Clear Sky Science · en
Efficient computation and design of high speed double precision Vedic multiplier architecture
Why faster number crunching matters
Every time you stream a video, use navigation on your phone, or let an AI system analyze medical images, specialized computer hardware is quietly performing billions of tiny calculations per second. A large fraction of those operations are multiplications on "floating-point" numbers, the standard way computers represent real values like 3.14159. This paper explores a smarter way to build one of those core components: a high-speed, energy-efficient multiplier that draws on ideas from ancient Vedic mathematics to boost modern digital hardware.
From ancient math tricks to modern chips
Floating-point arithmetic underpins digital signal processing, image processing, communications, and deep-learning accelerators. Standard multipliers must handle wide binary words—64 bits for double precision—and do so quickly without wasting chip area or power. Traditional approaches, such as Booth, Karatsuba, and array multipliers, juggle trade-offs between speed, hardware size, and design complexity. Vedic mathematics, a system of 16 classic arithmetic rules developed in India, includes a multiplication method called Urdhva Tiryakbhyam, or "vertical and crosswise." It forms partial products in a highly parallel way, which can reduce the number of intermediate steps and the hardware needed. Researchers have recently adapted these ideas to digital circuits, but existing designs still carry overheads when used for double-precision floating-point operations.
What is special about this new multiplier
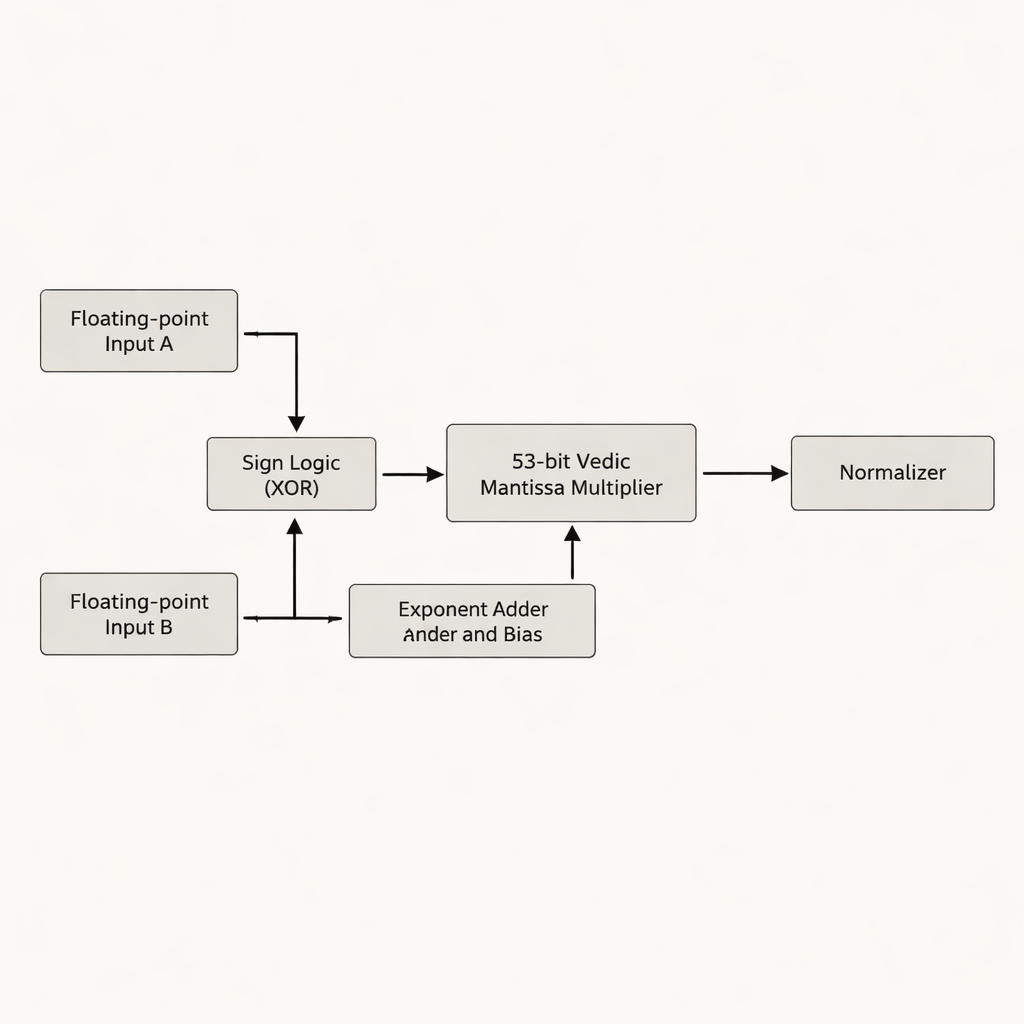
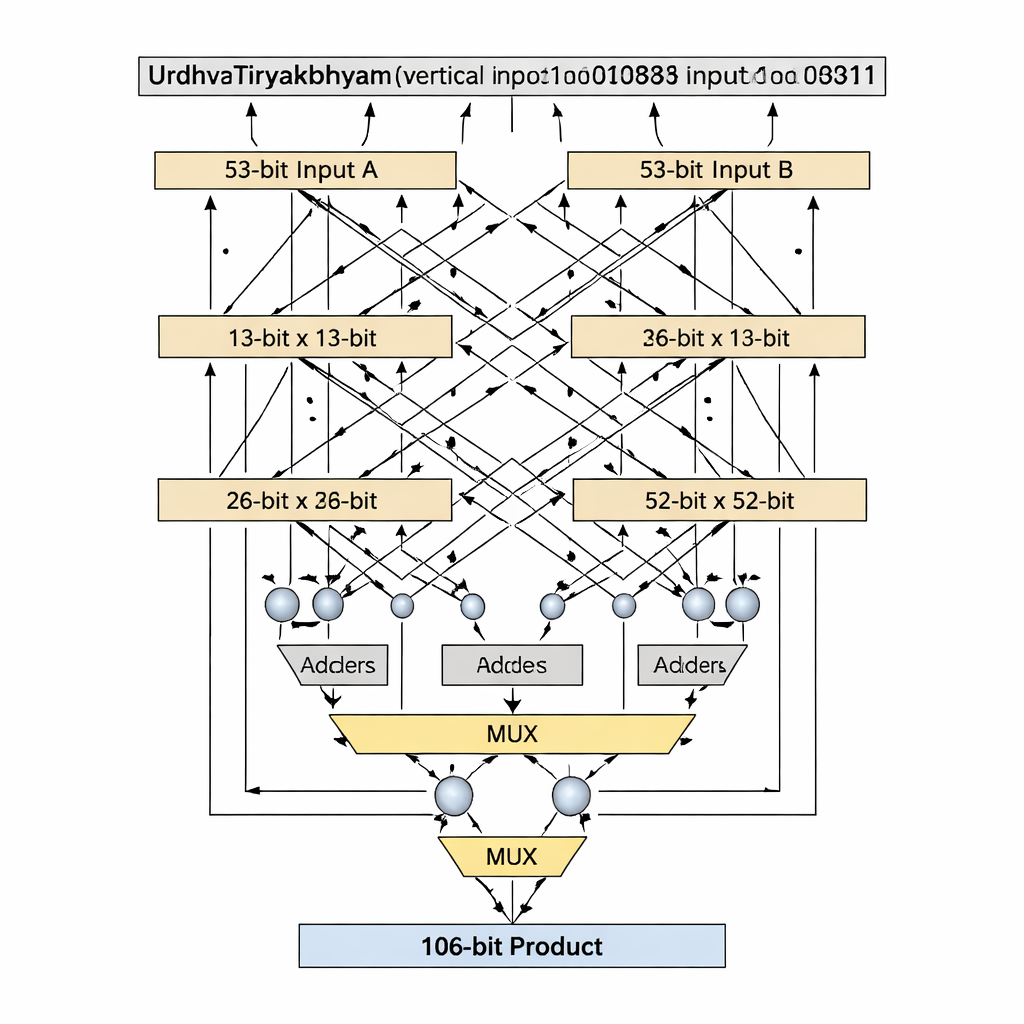
The authors propose a double-precision floating-point multiplier that focuses on the mantissa—the part of a floating-point number that holds most of the significant digits. Instead of padding the 52-bit mantissa to 54 bits, as many prior designs do, they work with the true 53-bit effective mantissa, avoiding wasted "white space" bits that consume extra storage and wiring on a chip. The heart of the design is a 53-bit Vedic multiplier based on Urdhva Tiryakbhyam, arranged in a hierarchy of smaller building blocks: 3-bit units form 6-bit units, which build 12-bit, 13-bit, 26-bit, and 52-bit units, all combined into the final 53-bit stage. The architecture separates the work into three main phases—sign computation, exponent addition and biasing, and mantissa multiplication followed by normalization—matching the IEEE-754 floating-point standard while trimming redundant circuitry.
