Clear Sky Science · en
Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms
Why almost-random matters for everyday security
Every time you shop online, unlock your phone, or send a private message, unseen mathematical dice are being rolled to keep your data safe. These dice take the form of long strings of supposedly random bits used as cryptographic keys. If those bits are even slightly less random than they should be, determined attackers can sometimes find patterns to exploit. This paper explores a new way to manufacture “almost-random” test sequences—data that looks extremely random but hides tiny flaws—so that engineers can seriously stress‑test the devices that guard our digital lives.
When random numbers aren’t quite random enough
Modern security systems rely on two kinds of random number generators. True random number generators draw on unpredictable physical effects, such as electronic noise or quantum fluctuations, while pseudo‑random generators use algorithms that turn short, random seeds into long sequences. In practice, the quality of both ultimately depends on the physical source of unpredictability, called an entropy source. Unfortunately, real‑world entropy sources are fragile: temperature changes, hardware aging, or design mistakes can quietly reduce their randomness. To catch such problems, standards bodies like NIST define batteries of statistical tests that check whether output bits look random enough. Devices increasingly embed “real‑time randomness testers” that monitor their own output as they run. Yet there has been no good way to generate realistic, hard‑to‑detect failure cases to test whether those embedded checkers really work.
Designing sequences that barely fail random tests
From a tester’s point of view, trivial failures—like outputs that are all zeros—are easy to spot. The real challenge is detecting borderline cases: sequences that are almost indistinguishable from ideal randomness but just fail one or more statistical checks. The authors focus on five classic tests that look at different aspects of bit patterns, including how often zeros and ones appear, how pairs of bits behave, how certain short patterns are distributed, how bits correlate with shifted copies of themselves, and how the lengths of runs of identical bits are arranged. They define a “borderline zone” for each test: a narrow band where the data only slightly violates the usual acceptance thresholds. Producing a long sequence that lands inside all of these narrow bands at once is extremely unlikely by chance, because the tests interact in complicated, non‑linear ways. This is where optimisation and AI come in.
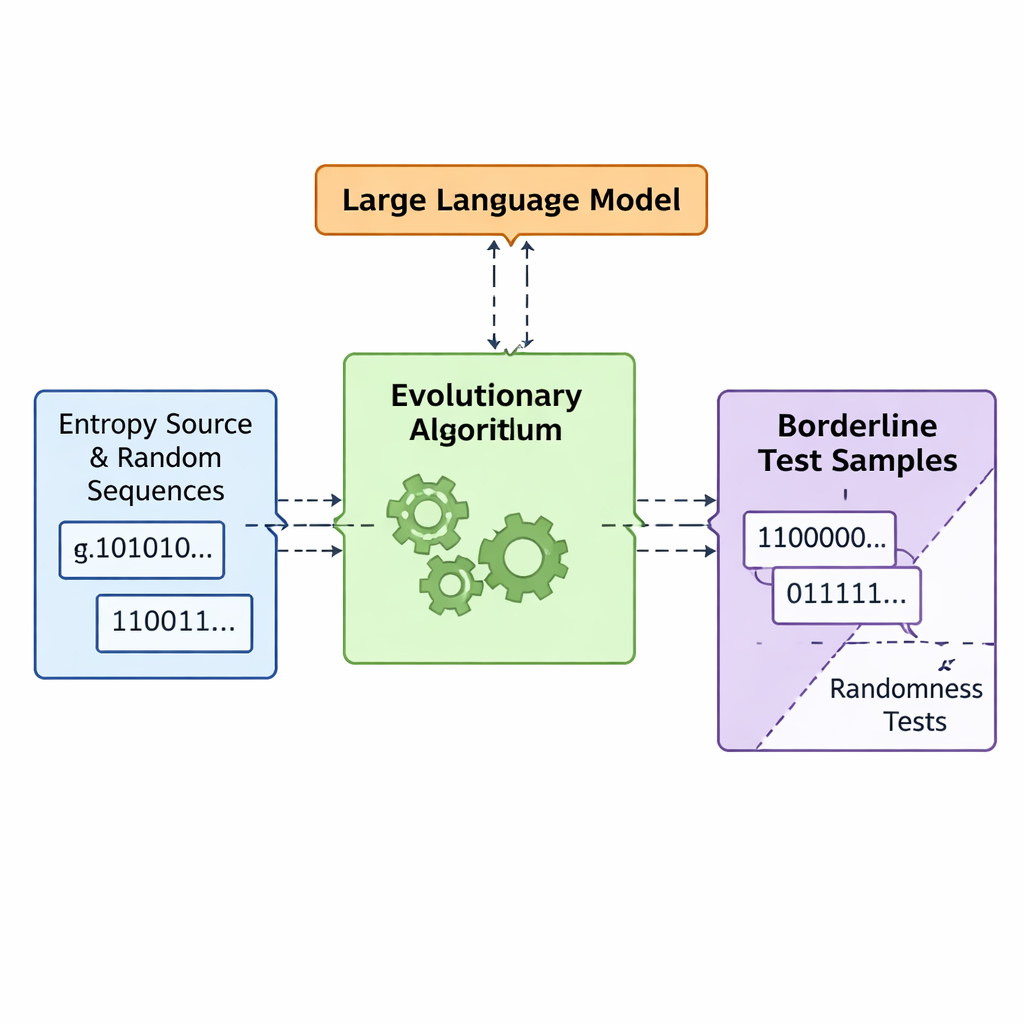
Let evolution and language models co‑design bad randomness
The team introduces a framework called APAM‑IGLLM that treats sequence generation as a high‑dimensional optimisation problem. Each candidate sequence is a string of bits, and its “fitness” measures how close it comes to the borderline zones of the five tests. A genetic algorithm repeatedly mutates and recombines these sequences, keeping those that move closer to the target region. On top of this, a large language model (LLM) acts as a kind of strategy coach. At every generation it examines summary statistics of the population and short‑term history, then suggests how to adjust internal knobs—weights and scaling factors that decide how strongly each test influences fitness. This creates a feedback loop: the genetic algorithm explores the space of possible sequences, while the LLM steers the search so that all five test scores converge toward the tiny intersection where sequences are just barely non‑random.
