Clear Sky Science · en
A hybrid stacked ensemble learning framework for multilabel text emotion detection
Why reading emotions in text matters
Every day, people pour their feelings into social media posts, reviews, and messages. Hidden in this flood of words are early warnings about mental health struggles, rising hate speech, and public reactions to crises and disasters. But computers usually see only “positive” or “negative” sentiment, missing the mix of emotions that real people often express at once. This article explores a new way to teach machines to recognize several emotions in a single piece of text, and to do so not only in English but also in languages that rarely benefit from advanced artificial intelligence.
Moving beyond simple positive or negative
Traditional sentiment analysis tools are like blunt thermometers: they can tell if the mood is good or bad, but not whether someone is feeling anger, fear, hope, or relief at the same time. The authors argue that understanding this richer emotional palette is crucial for applications such as disaster response, therapy support, and customer care. A message that mixes fear and urgency, for example, might demand immediate attention, while one that blends sadness and optimism may call for a different kind of support. Capturing several emotions in parallel—known as “multi-label” emotion detection—is therefore a key step toward more sensitive, human-aware systems.
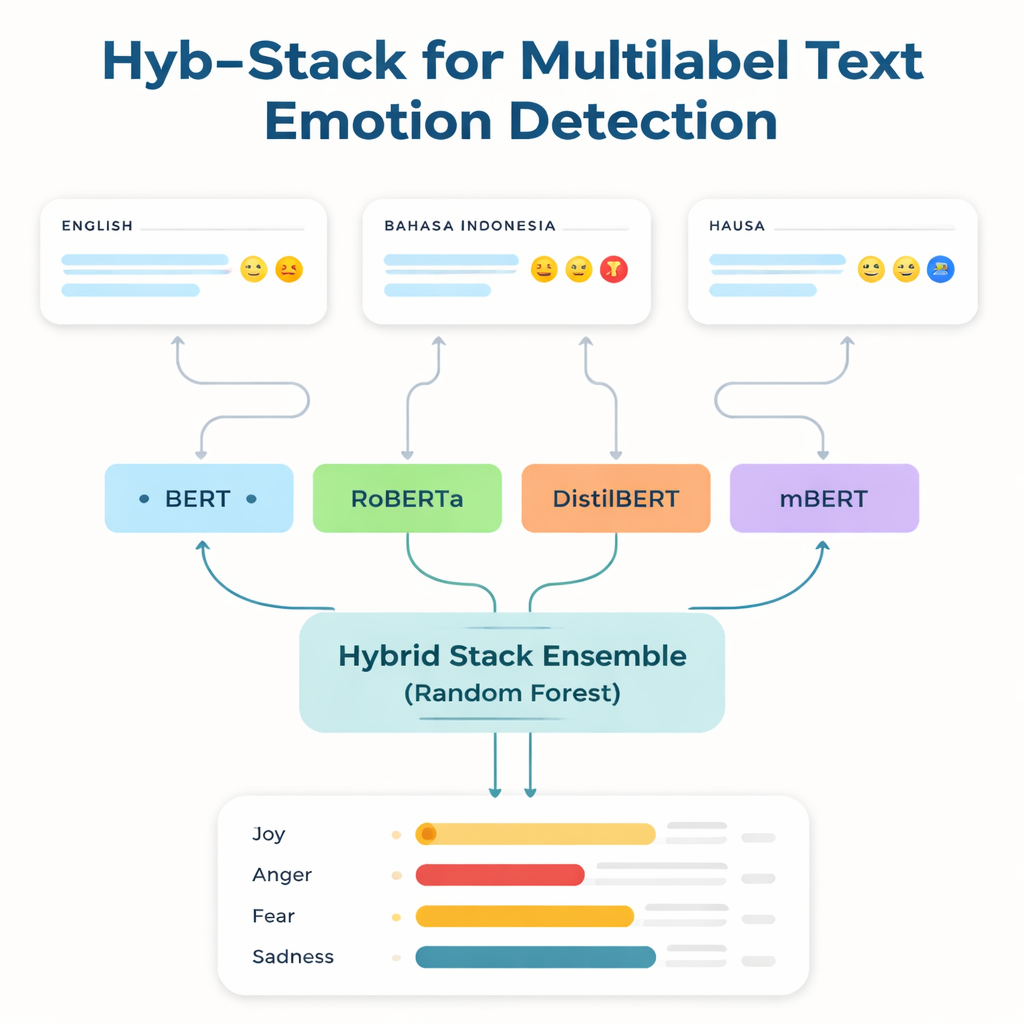
Giving a voice to overlooked languages
Most powerful language technologies are trained and tuned on English and a few other widely used tongues. Speakers of low-resource languages—those with little labeled data and few digital tools—are often left behind. To tackle this gap, the researchers focus on three datasets: a well-known English emotion benchmark; a Bahasa Indonesia collection centered on abusive and hateful language; and a brand-new Hausa Twitter corpus they created, called HaEmoC_V1. The Hausa dataset includes more than twelve thousand carefully cleaned and annotated tweets, each tagged with one or more of eleven emotions such as anger, joy, trust, pessimism, and anticipation. Expert reviewers checked the labels, and agreement scores showed that the annotations are both consistent and reliable.
