Clear Sky Science · en
Correcting noisy labels via comparative distillation: a domain adaptation approach
Why messy data is a growing problem
Modern artificial intelligence thrives on data, but that data is often wrong, incomplete, or inconsistently labeled. When labels are noisy—say, a cat photo tagged as a dog—learning systems can be misled, becoming less accurate and less reliable. This paper tackles that real‑world problem: how to train image recognition systems that still work well even when the training labels are flawed and the images come from different environments, such as online stores versus real‑world photos.
Learning across different worlds
In practice, AI models often learn from a “source” world where labels are carefully checked, then must perform in a “target” world where labels are scarce and error‑prone. For example, office objects photographed in a studio are neat and labeled correctly, while webcam or everyday photos of the same objects are messy and inconsistently tagged. Traditional domain adaptation methods try to bridge this gap by aligning the overall statistics of the two worlds. However, they usually assume that the target labels, when available, are correct—a risky assumption that breaks down in real applications with crowd‑sourced tags, low‑quality sensors, or automatic annotation tools.
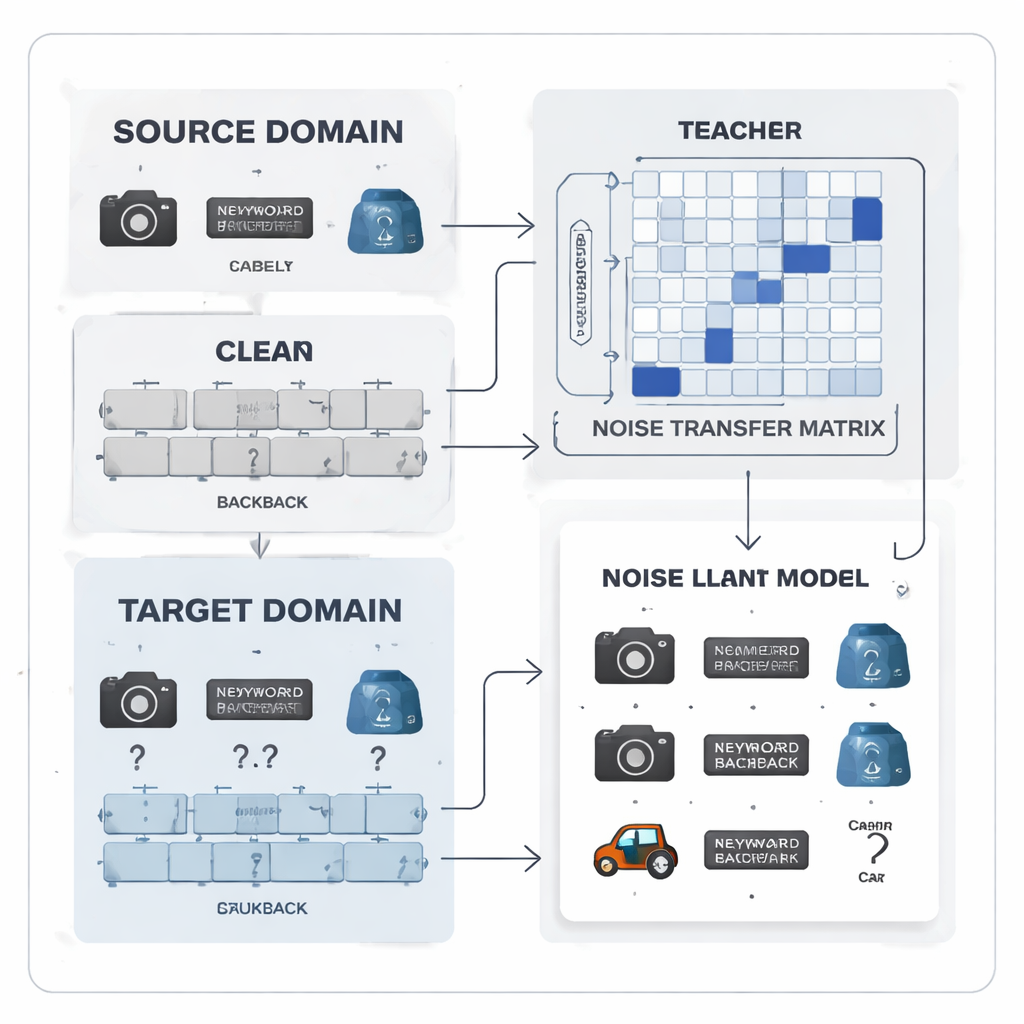
Turning label mistakes into a learnable pattern
The authors propose to treat label noise not as random chaos but as a learnable pattern. They introduce a “noise transfer matrix,” a table that captures how likely each true class is to be mislabeled as another. Instead of estimating this table from a handful of perfect “anchor” examples—which is unrealistic when labels are noisy and classes are imbalanced—the matrix is learned directly during training. To kick‑start learning, the method builds category “prototypes,” average feature fingerprints for each class extracted by a strong pre‑trained model. The similarity between these prototypes is used to initialize the matrix so that confusable categories, like similar office tools, are more strongly linked from the beginning, giving the system an early ability to correct labels.
