Clear Sky Science · en
The construction and refined extraction techniques of knowledge graph based on large language models
Smarter Maps for Complex Decisions
Modern decisions in high‑stakes fields—like large‑scale operations, infrastructure management, or disaster response—depend on quickly making sense of huge amounts of scattered information. Manuals, sensor feeds, reports, and simulations all tell part of the story, but they are rarely organized in a way humans or computers can easily use. This paper presents a way to turn that fragmented information into living “maps of knowledge” powered by large language models, so that planners and analysts can ask better questions and get faster, more reliable answers.
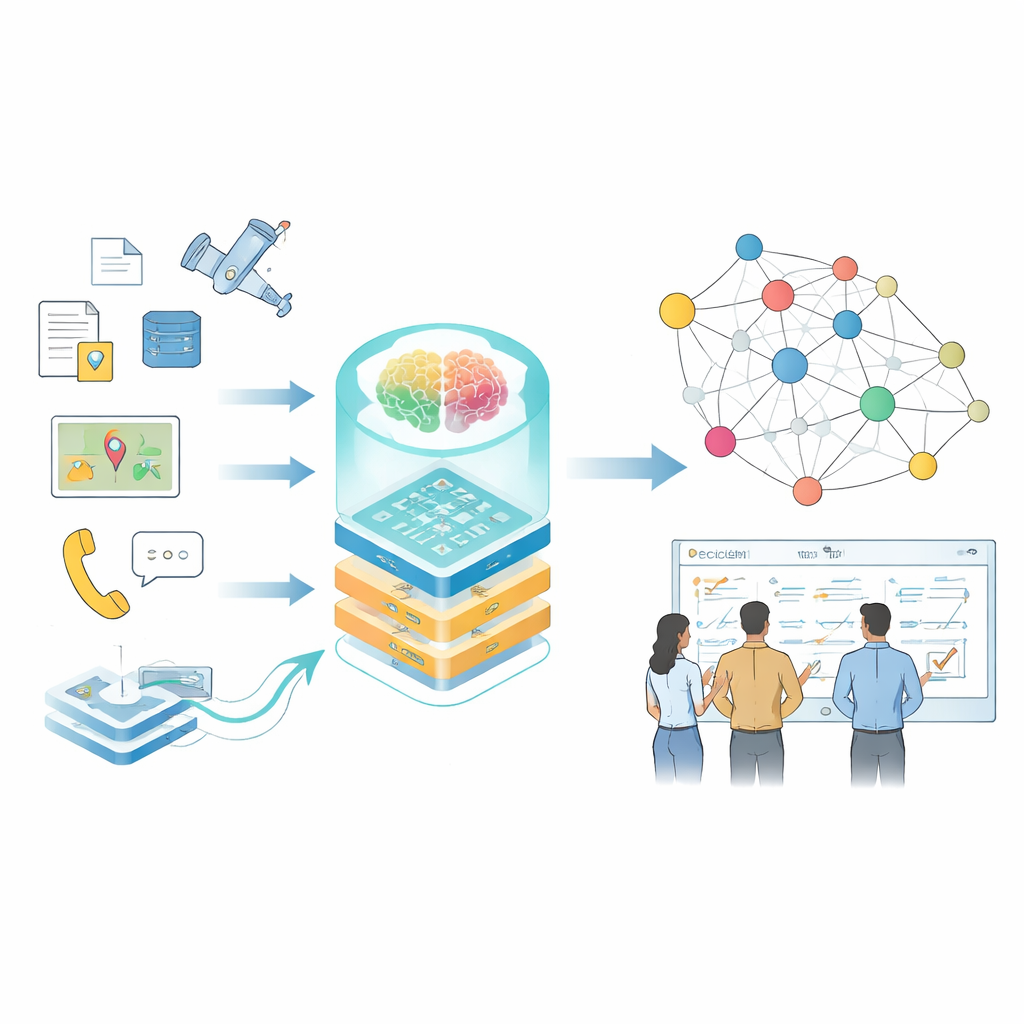
From Scattered Facts to Connected Knowledge
The authors focus on knowledge graphs, a way of representing information as a web of connected facts—who did what, with which system, under which conditions. In everyday settings, such graphs already power search engines and recommendation systems, but specialized domains pose tougher problems: data is sensitive, terminology is dense, formats range from free‑text reports to sensor logs, and conditions change rapidly. Traditional tools that rely on hand‑written rules or small models struggle to keep up, and general‑purpose language models often misread technical terms or miss subtle relationships that matter for real‑world decisions.
Teaching Large Language Models a New Specialty
To address this, the study fine‑tunes a powerful base language model on a carefully designed, domain‑specific dataset. The dataset draws on command communications, equipment manuals, simulated scenarios, and expert literature. Before any of this material reaches the model, it is heavily desensitized: concrete coordinates become relative locations, unit names turn into generic codes, and sensitive logic is partially masked while preserving overall patterns. The data is stored in a structured format that describes the broader situation, the specific tasks (such as planning, threat ranking, or question answering), and the links between them. This structure lets the model learn not only isolated facts, but also how different tasks share context.
Layers of Adaptation for Different Tasks
Instead of retraining every parameter in the language model—a costly and risky process—the authors use a technique called low‑rank adaptation, organized into several layers that each focus on a different aspect of the problem. One layer captures basic terminology and concepts, another embeds operational rules and constraints, and a third specializes in adapting to particular tasks, such as planning or threat assessment. A separate control component, the “routing” network, looks at each piece of input and decides which combination of these lightweight adapters the model should use. This design allows the system to switch efficiently between tasks while preserving both general language ability and domain‑specific expertise.
