gray roads—so their distinctive features can easily vanish as images are compressed and processed by deep networks.
A New Blend of Global and Local Vision
The researchers propose MDI‑YOLO, a redesigned version of the popular YOLOv8 detector that keeps the model compact while sharpening its ability to find tiny targets. At its core is a new building block called C2f‑MCC, which splits the visual information flowing through the network into two paths. One path uses Transformer‑style processing, which is good at capturing long‑range relationships across the entire image—such as how a cluster of pixels fits into a larger road or runway. The other path sticks with classic convolutional filters, which excel at picking out local details like edges and textures. By grouping channels and sending only part of the data through the heavier Transformer path, the model gains global awareness without ballooning in size or slowing down.
Helping the Network Focus on What Matters
Even with better building blocks, the network still needs to decide where to pay attention. To guide this, the authors introduce a mechanism they call Directional Fusion Attention (DFA). This module looks at patterns along the width and height of the image, as well as an overall summary of the scene, and learns how to weight different regions and feature channels. In practice, DFA encourages the model to concentrate on likely object areas—such as vehicle‑shaped blobs on roads—and to downplay repetitive or confusing background textures. This combined spatial and channel focus makes it easier to separate tiny targets from cluttered surroundings or similar‑looking background regions.
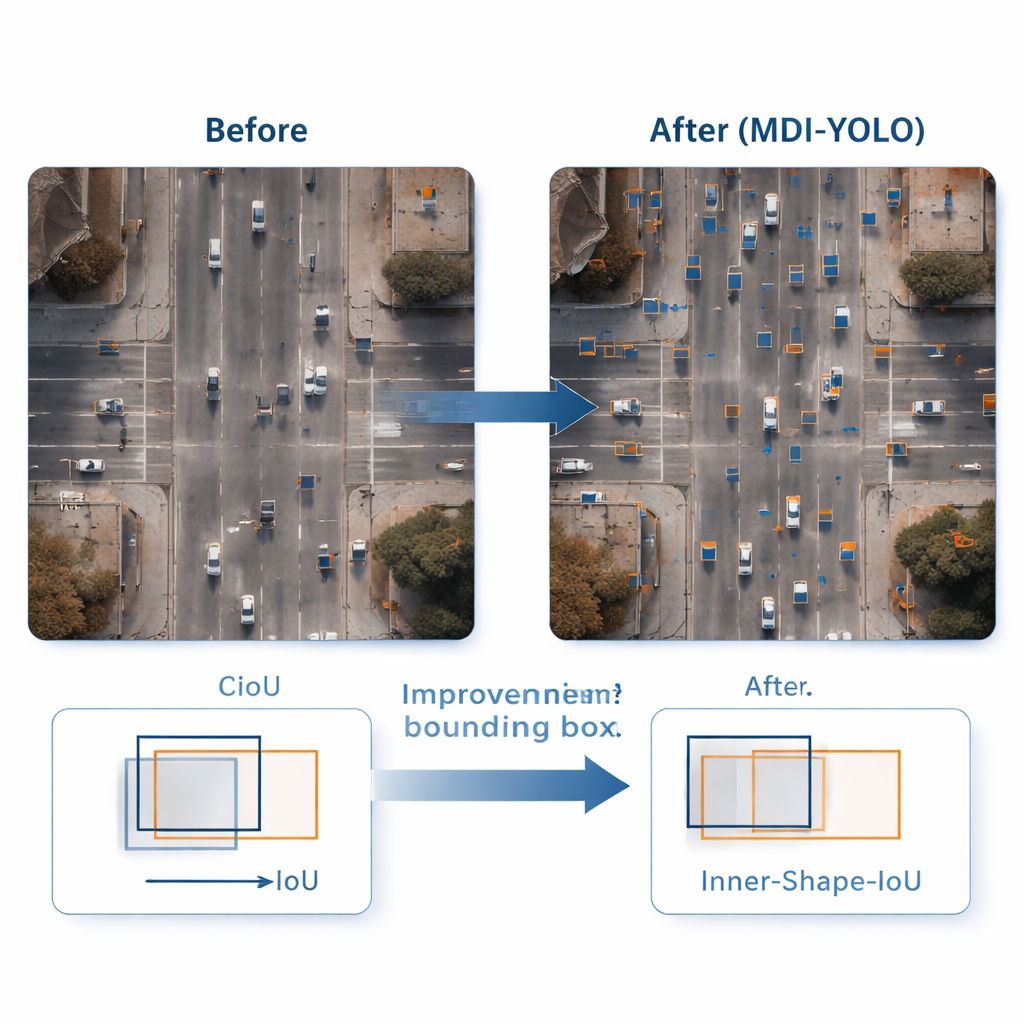
Drawing Tighter Boxes Around Tiny Targets
Spotting an object is only half the job; the detector also needs to outline it accurately. Standard training methods compare predicted rectangles with the true ones using an "overlap" score, but this can be insensitive when objects are small or oddly shaped. The authors design a new loss function, Inner‑Shape‑IoU, that judges boxes not just by how much they overlap, but also by how well their shape, size, and central region line up with the real object. By combining two complementary measures, it penalizes boxes that match only the edges while missing the core of the target, leading to more precise outlines—especially for small, crowded, or elongated objects.
Proven Gains Without Extra Bulk
To test MDI‑YOLO, the team ran experiments on two challenging public benchmarks: VisDrone2019, featuring drone footage of cities and traffic, and DOTAv1.0, a large collection of aerial scenes with many small, densely packed objects. Without relying on pre‑trained models, MDI‑YOLO improved standard accuracy scores by several percentage points over the baseline YOLOv8 while keeping the number of parameters almost unchanged and maintaining fast inference times. Compared with a range of popular detectors—from lightweight YOLO variants to heavier Transformer‑based systems—it offered a rare combination of high accuracy, low computational cost, and robustness across different scenes.
What This Means for Real‑World Use
For non‑specialists, the takeaway is that MDI‑YOLO gives drones and remote sensing systems sharper, more reliable "eyes" without demanding big, power‑hungry computers. By smartly mixing global context, local detail, targeted attention, and a more discerning way of training bounding boxes, the method makes it easier to detect tiny objects that matter for safety, monitoring, and mapping. This kind of efficient, high‑precision vision is a key step toward smarter aerial platforms that can operate autonomously, respond quickly, and be deployed widely in the real world.
Citation: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
Keywords: drone imaging, small object detection, remote sensing, YOLO, computer vision