Clear Sky Science · en
A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion
Sharper Night Vision for a Noisy World
Modern cameras can see in the dark, feel heat, and watch the road for us—but their pictures are often far from perfect. Streetlights flare, shadows swallow details, and sensors add speckled noise. This study presents a new way to merge ordinary color video with heat-sensing infrared images so that the final view is clearer and more reliable, even when both inputs are badly degraded. The method could make autonomous cars, surveillance systems, and other smart cameras more dependable in the conditions where we need them most: at night, in bad weather, and in cluttered real-world scenes.
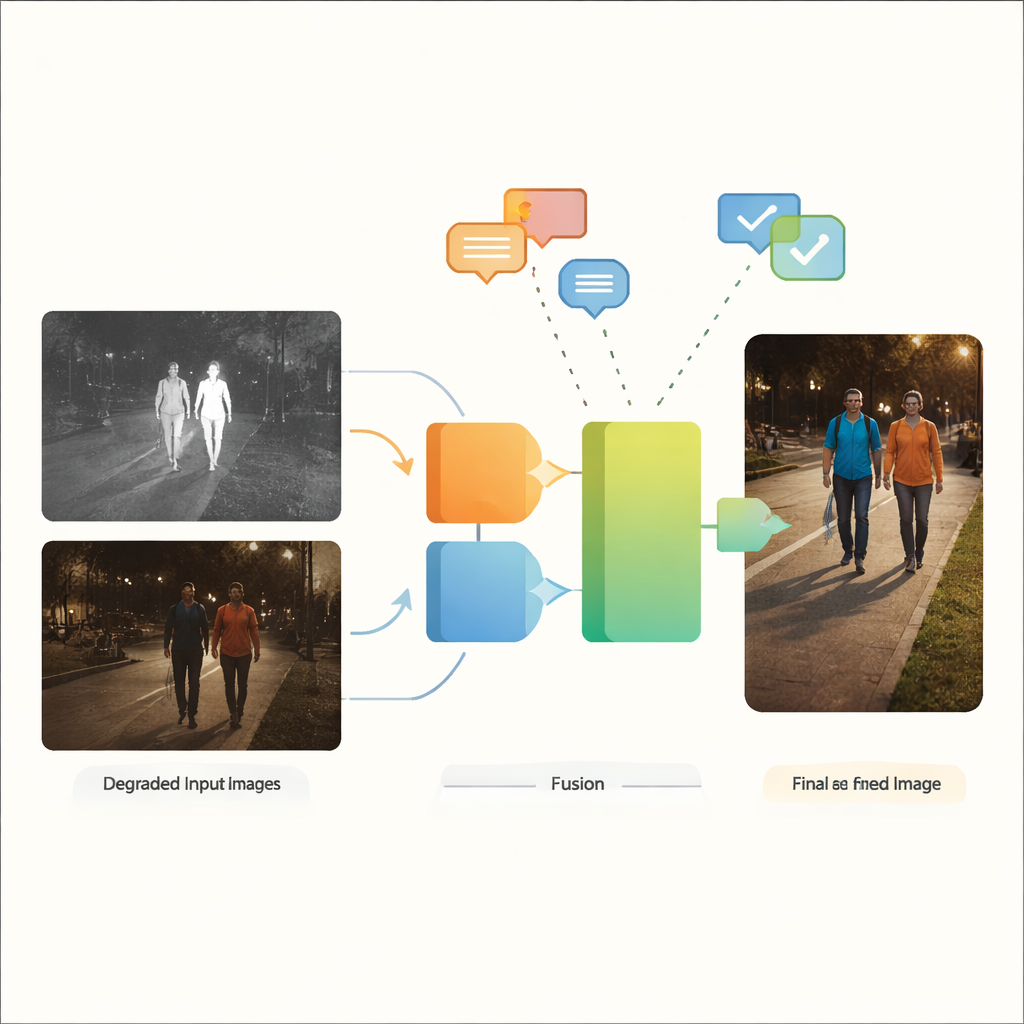
Why Two Eyes Are Better Than One
Visible-light cameras capture the rich colors and textures that humans are used to seeing, but they struggle in low light, glare, and heavy shadows. Infrared cameras, by contrast, sense heat and can easily pick out warm objects such as people or vehicles in the dark, though their images often look flat and lack fine detail. Infrared and visible image fusion aims to combine the best of both: the crisp outlines of warm targets from infrared with the contextual detail and color of visible light. Traditionally, however, most fusion methods assume that both input images are already clean and high quality—a poor fit for real streets, cities, and industrial sites where blur, noise, dim lighting, and overexposure are the norm rather than the exception.
