Clear Sky Science · en
YOLC with dynamic sparse attention for high-speed small target detection in wearable sports images
Seeing Sports Through a Player’s Eyes
Imagine watching a tennis serve or a table tennis rally not from the stands, but through a camera strapped to an athlete’s head. The ball streaks across the field of view as a tiny blur, yet coaches and analysts would love to know exactly where it went, how fast, and how players reacted. This paper presents a new computer-vision system called YOLC that is designed to spot and follow these fast, small objects in real time on tiny, low‑power wearable devices.
Why Tiny, Fast Targets Are So Hard to Catch
Wearable cameras have become common in sports training, capturing first-person video of matches and drills. But from this viewpoint, crucial objects – a shuttlecock, a tennis ball, a sprinting runner’s starting foot – often occupy only a handful of pixels and move rapidly from frame to frame. Existing detection systems are either too heavy for low‑power devices or lose track when objects are small, blurred, or far away. The authors show that in real sports footage, many targets are smaller than 32 by 32 pixels and move so fast between frames that standard methods miss them or repeatedly lose their identity, breaking trajectories and undermining any serious performance analysis.
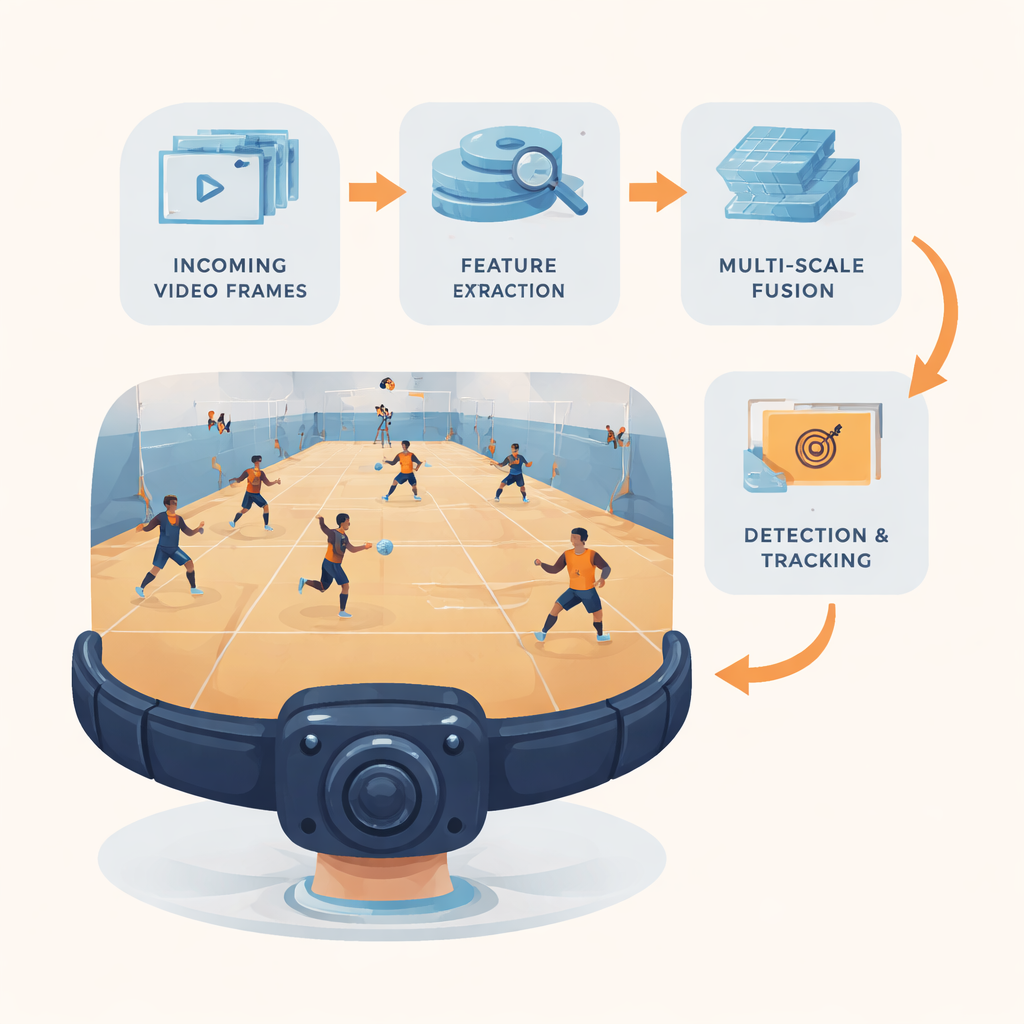
A Lightweight Vision Pipeline for Wearable Cameras
The researchers introduce YOLC (short for “You Only Look Clusters”), a complete detection-and-tracking pipeline tailored for edge hardware like an NVIDIA Jetson Nano. At its core is a streamlined feature extractor built from an efficient neural network family known as MobileNet, reshaped to use mostly “cheap” operations that reduce both memory and computation while keeping enough detail to see tiny objects. Video frames are resized to a balanced resolution, and three levels of feature maps are produced: one emphasizing fine details for small targets, one for medium objects, and one with stronger high-level semantics for large or distant items. These multi-scale maps feed the rest of the system, which is carefully engineered to squeeze as much information as possible from every computation.
Letting the Network Look Only Where It Matters
A central innovation is a “dynamic sparse attention” mechanism that mimics how a human might glance only at the most informative parts of a scene. Instead of processing every pixel equally, YOLC measures how much the image changes locally – for example at edges, corners, or the outline of a moving ball – and builds a map of where texture is most pronounced. It then keeps only about the top 30 percent of these high-response locations for further processing, effectively shutting off noisy background regions such as walls, stands, or sky. A special training trick allows the model to remain fully trainable despite this hard cut‑off. This selective focus not only improves accuracy by ignoring distractions, it also slashes the amount of work the network must do, a crucial advantage on battery-powered wearables.
