Clear Sky Science · en
Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data
Why filling in data gaps matters
Coastal waters are the front line where human activity meets the ocean. Scientists track how salty these waters are using a measure called specific conductance, which helps reveal pollution leaks, changes in freshwater flow, and long‑term environmental shifts. But sensors fail, storms knock out power, and instruments have limits. The result is frustrating gaps in key records—just when managers and researchers most need continuous data. This study asks a practical question: can modern artificial intelligence reliably "repair" those broken records so coastal decisions are based on complete, trustworthy information?
Watching the Gulf breathe
The researchers focused on the Gulf of Mexico, one of the world’s largest marine ecosystems and a region under heavy industrial and agricultural pressure. They used measurements from five U.S. Geological Survey stations near the Pascagoula River and Mullet Lake, each recording water saltiness (through specific conductance), temperature, and water level every 15 minutes. One station, called E, had about 5% of its specific‑conductance data missing—exactly the sort of problem that confronts real‑world monitoring networks. Data from the four neighboring stations formed a kind of environmental safety net: even when station E went blind, the others kept watching. The central idea was to teach computer models to learn how all five stations “breathe” together so that gaps at one site could be inferred from complete records at the others.
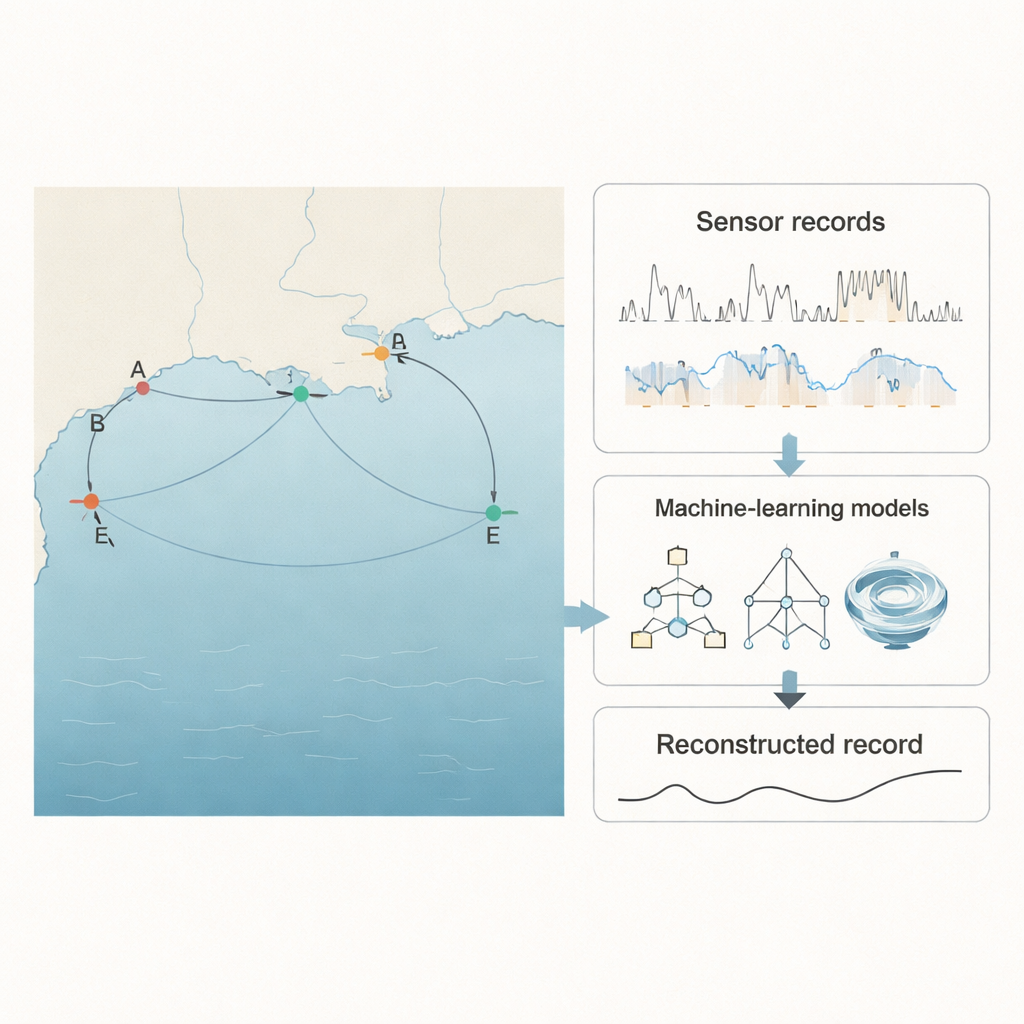
Putting smart algorithms to the test
To tackle this, the team assembled a line‑up of ten different modeling approaches. At one end were familiar tools such as multiple linear regression, which try to draw straight‑line relationships between inputs and outputs. In the middle were more flexible models like classic neural networks, fuzzy‑logic systems, and a special long short‑term memory (LSTM) network often used for time‑series data. They also used a self‑organizing method called group method of data handling (GMDH) and a nonlinear variant (NGMDH) that can build multi‑layered formulas by itself. Finally, they brought in tree‑based methods: a single decision‑tree model (CART) and two “ensemble” approaches—Random Forest and XGBoost—that combine many trees to make a final decision, much like a panel of experts voting on an answer.