When Preprocessing Falls Short
Existing systems typically tackle bad images in two disconnected steps. First, separate enhancement tools brighten dark scenes, reduce noise, or correct contrast. Only then does a fusion network blend the improved images. This two-stage approach has several shortcomings. It forces engineers to choose and tune different enhancement tools for each type of defect and each sensor, making workflows brittle and complex. More importantly, any information lost or distorted during standalone cleanup cannot be recovered later by the fusion stage. Some recent research introduced special networks tuned to one specific type of degradation or used language-guided models to handle a single bad modality at a time. Yet when both infrared and visible images are degraded—and often degraded in different ways—these strategies still depend heavily on manual preprocessing and struggle with mixed, real-world conditions.
A Fusion Network That Understands Degradation
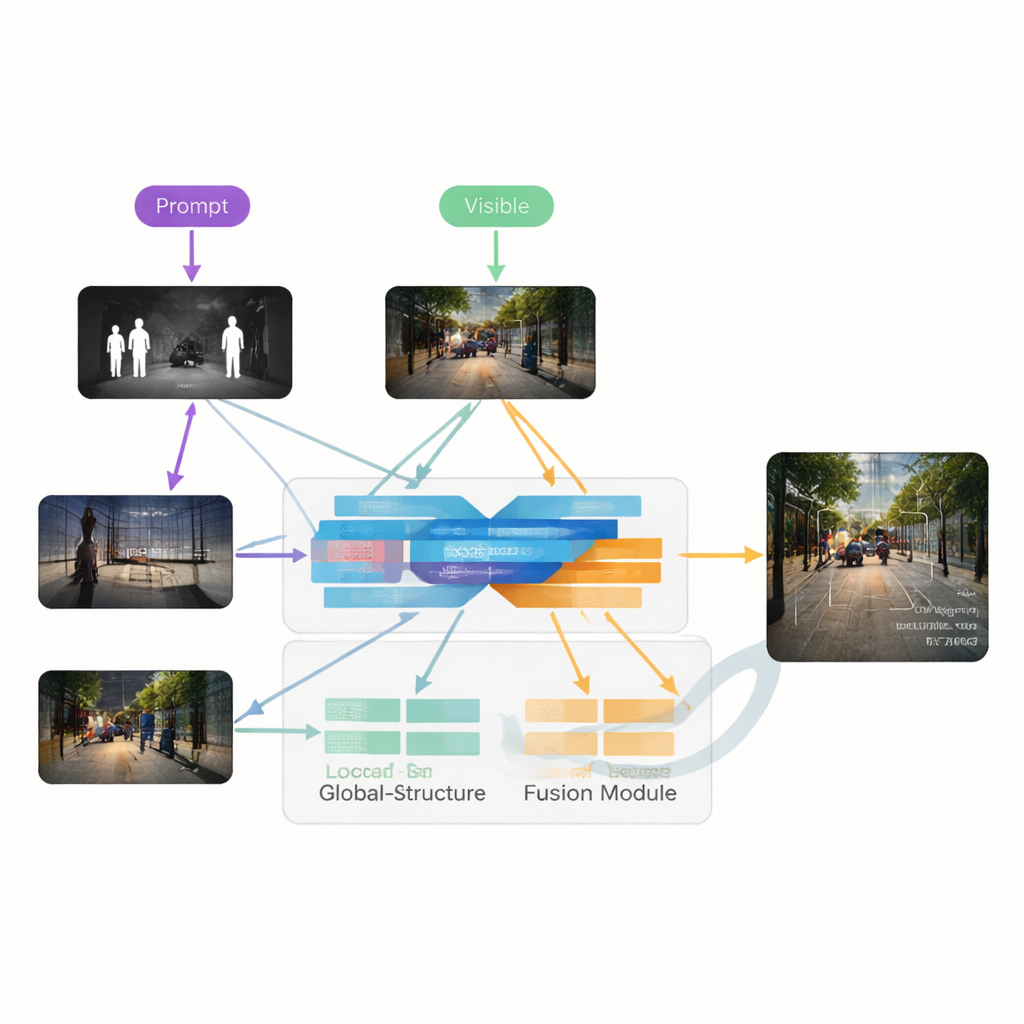
The authors propose VGDCFusion, a new deep-learning framework that weaves degradation handling directly into the fusion process. The key idea is to let the network know, in words, what kind of problems it should expect, then use that knowledge at every step of feature extraction and merging. Short text prompts describe the task (infrared–visible fusion) and the specific issues present, such as low light, overexposure, low contrast, or noise. A powerful vision–language model—similar in spirit to systems like CLIP—turns these prompts into compact numerical descriptors. These descriptors guide two main building blocks: the Specific-Prompt Degradation-Coupled Extractor (SPDCE), which works separately on each modality, and the Joint-Prompt Degradation-Coupled Fusion (JPDCF), which blends information across modalities while still paying attention to what kind of degradation remains.
How the Guided Fusion Process Works
Inside each SPDCE module, the prompt-derived guidance steers the network toward features that matter and away from artifacts. Multi-scale convolution layers look at small neighborhoods to preserve edges and textures, while Transformer layers capture larger-scale structure and context. Together they learn to highlight, for example, important heat signatures in a noisy infrared frame or faint road markings in an underexposed visible image, while suppressing sensor noise and