Teacher–student teamwork for cleaner signals
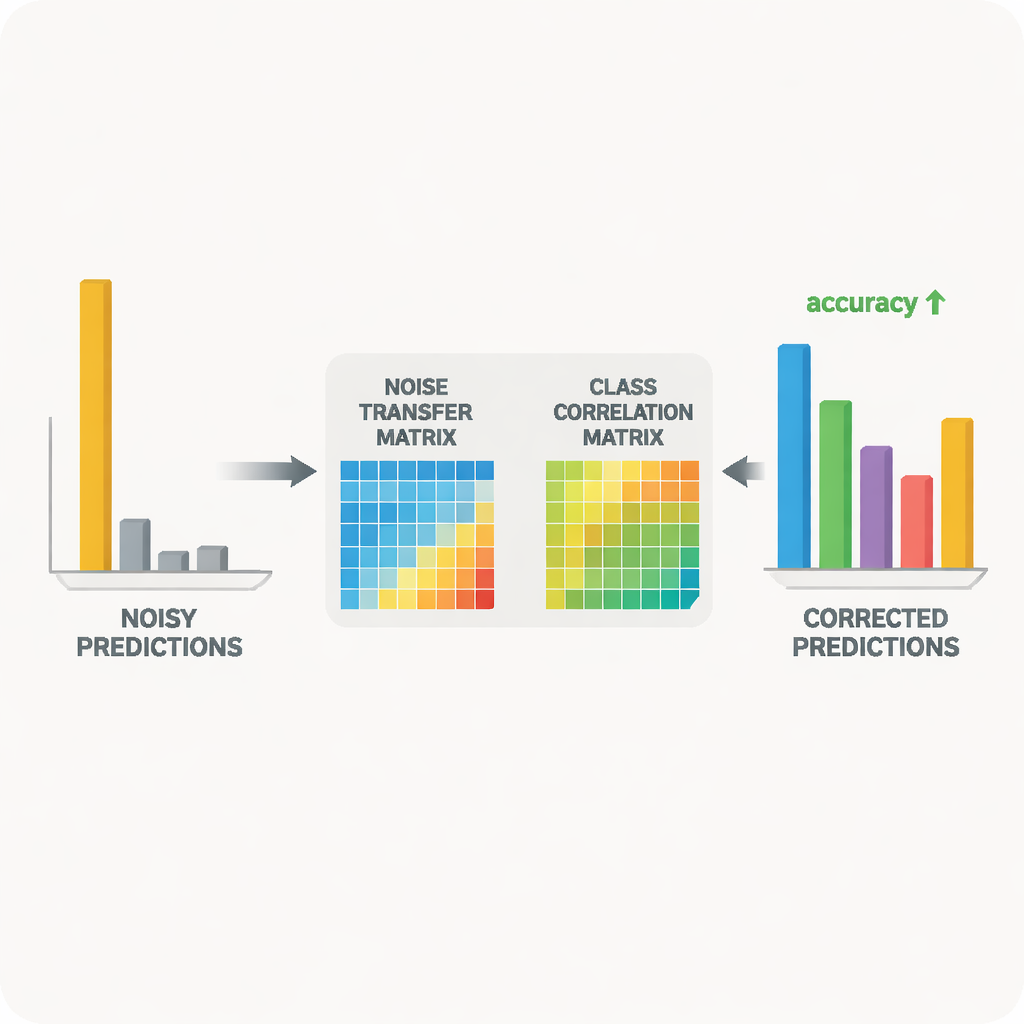
At the heart of the system is a teacher–student pair of neural networks. The teacher is based on a large self‑supervised vision model that has learned rich visual features from massive unlabeled data. The student is a lighter network that must perform well on the noisy target data. The teacher produces soft prediction scores that reveal how related different classes are; from these scores, the method constructs a class correlation matrix that summarizes which labels tend to co‑occur. This matrix acts as a guide, nudging the noise transfer matrix toward more realistic corrections. At the same time, the student is trained to match the teacher’s behavior through a process known as distillation, while contrastive learning encourages both networks to give similar internal representations to different augmented views of the same image and distinct representations to different objects.
Keeping corrections stable and avoiding overconfidence
Simply allowing the noise transfer matrix to change freely could make it unstable or overly sensitive to outliers. To prevent this, the authors use a mathematical trick based on singular value decomposition, which breaks the matrix into basic stretching directions. By penalizing the overall “volume” implied by these directions, the method discourages extreme distortions that would amplify noise. Another problem arises when the model becomes too sure of itself, assigning almost all probability to a single class; under such sharp predictions, it becomes hard to adjust mistaken labels. To address this, the method adds a form of entropy regularization, based on Tsallis entropy, that keeps prediction probabilities smoother. This makes it easier for the noise transfer matrix to partially reassign probability mass from an incorrect class to more plausible alternatives.
Proving the idea on real image collections
The researchers tested their approach on two widely used benchmarks for cross‑domain object recognition: Office‑31 and Office‑Home, which include images of everyday office items across multiple styles such as product photos, clip art, and real‑world snapshots. Across a variety of “train on one style, test on another” tasks, their method matched or exceeded leading algorithms, especially on the hardest cases where the shift between domains is largest. Detailed studies showed that each component—the volume control for the noise matrix, the class correlation guidance, and the entropy smoothing—contributed measurable gains. Visualizations of the learned matrix and of the feature space confirmed that, over training, mislabeled examples were gradually pulled toward their correct categories and that the source and target image distributions became better aligned.
What this means for everyday AI systems
To a non‑specialist, the key takeaway is that this work makes AI models more forgiving of human and machine mistakes in labeling data, particularly when those models must move from clean laboratory conditions to messier real‑world environments. By explicitly learning how labels tend to go wrong and using a powerful teacher model to guide corrections, the method can clean up noisy training signals and yield more accurate, more robust classifiers. Although the approach requires extra computation, it points toward a future where large, imperfect datasets collected “in the wild” can be harnessed more safely and effectively, reducing our dependence on painstaking manual annotation.
Citation: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
Keywords: noisy labels, domain adaptation, knowledge distillation, image classification, semi-supervised learning