Clear Sky Science · en
Automatic classification method of e-commerce commodity raw materials through the introduction of self-supervised concepts and the construction of domain ontology
Why sorting online goods by ingredients matters
When you buy flour or snacks online, you usually search by what the product does—cake mix, bread flour, baking ingredients. But companies, regulators, and even health‑conscious shoppers often care more about what those products are made of. Today’s e‑commerce sites rarely organize goods by their raw materials, and fixing that by hand would mean checking millions of product pages one by one. This study proposes an automatic way to regroup online products by their underlying ingredients, using a mix of expert knowledge and machine learning.
The problem of mixed‑up product shelves
Large e‑commerce platforms list millions of items and typically arrange them by function: "baking mix" or "snack," rather than wheat, buckwheat, or corn. As a result, two flours made from the same grain can end up in different categories, while products with different ingredients may be placed together because they are used for similar purposes. This is convenient for shoppers but a headache for merchants and analysts who want to track sales or quality by raw material. Existing automatic classification methods mostly copy the platform’s own labels and require many manually tagged examples, which is expensive and still does not solve the ingredient‑based view that businesses need.
Building a smart map of product ingredients
The researchers tackled this by first asking domain experts to design a structured "map" of the flour world, called a domain ontology. In plain terms, this is a careful list of flour types—such as wheat, whole wheat, corn, buckwheat, rice, and glutinous rice—and the key traits that distinguish them, including raw grain, gluten strength, quality grade, brand, and place of origin. From real product pages on several Chinese platforms, the team then harvested thousands of concrete phrases that match those traits, such as brand names or typical wording for origin. They relied on pattern‑matching rules and a distance measure between strings to catch near‑miss spellings and synonyms, like slightly different names for the same type of flour, and folded them into a domain‑specific word list.
Letting the data label itself
Next, the authors adapted the idea of self‑supervised learning: instead of asking humans to tag every sample, they let the data create many of its own labels. Using their ontology and word list, they wrote rules that say how ingredient attributes should line up with a category. If a product’s details clearly mention corn as the main grain and other traits match the corn‑flour profile, the system treats that listing as a "standard" example of corn flour and automatically accepts its category label. Listings whose attributes clash with the expert rules, or that are too vague, are treated as "non‑standard" and kept aside as unlabeled cases. In this way, the model harvests thousands of clean training examples directly from messy catalog data without manual inspection.