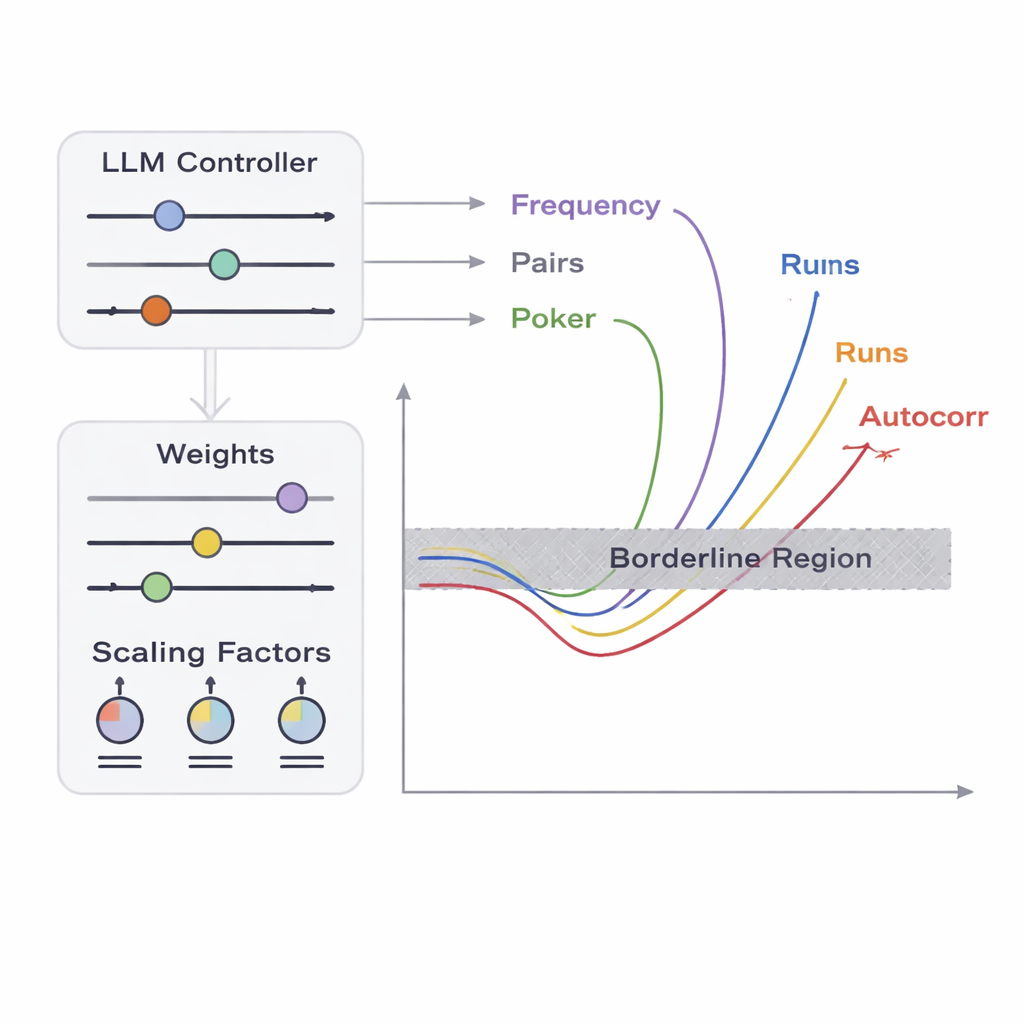
How close to perfect randomness can flawed data look?
To see whether their artificial flaws look realistic, the authors compare their generated sequences against widely used benchmarks. They compute both Shannon entropy and min‑entropy, measures of how unpredictable each byte appears, and find values around 7.6–8 bits per byte—very close to the theoretical maximum of 8 and similar to commercial hardware randomness sources and NIST’s own public randomness beacon. They also run the full NIST SP 800‑22 statistical test suite and observe that their borderline sequences pass and fail in almost the same pattern as genuine high‑quality random data. In other words, to standard tools these samples look essentially normal, even though they were deliberately engineered to sit near multiple failure thresholds. This makes them ideal “adversarial” inputs for checking how robust embedded randomness testers really are.
What this means for real‑world security
From a layperson’s viewpoint, this work offers a new way to safety‑check the random number machinery that underpins encryption. Instead of only testing devices with clearly broken or clearly healthy randomness, engineers can now bombard them with carefully crafted, almost‑good sequences that mimic subtle hardware faults or environmental drift. If a real‑time randomness tester misses these borderline cases, that signals a potential blind spot that should be fixed before the device is deployed in banking, secure communications, or blockchain systems. By using evolutionary search guided by a language model, the authors provide a practical tool for generating such demanding test data, helping push the hidden foundations of digital security toward higher levels of reliability.
Citation: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
Keywords: random number generators, entropy sources, evolutionary algorithms, large language models, cryptographic testing