Combining several smart readers into one
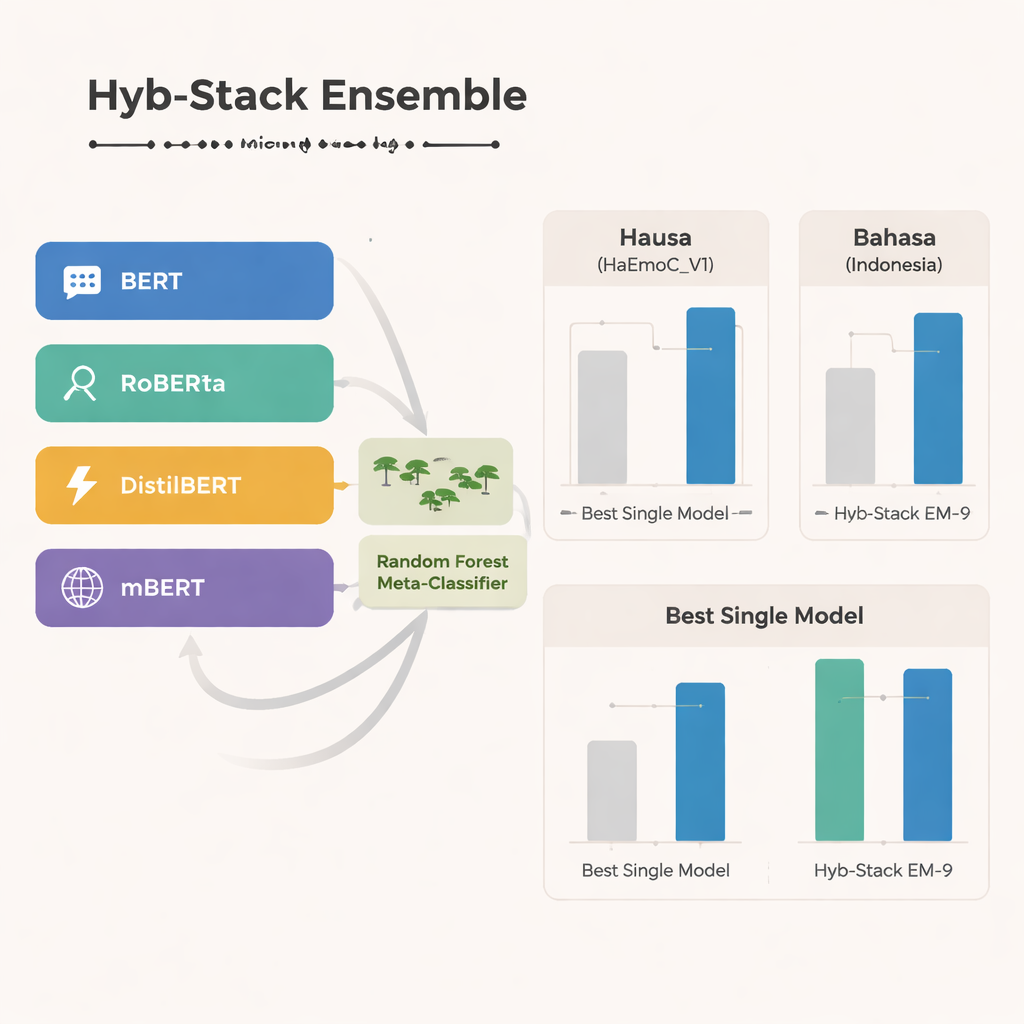
At the core of the study is Hyb-Stack, a hybrid stacked ensemble—a kind of “committee of experts” for language. Four advanced transformer-based models (BERT, RoBERTa, DistilBERT, and the multilingual mBERT) are each fine-tuned to read emotional signals in text. Rather than trusting only one model, Hyb-Stack lets them all make predictions, then feeds their internal scores into a second-level decision maker: a Random Forest classifier. This meta-classifier learns how to weigh the different strengths of each model, capturing complex patterns in how emotions co-occur. The team also tests simpler ensemble methods that just average predictions, with or without weighting by prior performance, to see whether the more elaborate stacking really pays off.
How well the hybrid approach performs
Across all three languages, the multilingual mBERT stands out as the single strongest model, performing especially well on the newly built Hausa data and the Bahasa Indonesia hate speech set. Yet the hybrid ensemble goes even further. One particular combination—called EM-9, which merges BERT, DistilBERT, and mBERT inside the Hyb-Stack framework—consistently delivers the best results. It achieves higher F1-scores, a common measure of accuracy, than any individual model or simple averaging approach, with the largest gains appearing in the low-resource Hausa and Bahasa Indonesia datasets. Detailed error analyses show that remaining mistakes usually occur between closely related emotions, such as joy versus surprise or sadness versus fear, reflecting the natural fuzziness of human feeling rather than clear system failures.
What this means for real-world systems
For a general reader, the main takeaway is that combining several AI models in a smart way can help computers read emotions in text more accurately, especially in languages that have long been neglected in technology. By building a high-quality Hausa emotion corpus and showing that hybrid ensembles outperform single models and simple voting schemes, the authors demonstrate a practical path toward more inclusive, emotionally aware tools. Future work will extend the approach to more subtle emotional shades, code-mixed language, emojis, and additional underrepresented languages, with the goal of creating systems that can sense not just whether people are happy or sad, but how and why they feel the way they do—no matter what language they speak.
Citation: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
Keywords: emotion detection, multilingual NLP, ensemble learning, transformer models, low-resource languages