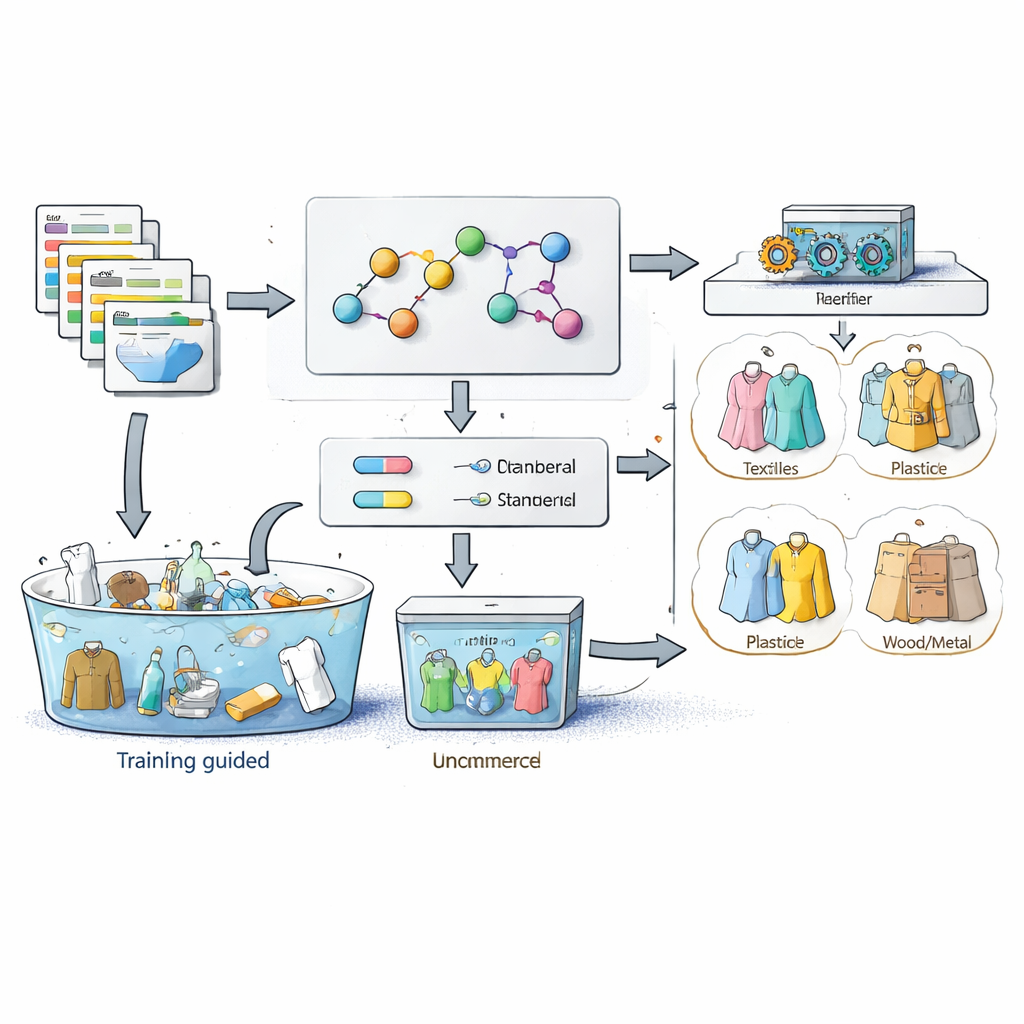
Teaching the classifier to recognize raw materials
With the standard examples in hand, the system turns each product’s text into machine‑readable features. It uses a powerful language model, originally developed for Chinese text, to pull out important entities such as brands, ingredient names, and places of origin, and adds these to the domain word list. A tokenizer then breaks product titles and descriptions into meaningful chunks, removes common filler words, and builds a numerical profile of how distinctive each term is across the dataset. Classic machine‑learning classifiers are trained on these profiles and the automatically assigned ingredient categories. The authors tested several algorithms on more than 18,000 flour listings and found that a logistic regression model, a relatively simple method, delivered the best balance of speed and accuracy.
How well the system works—and why it beats general AI
On flour data collected from major Chinese platforms, the ingredient‑based classifier achieved about 91 percent accuracy overall. It was particularly strong at recognizing common flours, such as standard wheat and glutinous rice flour, and still performed reasonably well on trickier categories like buckwheat and corn, where products often blend grains. Adding the domain‑specific word list clearly improved results compared with using only off‑the‑shelf text features. The team also compared their method with a large general‑purpose language model asked to do the same task without prior training on the dataset. That zero‑shot model lagged behind, especially on rarer flour types, underscoring the advantage of combining expert knowledge with targeted machine learning rather than relying solely on broad but shallow language understanding.
What this means for online shopping and beyond
In simple terms, the study shows that e‑commerce platforms can automatically regroup items by what they are made of, not just what they are used for. By encoding expert knowledge about ingredients into a reusable map and letting product pages label themselves, the approach sharply cuts the need for manual tagging while maintaining high accuracy. For merchants and analysts, this opens the door to cleaner sales statistics, better quality control, and more precise responses to issues like allergen tracking or nutrition trends. Although demonstrated on flour, the recipe—expert‑built ontologies plus self‑labeling rules and lightweight classifiers—could be adapted to many other product categories wherever the raw materials truly matter.
Citation: Lei, B., Wang, J. & Shen, C. Automatic classification method of e-commerce commodity raw materials through the introduction of self-supervised concepts and the construction of domain ontology. Sci Rep 16, 8058 (2026). https://doi.org/10.1038/s41598-026-38214-2
Keywords: e-commerce classification, product ingredients, self-supervised learning, domain ontology, text mining