Clear Sky Science · en
Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning
Teaching Robots to Be Cautious
Many of today’s most impressive robots and game-playing programs rely on reinforcement learning, a trial-and-error training process where software agents learn by collecting rewards. But these agents often chase the highest possible score while ignoring how risky their decisions are, leading to unstable learning and occasional crashes. This paper introduces a method called TDC-λ (Twin Distributional Critics with a Lambda Lower Confidence Bound) that teaches such agents not only to aim high, but also to stay reliably safe while they learn.
Why Stability Matters in Learning Machines
Standard continuous-control algorithms, such as the widely used TD3 and Soft Actor–Critic (SAC), have enabled robots to run, hop, and balance in complex simulators. However, these methods typically judge each action using a single number: an estimate of how much reward it will bring in the long run. That simple score can be misleading when the learning process is noisy, causing the system to overestimate how good certain actions really are. The result is a learning curve that may look strong on average but swings wildly from run to run, which is troublesome if the same algorithm is to control physical machines or safety-critical systems.
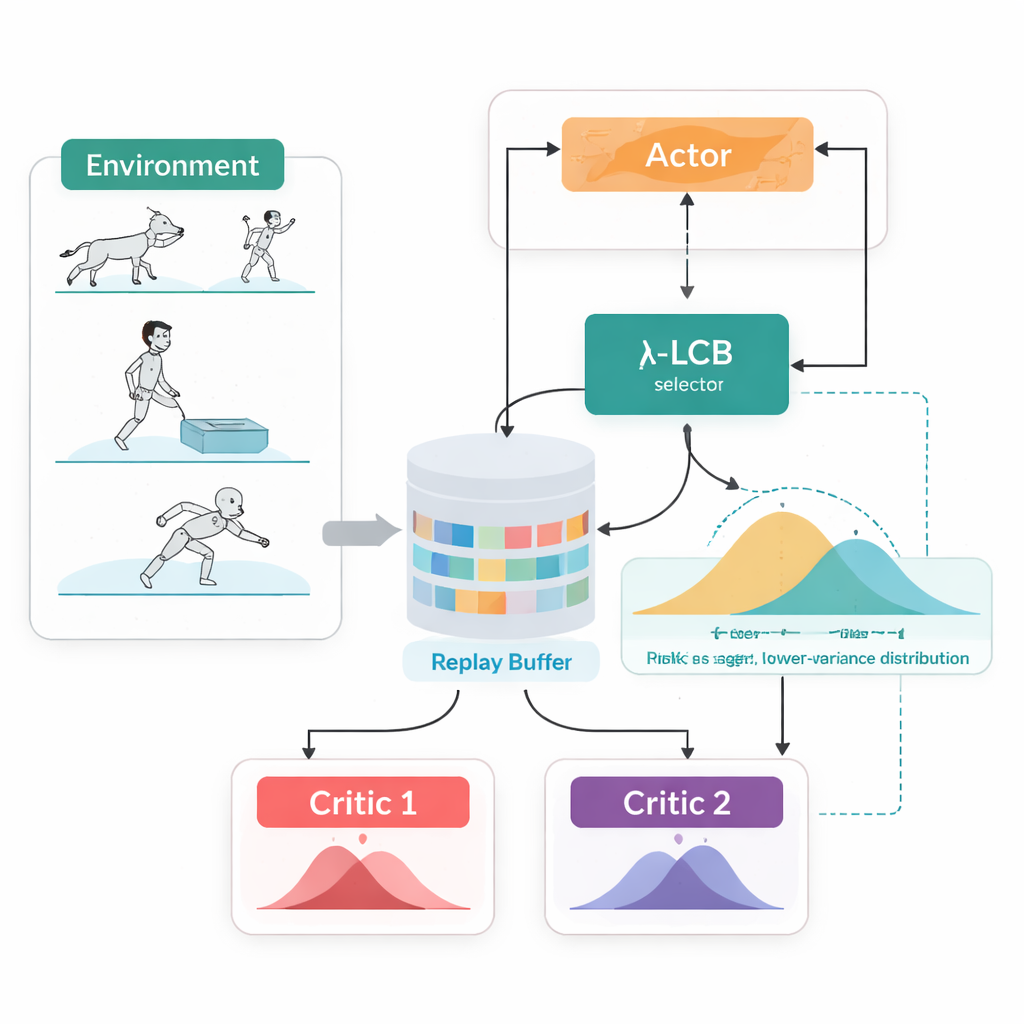
Looking at Full Futures, Not Single Numbers
TDC-λ addresses this problem by changing how the agent evaluates its future. Instead of predicting just one expected reward for each action, it learns two separate "critics" that each output a full distribution over possible future returns. From these distributions, the algorithm computes not only the average outcome but also how spread out the possibilities are. That spread reflects uncertainty or risk. Using a simple rule, summarized as a lower confidence bound, TDC-λ prefers the critic that predicts a safer outcome: one that may be slightly less optimistic but is supported by more consistent evidence. A single setting, the risk parameter λ, smoothly tunes how cautious this selection is—from behaving like a conventional TD3-style method when λ is zero to becoming more conservative as λ grows.