lighting defects. In parallel, JPDCF modules take the cleaned-up features from both branches and combine them, again under prompt guidance. They use spatial and channel attention to emphasize informative regions, filter remaining degradation, and bring complementary cues together—such as aligning a bright infrared outline of a pedestrian with the color and background structure from the visible camera—before reconstructing a fused, three-channel output image.
Putting the Method to the Test
To demonstrate its usefulness, the team evaluated VGDCFusion on several public datasets that include low-light and overexposed visible images as well as noisy or low-contrast infrared images. They compared their method with a range of state-of-the-art fusion techniques spanning autoencoders, convolutional networks, generative adversarial networks, and Transformers. Using standard image-quality measures, VGDCFusion consistently produced fused images with sharper edges, better contrast, and more natural color, even when competing methods were given the advantage of carefully tuned preprocessing. The new approach improved key metrics by around 15% on average in heavily degraded scenarios. When the fused images were fed into a popular object-detection system, it also led to higher detection accuracy than using either infrared or visible images alone, or using other fusion networks.
Clearer Vision for Safer Systems
In plain terms, this work shows that telling an image-fusion network what kinds of visual problems to expect—and letting it fix and fuse in one tightly connected step—can yield cleaner, more informative pictures than treating enhancement and fusion as separate chores. By coupling degradation modeling with the fusion process and using language-guided cues at every layer, VGDCFusion can adapt to varied and mixed forms of image degradation without constant human retuning. This kind of intelligent, degradation-aware fusion could help future vision systems, from self-driving cars to security cameras, see more reliably in the messy, imperfect conditions of the real world.
Citation: Zhao, J., Zhang, T. & Cui, G. A VLM guided network coupling degradation modeling for degradation aware infrared and visible image fusion. Sci Rep 16, 8249 (2026). https://doi.org/10.1038/s41598-026-38181-8
Keywords: infrared and visible fusion, low-light imaging, vision-language models, image degradation, autonomous driving perception