Clear Sky Science · en
A multi-scale end-to-end visible and infrared image enhancement fusion method
Sharper Night Vision for People and Machines
Anyone who has tried to take a photo at night knows how quickly darkness ruins detail: scenes look grainy, blurry, and full of strange colors. Yet many critical technologies—from roadside cameras and home security to self-driving cars and rescue drones—must see clearly in exactly these conditions. This paper presents a new way to combine ordinary color cameras with infrared “heat” cameras so that computers, and ultimately people, can get bright, detailed views of the world even in near-total darkness.
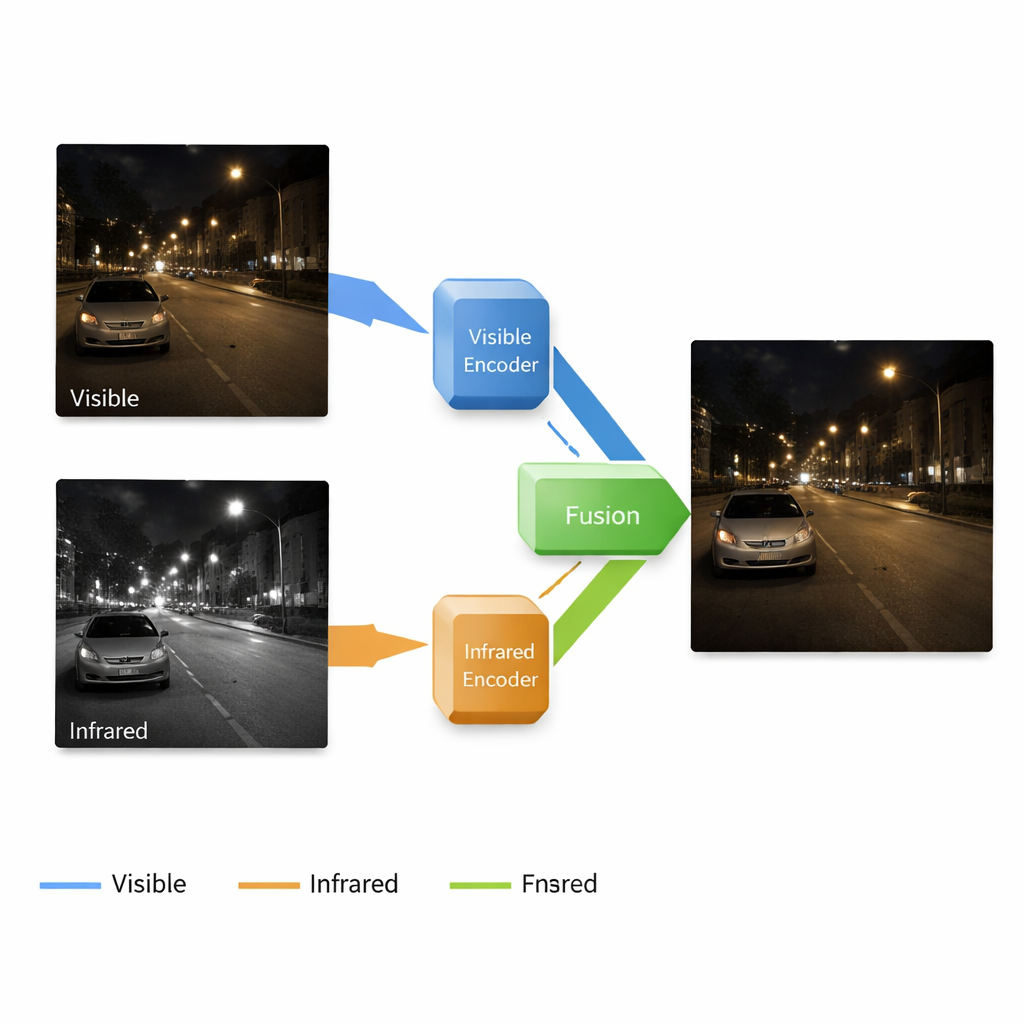
Why Two Kinds of Cameras Are Better Than One
Standard cameras capture the same kind of light our eyes see, which makes their pictures easy for humans to interpret, but they fail badly when light is scarce: shadows swallow detail, noise appears, and colors shift. Infrared cameras do the opposite: they sense heat patterns, revealing people, animals, and vehicles in the dark or through light fog, but their pictures lack fine textures and natural appearance. Researchers have long tried to fuse these two views into a single image that looks like a clear color photo yet still reveals hidden warm objects. Existing methods, however, often treat each step—brightening dark images, cleaning up noise, and merging infrared information—as separate tasks. That piecemeal approach can cause mismatched features and disappointing fusion results.
A Single Pipeline That Both Brightens and Fuses
The authors propose an end-to-end system that enhances and fuses images in one continuous pipeline. It is built around a neural network with four main parts: one branch learns to clean and brighten low-light color images, another learns to represent the scene from the infrared camera, a fusion block combines what each branch has learned, and a decoder reconstructs a final picture from these mixed signals. Importantly, the system works at multiple scales, from coarse shapes down to fine textures. Shallow layers preserve edges and surface details like bricks or road markings, while deeper layers capture broader structures—buildings, cars, or trees—and the location of warm targets in the infrared image.
Three Learning Phases Instead of One Big Jump
Rather than training the whole system all at once, the team uses a three-stage learning strategy designed for stability and accuracy. In the first stage, the network sees only dark visible-light photos and learns to brighten them without any human-provided “perfect” reference images. Carefully chosen loss terms nudge the output to have natural brightness, stable colors, smooth regions without blotchy noise, and preserved texture. In the second stage, the same decoder is reused while a new infrared branch learns to faithfully reconstruct infrared images, teaching the network how heat patterns should look. In the third stage, all those learned pieces are frozen, and only the fusion block is trained to blend the two representations into a single, high-quality image that is both bright and information-rich.
Putting the Method to the Test
The researchers evaluated their approach on public datasets containing paired visible and infrared images taken under difficult lighting, such as nighttime streets. They compared against several leading fusion techniques, including those based on classic image transforms, standard convolutional networks, and more complex generative models. Their method generally delivered sharper details, more even brightness, and clearer thermal targets, while also scoring higher on quantitative measures of information content, edge sharpness, structural similarity, and contrast. Additional experiments, in which they selectively removed key components of the system, showed that each part—the multi-scale fusion block, staged training, and adaptive weighting of visible versus infrared features—contributes measurably to the final quality.
What This Means for Real-World Vision Systems
For non-specialists, the bottom line is straightforward: this work shows that a single carefully trained network can both brighten dark scenes and intelligently merge heat and color views into one coherent image. The fused pictures preserve fine textures while still highlighting warm objects, making them far more useful for tasks like night surveillance, driving assistance, and augmented or virtual reality in dim environments. Although the authors note some remaining issues—such as reduced contrast in very bright regions and the need for faster, lighter models—their approach marks a significant step toward camera systems that see reliably in the dark, in a way that feels natural and interpretable to human users.
Citation: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
Keywords: low-light image enhancement, infrared image fusion, night vision, multisensor imaging, deep learning vision