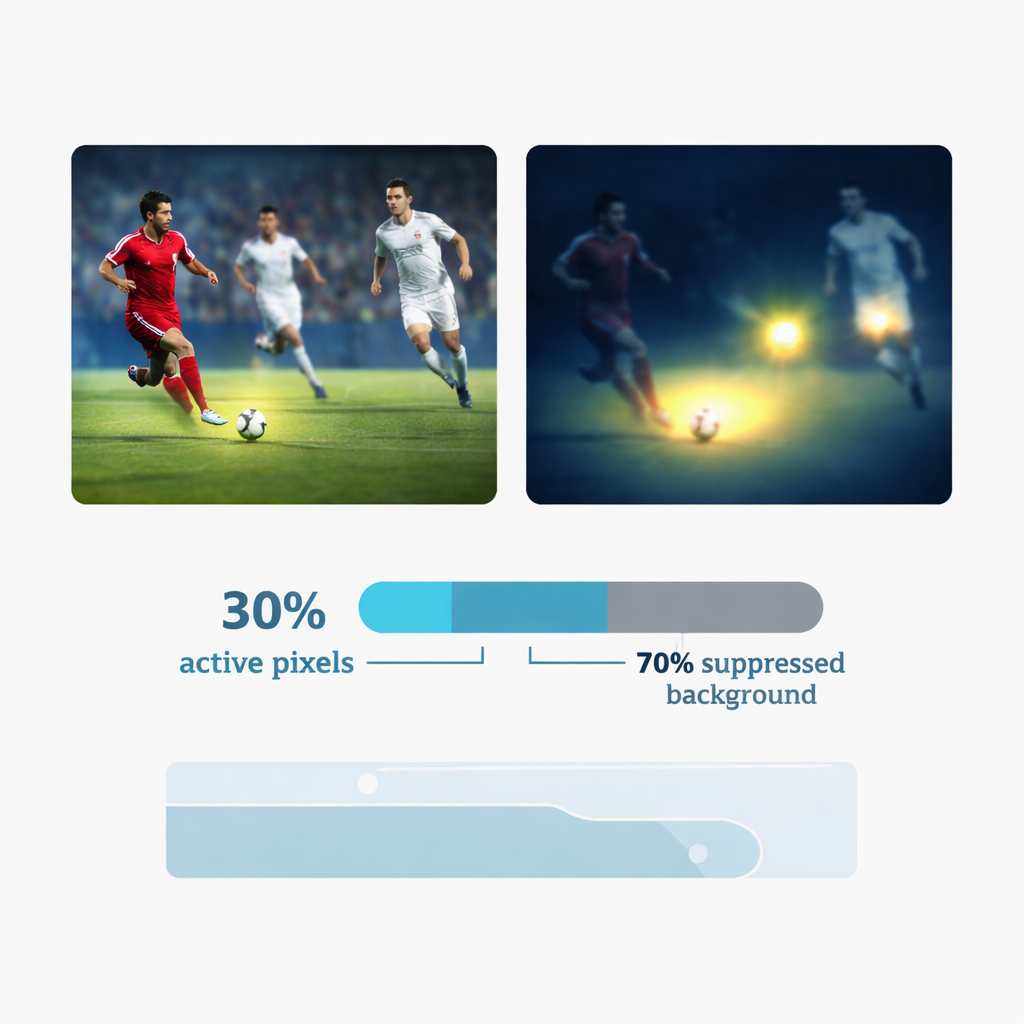
From Sharp Features to Stable Tracks
After focusing on key regions, YOLC combines information across scales using a bidirectional feature pyramid that passes signals both from coarse to fine and from fine to coarse layers. The strength of these connections is guided by the same attention map, so important small objects get amplified at every stage. In the final detection step, an additional “coordinate attention” unit helps the system better understand where objects are in the frame by linking signals along horizontal and vertical directions. To turn frame-by-frame detections into smooth tracks over time, the method adds a lightweight optical-flow module – a tool that estimates how pixels move between consecutive frames – and a two-stage matching scheme that first pairs high-confidence detections with existing tracks, then cautiously reuses lower-confidence boxes that fit the expected motion. Together, these pieces reduce identity swaps and gaps, even when objects cross paths or are briefly hidden.
Performance in the Real World
The team tested YOLC on a custom sports dataset that includes badminton, basketball, tennis, sprinting, and table tennis, all captured with a head‑mounted camera in real training environments. On this challenging material, the system runs at 53.5 frames per second with just 1.78 million parameters, far less than many popular object detectors. It achieves a detection score (mAP@0.5) of 75.3 percent and a small-object recall above 80 percent, outperforming several well‑known lightweight models. In tracking benchmarks, YOLC maintains longer, more reliable trajectories and drastically reduces identity switches. It also proves robust under motion blur and camera shake, roughly halving the false alarm rate compared with competing methods.
What This Means for Sports and Beyond
For coaches, analysts, and equipment makers, the message is clear: accurate, real-time understanding of fast sports actions does not have to depend on bulky servers or pristine TV-style footage. By carefully deciding where and when to spend computation, YOLC turns noisy, first-person wearable videos into detailed records of how small, fast objects move and interact with athletes. That can enable richer feedback in training, safer monitoring in high-intensity sports, and, more broadly, smarter vision systems on any small device that must see clearly under tight hardware limits.
Citation: Chen, H., Song, Y., Liu, W. et al. YOLC with dynamic sparse attention for high-speed small target detection in wearable sports images. Sci Rep 16, 6858 (2026). https://doi.org/10.1038/s41598-026-38079-5
Keywords: wearable sports vision, small object detection, real-time tracking, edge AI, attention mechanisms