Clear Sky Science · en
DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios
Smarter Data Highways for the Internet of Things
As cities, factories, and homes fill with connected sensors and devices, they generate torrents of data that must be processed quickly and reliably. Sending everything to distant cloud servers can be too slow, while tiny devices at the "edge" often lack enough computing power. This paper explores a new way to automatically route and allocate computing, storage, and network resources across devices, nearby edge servers, and the cloud—so that smart applications stay fast and robust even when real-world conditions are messy and unpredictable.
Why Today’s Methods Struggle
Modern systems often rely on deep reinforcement learning, where an algorithm learns by trial and error using reward signals from the environment. In complex, noisy networks, however, those rewards are hard to define and measure. If the reward function is wrong or distorted by interference, the system may learn unsafe or wasteful behavior. Many existing methods also assume rich prior knowledge about traffic patterns and device behavior, which is rarely available in live industrial networks. On top of that, most solutions optimize only one type of resource at a time—such as computing power—while ignoring storage or network bandwidth, even though all three work together to determine real-world performance.
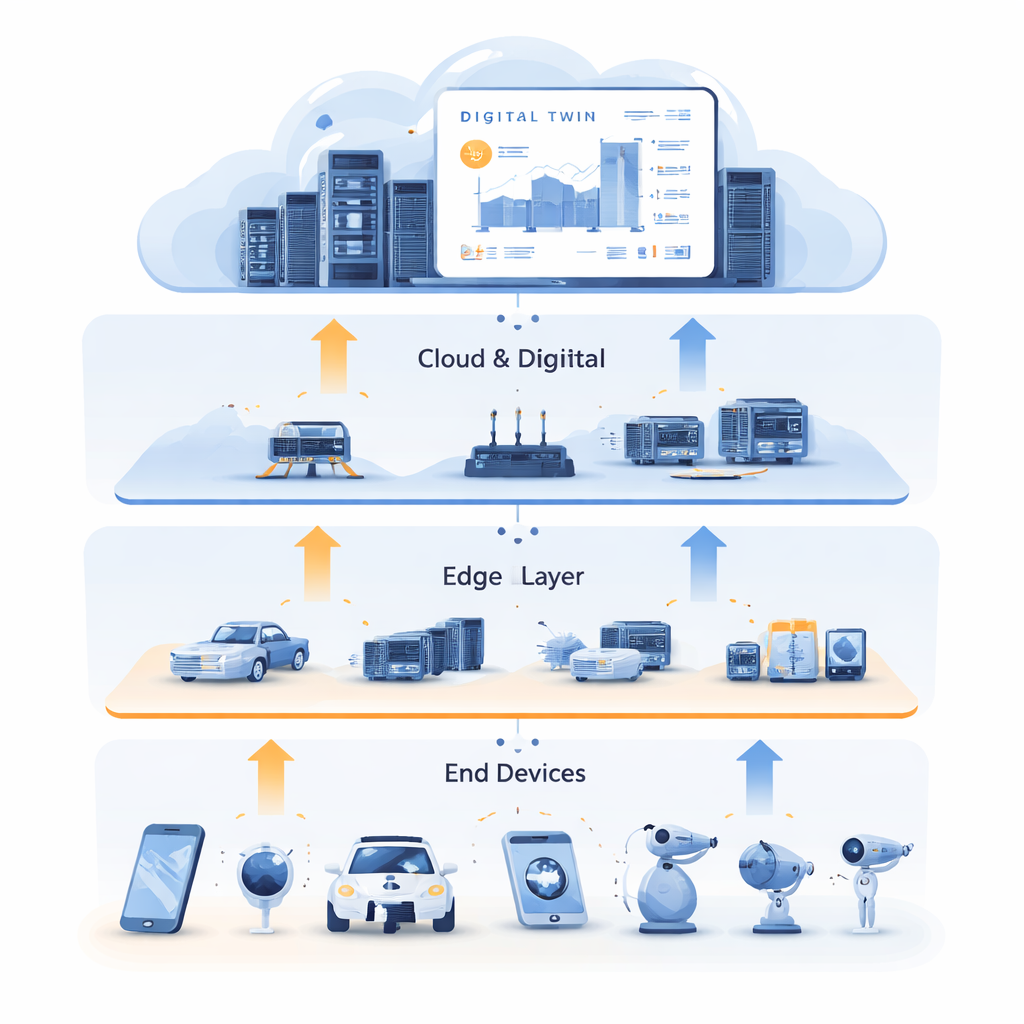
Learning from a Digital Double
To break this deadlock, the authors combine resource allocation with Digital Twin technology. A Digital Twin is a detailed virtual replica of the physical network, maintained in the cloud. It mirrors the state of edge servers, links, and tasks over time, using rich historical data from sensors and logs. In this work, the Digital Twin is not just a dashboard; it becomes a training ground. The system uses past data to generate “expert” examples of good decisions, capturing how tasks should be split between computing and caching, and where they should be processed for low delay. This training happens offline, without disturbing live services, and leverages the cloud’s abundant computation to explore many possible situations.
Imitation Instead of Trial and Error
Rather than learn directly from rewards, the proposed E‑GAIL model adopts imitation learning: the agent tries to behave like an expert. First, the authors build multiple expert policies using an Actor–Critic framework enhanced with a NoisyNet layer. Injecting carefully controlled noise into the decision network allows these experts to experience a wide variety of conditions—including disturbances that mimic real wireless interference and fluctuating workloads—so that their trajectories are more realistic. Next, the system fuses several single-expert trajectories into a single "multi-expert" reference using tools from game theory. By seeking a Nash equilibrium among the experts, it avoids conflicts between them and produces a consensus strategy with wider coverage of possible scenarios.
