Clear Sky Science · en
Pruning tree forest and re-sampling for class imbalanced problem
Why rare cases matter in smart predictions
Many decisions powered by artificial intelligence hinge on spotting the rare event: a fraudulent credit card charge, an early sign of disease, or a dangerous fault in a machine. In these situations, the important cases are greatly outnumbered by ordinary ones, and most learning algorithms tend to ignore them. This article presents a way to make one popular method, Random Forests, much more attentive to those rare but crucial cases—while also making the model leaner and faster.
The problem of uneven examples
Standard machine learning works best when data are well balanced—when there are roughly similar numbers of examples for each outcome. In real life, however, rare events dominate many tasks. For instance, only a small fraction of medical scans show a tumor, and only a tiny share of transactions are fraudulent. This imbalance makes it easy for an algorithm to look good on paper by mostly predicting the common outcome, even if it repeatedly misses the rare one. As the gap between common and rare cases grows, the model’s decision boundary drifts toward the majority, and the rare class becomes harder to recognize.
Balancing the scales with smart sampling
Researchers often try to rebalance such data before training models. One option is to trim the majority class (under-sampling), discarding some common cases to match the number of rare ones. Another is to copy or generate extra rare examples (over-sampling), increasing their presence without losing any original data. A third, hybrid approach mixes both ideas, cutting some majority examples while boosting the minority. Each tactic has trade-offs: trimming risks throwing away useful information, while duplicating many examples can make training slower and can cause overfitting. The authors make use of all three strategies to create more even training sets tailored to the data at hand.
Teaching and trimming a forest of decision trees
The study focuses on Random Forests, an ensemble method that builds many decision trees on slightly different slices of the data and then combines their votes. Random Forests are known for handling complex data and highlighting which features matter most. Yet when trained on strongly imbalanced data, even large forests can still be biased toward the majority class. In the proposed method, the authors first rebalance the data using under-sampling, over-sampling, or their hybrid. They then grow many trees using the usual Random Forest procedure, but with an important twist: instead of keeping every tree, they evaluate each one using out-of-bag observations—data points that were not used to grow that particular tree—and discard the half with the worst error rates. This pruning step yields a smaller, more selective forest built from the most reliable trees.
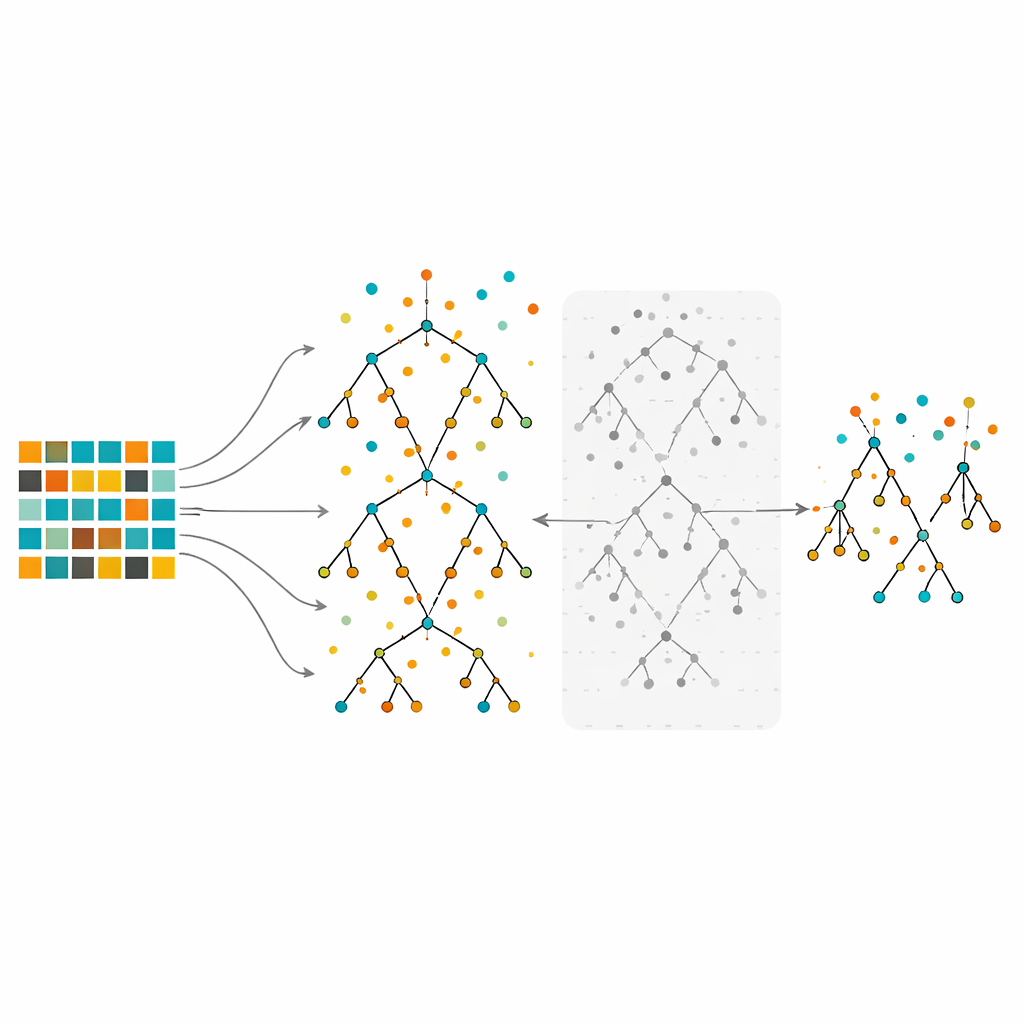
Testing on many real-world datasets
To see how well this pruned forest performs, the authors test it on ten publicly available datasets that reflect a wide range of applications, from medical and biological measurements to email spam filtering and sound classification. Each dataset has two classes, with one clearly rarer than the other, and they vary in size, number of features, and degree of imbalance. The new method is compared with several widely used approaches: k-nearest neighbors, a single decision tree, a standard Random Forest, a Balanced Random Forest variant, and support vector machines. Across different sampling strategies, the pruned forest consistently achieves lower classification error than the alternatives on most datasets. The hybrid sampling plus pruning combination gives the best overall results, both in terms of accuracy and in stable performance across all ten tasks.
Sharper models that waste less effort
Beyond accuracy, the approach also improves efficiency. By cutting away the less effective trees, the final ensemble is smaller and requires less computation to train and to make predictions, without sacrificing—and often improving—its ability to detect rare cases. Statistical tests confirm that the gains over competing methods are not due to chance. For practitioners facing imbalanced data, this work shows that carefully balancing the training set and then pruning a Random Forest based on out-of-bag performance can yield models that are both more accurate and more efficient. In everyday terms, the method helps our algorithms pay proper attention to the rare but important signals hiding in a sea of ordinary examples.
Citation: Faiz, N., Iftikhar, S., Jan, S. et al. Pruning tree forest and re-sampling for class imbalanced problem. Sci Rep 16, 8087 (2026). https://doi.org/10.1038/s41598-026-38320-1
Keywords: class imbalance, random forest, resampling, machine learning, ensemble methods