One Training Loop, Two Ways to Act
Another practical feature of TDC-λ is that it supports both deterministic and stochastic ways of choosing actions within one unified framework. During training, users can opt for a classic deterministic policy or a tanh-squashed Gaussian policy that samples actions, promoting exploration. Regardless of this choice, the twin distributional critics are trained in the same way, and evaluation always uses the deterministic mean action. This design takes advantage of earlier findings that deterministic behavior at test time often performs as well as or better than sampling, while still allowing rich, exploration-friendly policies during learning.
Putting the Method to the Test
The authors evaluated TDC-λ on five popular MuJoCo benchmark tasks where simulated robots like HalfCheetah, Hopper, Ant, Walker2d, and Humanoid must learn to move efficiently. Across these tasks, the new method matched or improved the final performance of strong baselines including TD3, DDPG, SAC, and an advanced flow-based approach called MEOW, while consistently showing lower variability across repeated runs. In harder, higher-dimensional tasks such as Humanoid, slightly higher values of λ—meaning more cautious target estimates—led to the best long-term returns and the tightest performance bands. Additional experiments in other simulators (PyBullet and NVIDIA Isaac) and diagnostics that track the variability of the learning signal reinforced the finding that TDC-λ makes learning more stable without slowing it down.
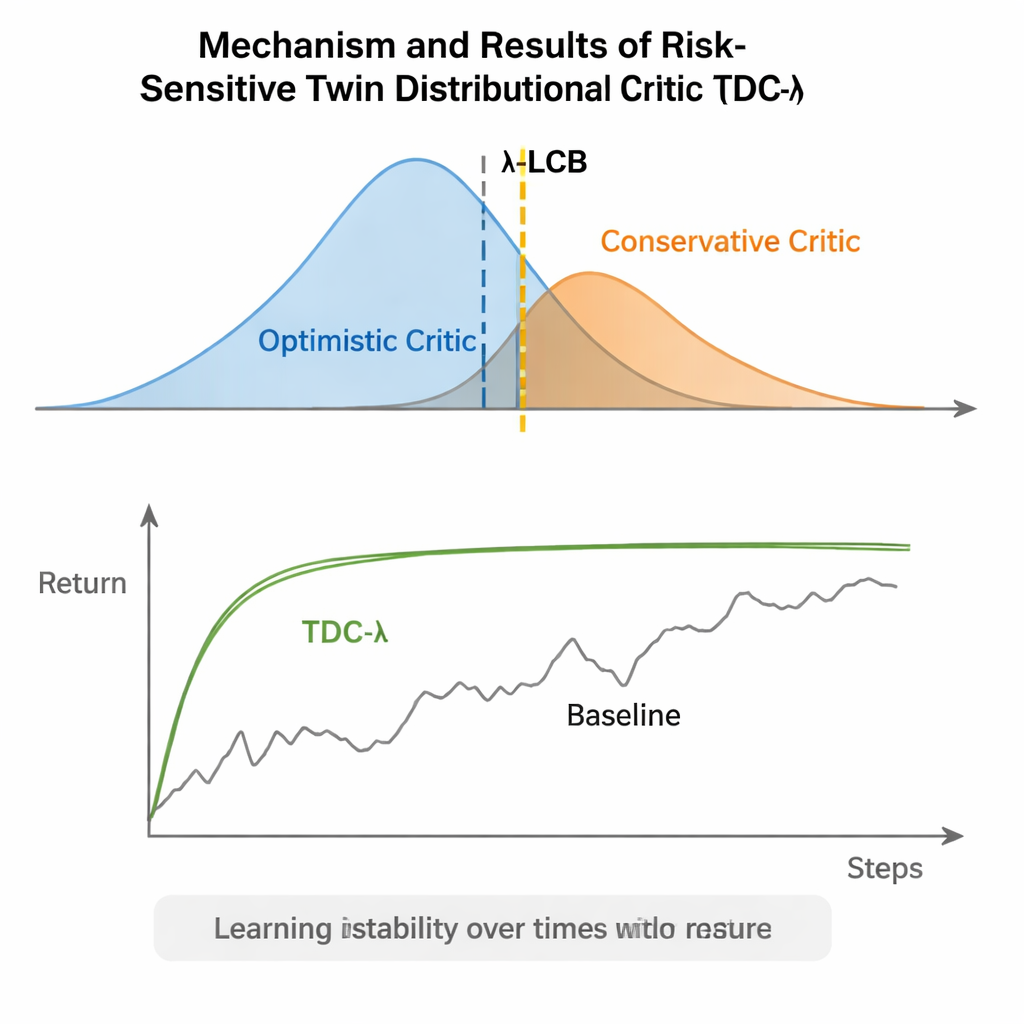
A Simple Knob for Safer Learning
In everyday terms, TDC-λ gives reinforcement learning systems a "safety margin" when deciding how much to trust their own optimism. By learning full distributions of possible outcomes and then leaning toward the safer critic using the λ knob, the algorithm reduces wild swings in training while preserving high final performance. For practitioners, this offers a practical way to build more reliable controllers for robots and other continuous-control systems: start with a moderately conservative λ and adjust it based on how volatile the learning process appears. The broader message is that carefully shaping what the agent learns from—its training targets—can deliver much of the robustness often attributed to more complex architectures, making advanced reinforcement learning both steadier and more accessible.
Citation: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
Keywords: reinforcement learning, continuous control, risk-sensitive learning, distributional critics, robotics