Prime-sized building blocks for cleaner hardware
A key innovation is how the design handles bit-widths that are prime numbers, such as 13 and 53, which do not divide neatly into equal-sized blocks. Standard Vedic decompositions assume evenly split inputs, but that becomes awkward or wasteful for prime lengths. The authors introduce a "prime-bit" algorithm that cleverly reuses a smaller (n−1)-bit Vedic multiplier, plus adders, multiplexers, and a single extra logic gate, to emulate an n-bit multiplier without padding. For the 13‑bit stage, the inputs are split into 1-bit and 12-bit sections; partial products are created using a 12-bit Vedic multiplier, conditional selection (via multiplexers) based on the most significant bits, and a small number of adders. The same pattern scales up to 53 bits with a 52-bit core. This tailored decomposition shortens the critical path—the longest chain of logic a signal must traverse—while keeping the number of logic elements low.
Measured gains in speed, size, and power
The design was described in Verilog hardware description language and implemented on a Xilinx Zynq field-programmable gate array (FPGA) using Vivado tools. Across 13-, 26-, 52-, 53-, and 64-bit Vedic multipliers, the proposed 53-bit unit shows a favorable balance of delay, logic usage (lookup tables and I/O pins), and estimated power. When compared with earlier double-precision multipliers based on Booth, Karatsuba, and other Vedic arrangements, the new architecture significantly reduces the worst-case delay and the amount of FPGA resources needed, without adding complexity to the surrounding floating-point circuitry. Because the mantissa multiplication is faster and the logic depth is shallower, switching activity is reduced, which points to a better power–delay product even though direct cross-technology power comparisons are hard to make.
Impacts on AI and signal processing
To test the design in a real workload, the authors integrated their Vedic double-precision multiplier into the convolution engine of a Convolutional Neural Network, where multiply-and-accumulate operations dominate runtime. Replacing conventional IEEE-754 and earlier Vedic multipliers with the new design cut convolution delay, reduced power consumption, and lowered inference time, all while maintaining the same classification accuracy. Similar advantages are expected in other computation-heavy tasks, such as digital filtering, edge detection, and medical imaging pipelines, where faster multipliers directly increase throughput and can allow devices to run cooler or on smaller batteries.
What this means for everyday technology
In plain terms, the paper shows that borrowing a clever multiplication idea from Vedic mathematics and carefully matching it to modern binary formats can yield a multiplier that is smaller, faster, and more energy-efficient than standard designs. This improved building block can slot into processors, signal-processing chips, and AI accelerators, leading to quicker data analysis, more responsive devices, and potentially lower power usage in systems ranging from smartphones to medical scanners. The authors also outline future directions, including reversible logic for even lower energy use and integration into larger processing units, suggesting that this marriage of ancient arithmetic and modern hardware is just getting started.
Citation: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
Keywords: Vedic multiplier, floating-point arithmetic, FPGA design, digital signal processing, convolutional neural networks