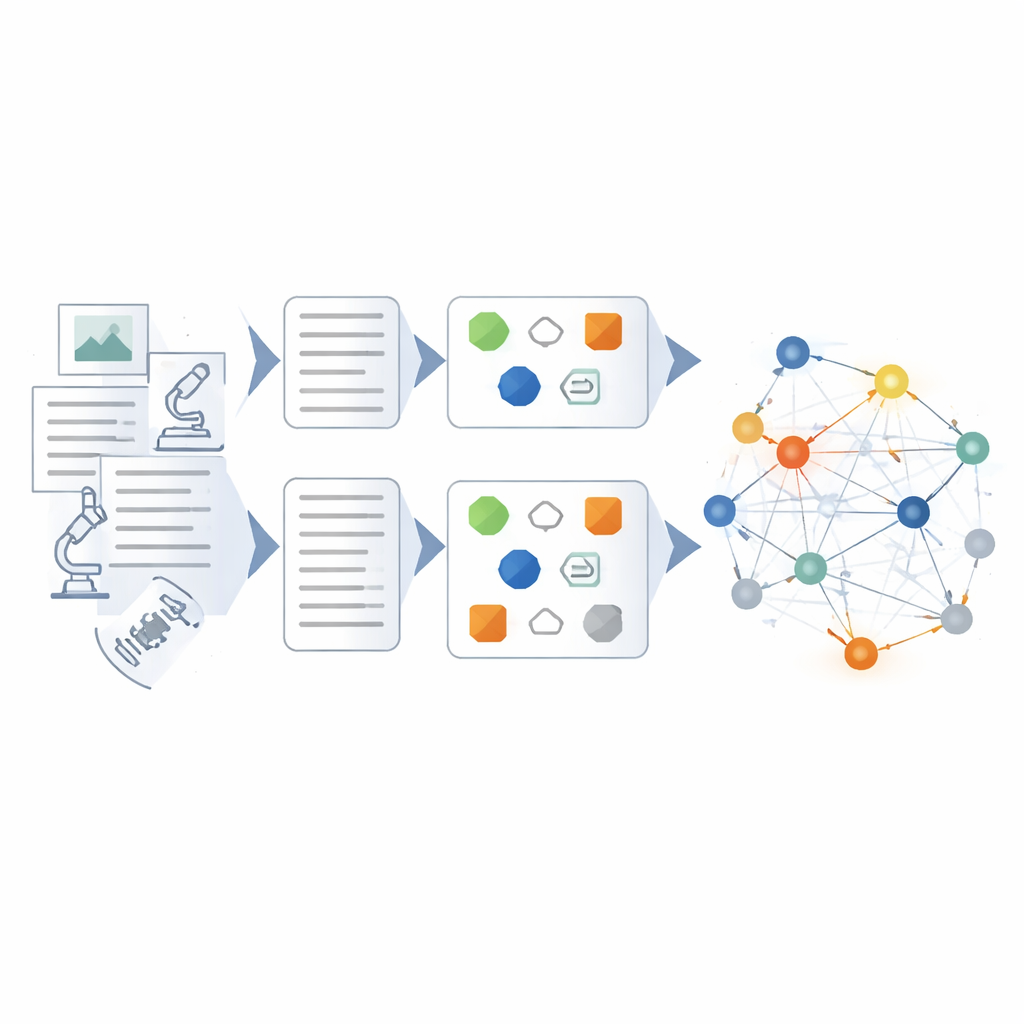
Building and Checking the Knowledge Web
On top of the tuned model, the authors design a hybrid pipeline for building the knowledge graph itself. First, raw data is cleaned and standardized so that terms and formats are consistent. Then, rule‑based methods and expert‑crafted templates extract obvious entities and events. The fine‑tuned language model steps in to handle more complex work: shortening messy reports into concise summaries, identifying key actors and equipment, and inferring relationships such as cause‑and‑effect chains or coordination between units. Each extracted fact is scored from several angles—how well it fits known patterns, how strongly it connects to other facts, and whether it aligns with multi‑step reasoning paths through the graph. Only high‑confidence results are added, and low‑confidence ones are flagged for review.
Proven Gains in Accuracy and Reliability
The team evaluates their approach on three core tasks that mirror real‑world needs: answering complex questions about rules and equipment, proposing action plans for given situations, and ranking different threat scenarios by seriousness. Across these tasks, the adapted model consistently outperforms well‑known general systems, including frontier models with far more generic training. It answers more questions correctly, produces more realistic plans, and ranks threats more accurately. The resulting knowledge graph is both large and tightly connected, with over 90 percent of its stored facts passing strict confidence checks and helping planners reach sound decisions more quickly.
Why This Matters Going Forward
For a lay reader, the key message is that language models can be turned from smooth talkers into careful, specialized analysts—if they are trained on the right data, constrained by clear rules, and constantly checked for quality. This work shows how to do that in a sensitive, fast‑changing domain while protecting private information. The framework not only organizes scattered knowledge into a usable web, but also keeps that web up to date and trustworthy, offering a blueprint for future decision‑support systems in any field where getting complex calls right truly matters.
Citation: Peng, L., Yang, P., Juexiang, Y. et al. The construction and refined extraction techniques of knowledge graph based on large language models. Sci Rep 16, 8104 (2026). https://doi.org/10.1038/s41598-026-38066-w
Keywords: knowledge graph, large language model, decision support, domain adaptation, data desensitization