Clear Sky Science · en
Fuzzy C-means clustering based vertical container stacking in container terminals
Why smarter container stacking matters
Every year, nearly a billion standardized metal boxes—shipping containers—move through seaports around the world. Getting those boxes on and off ships quickly is essential for keeping goods flowing and costs down. Yet a surprisingly simple issue slows things down: when the container you need is buried under the wrong ones, cranes must reshuffle the stack, wasting time and fuel. This paper explores a new, data-driven way to stack containers by weight that cuts down on this costly reshuffling, making ports faster and more reliable without needing more space or equipment.
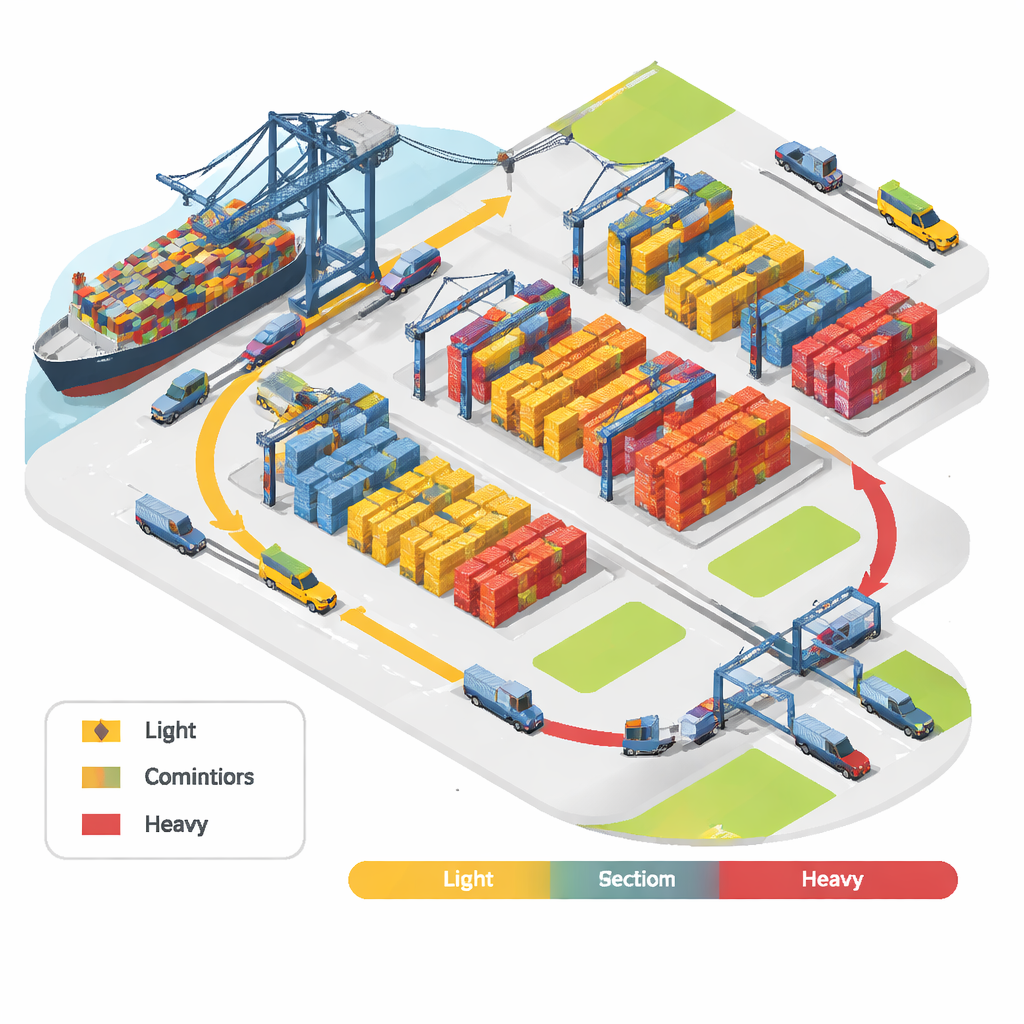
The hidden problem of messy piles
Container yards look orderly from a distance, but the sequence in which containers must be loaded and unloaded is highly uncertain. Outbound containers arrive at the terminal before a ship, and their exact loading order is influenced by ship stability rules and changing stowage plans. Heavier containers normally go lower in the ship, lighter ones higher. However, when containers arrive, operators often do not know whether a given box will count as “heavy” or “light” relative to the final load. Traditional strategies try to prioritize heavy containers or assign fixed weight categories, but this can easily backfire: a container classified as heavy one day might be considered medium the next, forcing extra reshuffles when the ship is loaded.
Vertical stacks and why weight balance counts
Ports use different ways to arrange containers: side by side in rows (horizontal), piled by similar type in columns (vertical), or a hybrid of both. This study focuses on vertical stacking, where containers with similar characteristics are placed in the same column-like stack. Vertical stacking is attractive because it makes it easier to reach a container of roughly the right weight range without disturbing too many others. But in reality the number of containers in each weight range changes from voyage to voyage. If weight groups are defined using rigid cut-off values—say, every 5 tons—many containers sitting near group boundaries end up in different stacks even though they are almost the same weight. That increases weight variation within stacks and reduces the gains from vertical stacking.