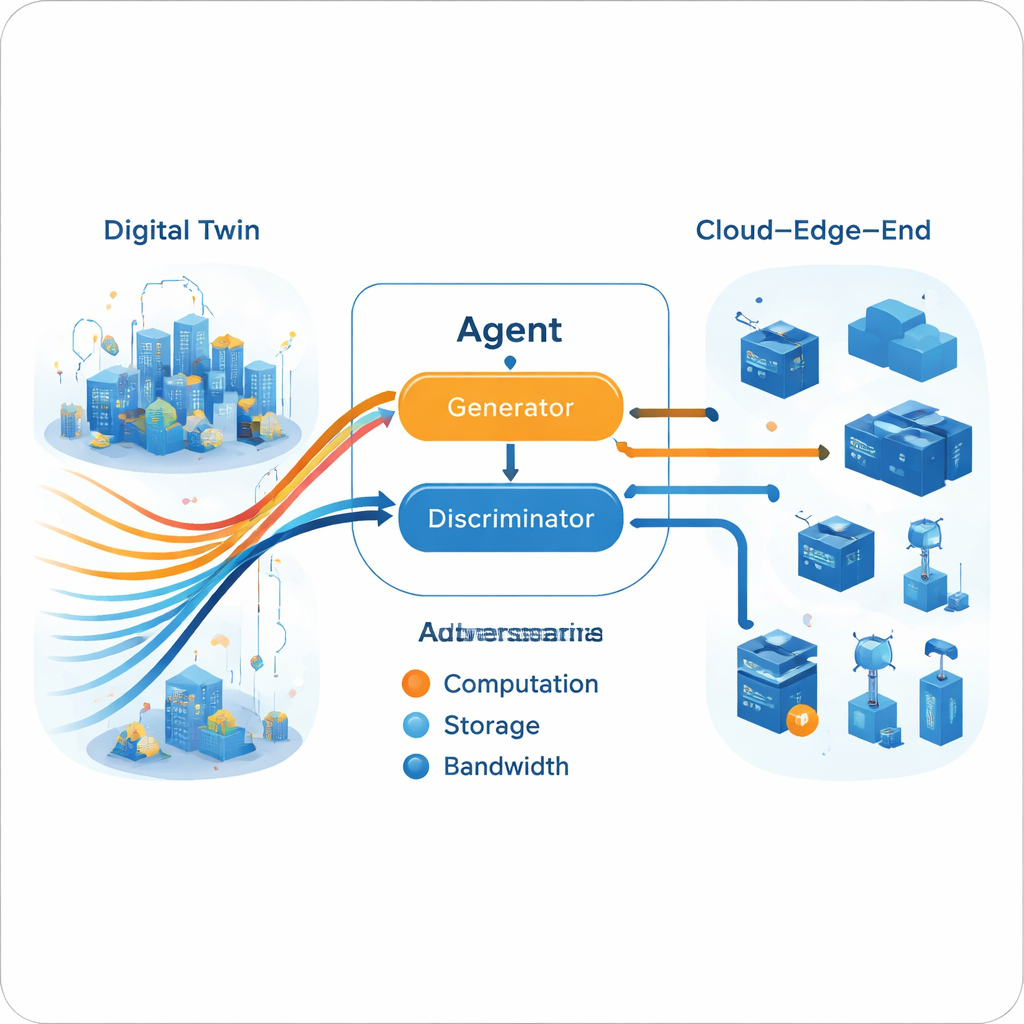
A Generative Adversarial Engine for Decisions
Once the multi-expert trajectory is built in the Digital Twin, the live agent learns to mimic it using a generative adversarial setup, similar in spirit to image-generating neural networks. A generator proposes resource allocation actions given the current network state, while a discriminator tries to tell whether a sequence of actions comes from the agent or from the expert trajectories. Over time, this adversarial game pushes the generator to produce decisions that the discriminator cannot distinguish from expert behavior. Crucially, this process does not require an explicit reward function from the real environment. The training is split: heavy offline learning (in the cloud) refines experts and generator, while lighter online updates (at the edge) keep the model aligned with current conditions, meeting the practical limits of edge hardware.
How Well Does It Work?
The authors test E‑GAIL against several popular baselines, including deep Q‑learning, game-theoretic offloading, greedy heuristics, cloud-only processing, and random allocation. Across many experiments—varying the number of end devices, channels, task mixes, workloads, data sizes, distances, and noise patterns—E‑GAIL consistently achieves end‑to‑end delays very close to those of the expert policy and noticeably better than other automated methods. It adapts well when tasks shift between computing-heavy and storage-heavy, when the network grows larger, or when interference intensifies. The Digital Twin speeds up generation of expert trajectories and improves their quality, while the multi-expert fusion broadens the scenarios the agent can handle without retraining from scratch.
What This Means for Everyday Systems
For a non-specialist, the key message is that this approach lets networks manage themselves more intelligently in the face of uncertainty. Instead of hand-crafting rules or relying on fragile trial-and-error learning, E‑GAIL learns from rich, simulated experience supplied by a Digital Twin and from multiple seasoned “experts” whose advice is reconciled mathematically. The result is a resource allocator that can quickly decide where to run tasks and where to store data, keeping response times low even as conditions change. In future industrial and smart-city systems, such self-taught coordinators could quietly juggle computing, storage, and bandwidth behind the scenes, making our connected world faster, more reliable, and more energy-efficient.
Citation: Zhang, X., Xin, M., Li, Y. et al. DT-aided resource allocation via generative adversarial imitation learning in complex cloud-edge-end scenarios. Sci Rep 16, 7657 (2026). https://doi.org/10.1038/s41598-026-38367-0
Keywords: digital twin, edge computing, imitation learning, resource allocation, Industrial Internet of Things