Swarm‑powered deep learning
Training deep neural networks is notoriously tricky: their many knobs and switches can easily get stuck in poor configurations. To improve them, the authors paired LSTM and NGMDH with a recent optimization method inspired by swirling water, called turbulent flow of water‑based optimization (TFWO). In this scheme, each possible set of model parameters is imagined as a “particle” moving in a whirlpool‑like pattern through the space of all solutions. Over many cycles, the particles are nudged toward regions that give smaller prediction errors. This swarm‑style search made both neural network types noticeably more accurate than their standard versions, cutting their average errors by around 6–11 percent. Still, even these upgraded deep models were ultimately outclassed by the tree‑based approaches.
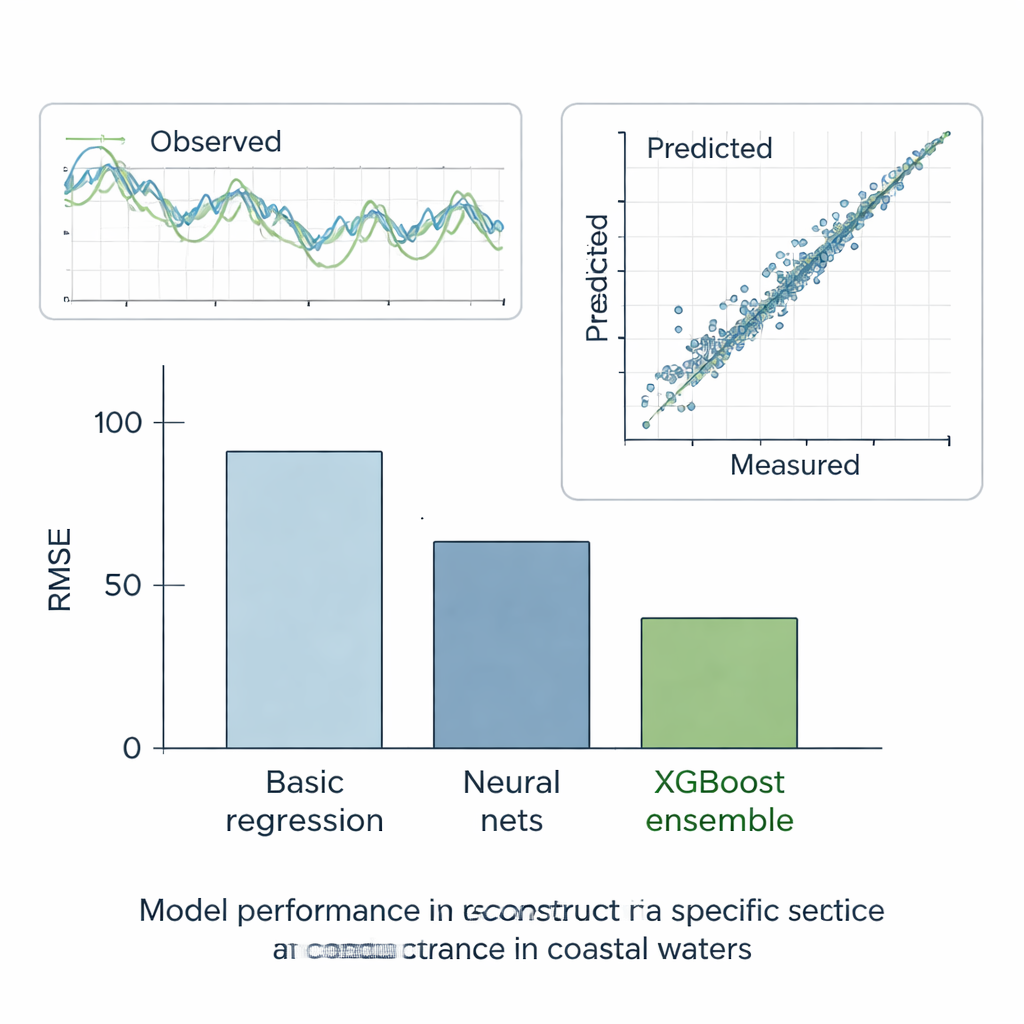
Ensembles take the lead
The authors rigorously tested all methods in six scenarios. In five “what‑if” cases, they hid pieces of otherwise complete records and checked how well each model could reconstruct the missing values. In the final, real‑world case, they asked the models to fill the true gaps at station E using its neighbors’ data. Across these tests, the simplest straight‑line method performed the worst, while standard machine‑learning models did much better, reducing error by roughly half. Decision trees, which automatically split data into more uniform groups, improved further. But the clear winner was the XGBoost ensemble: by building hundreds of trees that each correct the mistakes of the previous ones, it achieved extremely low error and an almost perfect match between predicted and measured specific conductance. Its reconstructions followed observed time series closely and reproduced the overall statistical behavior of the water‑quality records.
What this means for coasts and beyond
For non‑specialists, the take‑home message is straightforward: carefully designed AI can reliably fill in missing pieces of coastal water‑quality records, especially when nearby stations are available to provide context. While advanced neural networks are powerful, this study shows that tree‑based ensemble methods like XGBoost are even more accurate and, in practice, may be the best choice for repairing environmental datasets. With robust gap‑filling tools, scientists can better track subtle changes in coastal salinity, identify pollution events, and support management decisions without being derailed by inevitable sensor failures. The same strategies can be adapted to many other engineering and environmental problems where data streams are rich, noisy, and occasionally incomplete.
Citation: Mahdavi-Meymand, A., Sulisz, W. & Nandan Bora, S. Application of swarm-based deep neural networks and ensemble models for reconstruction of specific conductance data. Sci Rep 16, 7292 (2026). https://doi.org/10.1038/s41598-026-38136-z
Keywords: coastal water quality, specific conductance, machine learning, missing data reconstruction, XGBoost