Letting the data draw the boundaries
The authors propose a new strategy called Fuzzy C-means-based Vertical Sequence Stacking, or FVSS. Instead of pre-deciding where the limits of each weight group should be, the method looks at historical weight data from ships on the same route and lets a fuzzy clustering algorithm find natural clusters. “Fuzzy” here means a container’s weight can partly belong to several groups, reflecting the fact that there is no sharp boundary between, for example, medium and heavy. The algorithm chooses how many clusters are best for each ship’s past data and identifies a weight center for each cluster. The yard is then pre-divided into a number of stacks proportional to how many containers typically fall in each weight group, and each stack is given a reference weight based on those centers.
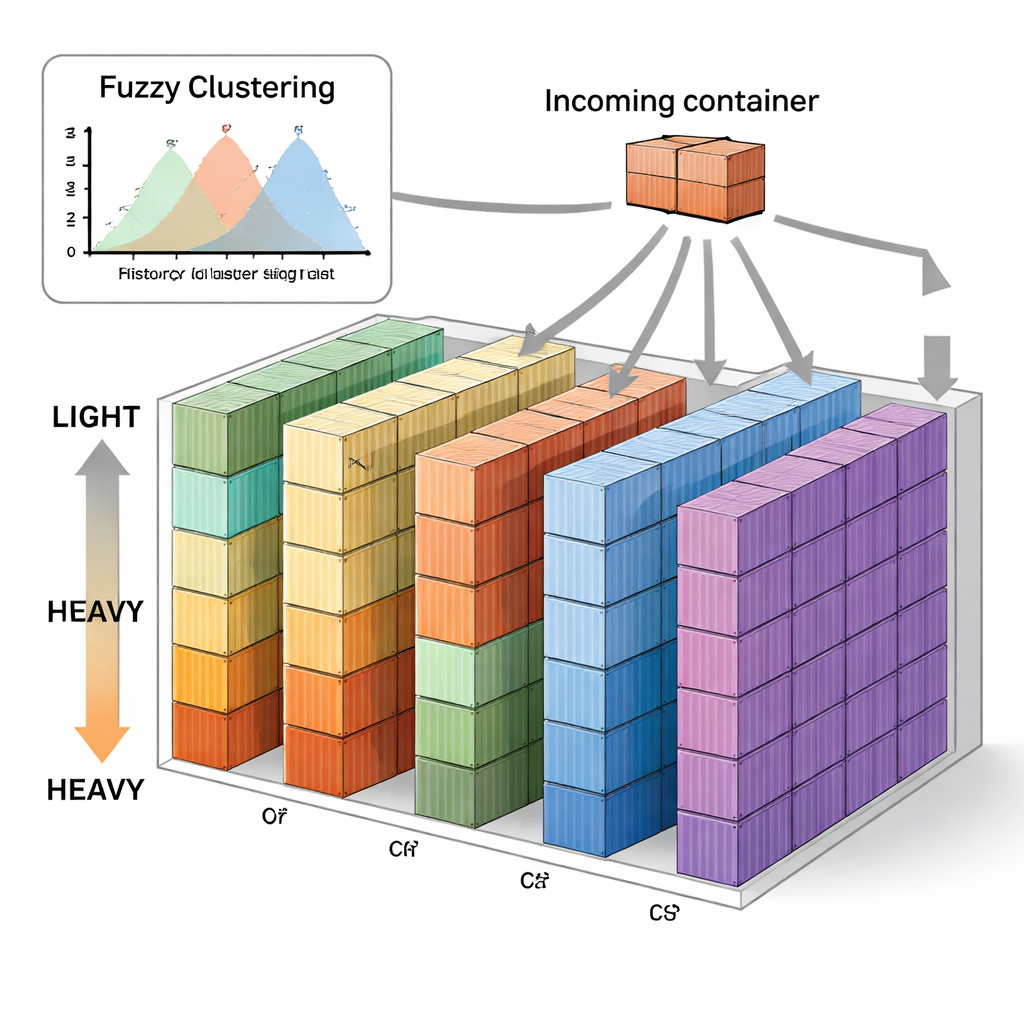
Simple rules for real-time decisions
Once the yard is set up this way, day-to-day operations follow a straightforward rule. As each container arrives, its approximate weight class is determined using the fuzzy clusters. If there is free space in stacks reserved for that class, the container goes there. If those stacks are full or several options are open, the system chooses the stack whose reference weight is closest to the container’s actual weight. Over time, this gently guides similar-weight containers into the same stacks without complex optimization or ongoing machine-learning training. The authors tested this approach on ten months of real data from Busan Container Terminal in Korea, comparing it against several well-known methods, including random stacking, a hybrid horizontal–vertical strategy, and earlier techniques based on Gaussian mixture models and online learning.
What the results mean for ports
The key measure in the study is how much the container weights vary inside each stack—a lower spread means that it is easier to find suitable containers during vessel loading with fewer reshuffles. Across multiple ships and two yard configurations (5 and 10 stacks), the FVSS strategy reduced weight variance much more than the competing approaches, with improvements of up to 78% compared with random stacking and substantial gains over other advanced methods. Crucially, the performance remained strong even when the researchers deliberately distorted container weights to mimic errors and last-minute changes. For port operators, this means they can achieve smoother crane operations and shorter ship turnaround times by relying on an automated but transparent rule set that is easy to update as new voyages are completed, without investing in heavy computing infrastructure or intricate learning systems.
Citation: Lee, S., Lee, SH., Choi, S.C. et al. Fuzzy C-means clustering based vertical container stacking in container terminals. Sci Rep 16, 6891 (2026). https://doi.org/10.1038/s41598-026-37994-x
Keywords: container terminals, yard stacking, fuzzy clustering, maritime logistics, operational efficiency