Clear Sky Science · en
Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets
Why your text messages still need protection
Most of us trust that unwanted texts will quietly land in a spam folder, but behind the scenes that is a very hard problem. Real spam is rare compared with everyday messages, and it increasingly appears in many languages at once. This paper presents a new way to spot dangerous SMS spam by blending powerful language models with a clever “fake data” generator, so filters can learn from far more examples of bad messages without putting your privacy at risk.
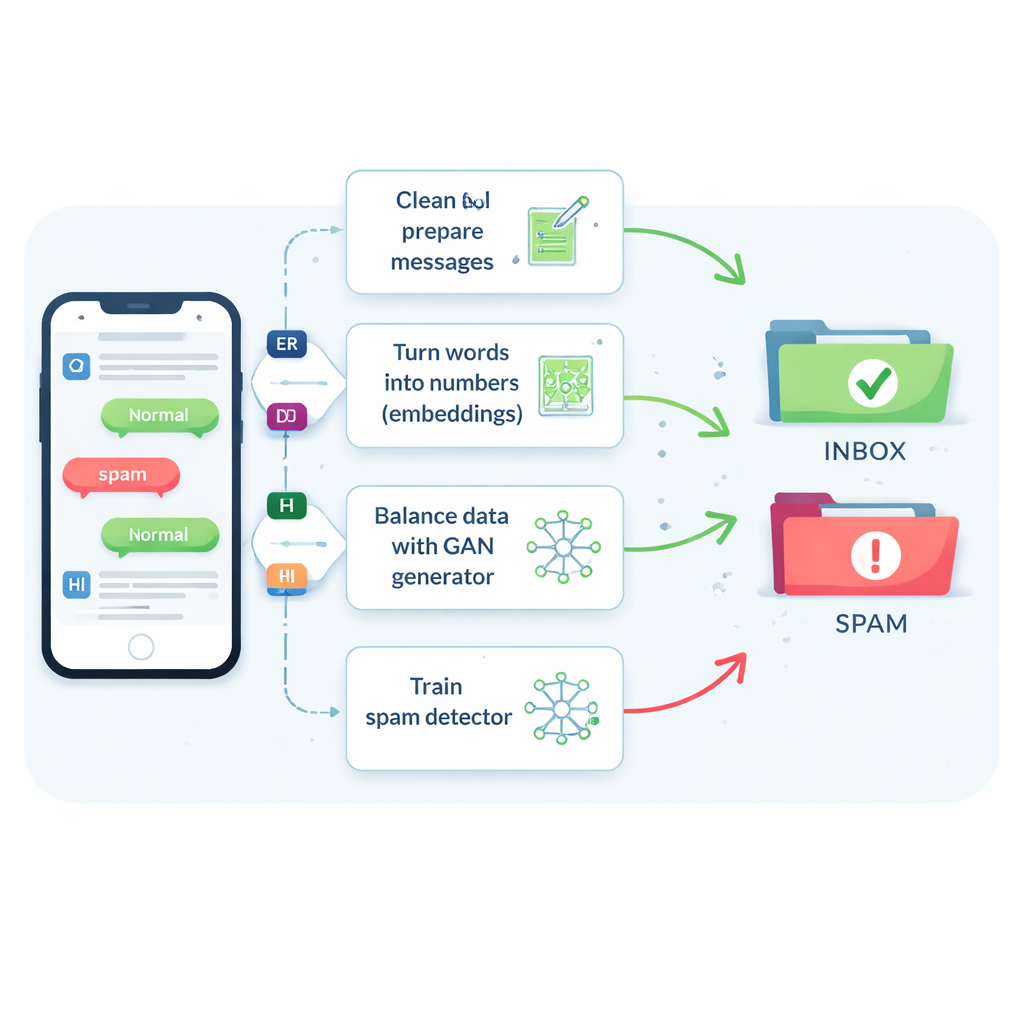
The problem with rare and shape-shifting spam
Spam texts make up only about one in seven messages, yet missing even a small fraction of them can expose people to scams, malware, and identity theft. Traditional filters struggle because SMS messages are short, filled with slang and abbreviations, and arrive in real time with little extra context. As a result, many systems lean toward calling messages safe, which keeps users happy but lets more harmful texts slip through. Older tricks that simply duplicate spam messages or invent new ones by tweaking the words can help a bit, but they often confuse the filter or create unrealistic examples that do not match what criminals actually send.
Teaching machines to understand message meaning
The authors start by comparing eight different learning algorithms, from familiar tools like support vector machines and decision trees to more advanced neural networks that read text as a sequence, such as long short-term memory (LSTM) networks. They also test five ways of turning words into numbers a computer can use. Simple counts of how often each word appears (known as bag-of-words or TF–IDF) are fast but blind to meaning. Newer “embeddings” like Word2Vec and GloVe place words with similar meanings near one another in a numerical space. Most advanced are transformer-based models such as BERT, which adjust a word’s representation depending on the surrounding sentence, helping the system tell apart, for example, a friendly reminder from a convincing scam.
Using smart “fake” spam to fix a lopsided dataset
The central innovation is how the study tackles the shortage of spam examples. Instead of generating full fake sentences, the team trains a type of neural network called a Generative Adversarial Network (GAN) directly on the numerical embeddings of spam messages. One part of the GAN, the generator, learns to create synthetic spam-like points in this high‑dimensional space, while another part, the discriminator, learns to tell them from real ones. Through this rivalry, the generator produces realistic new spam embeddings that expand the training set. A quality check based on similarity ensures only synthetic examples that closely resemble genuine spam are kept, reducing the risk of nonsense data that could mislead the classifier.
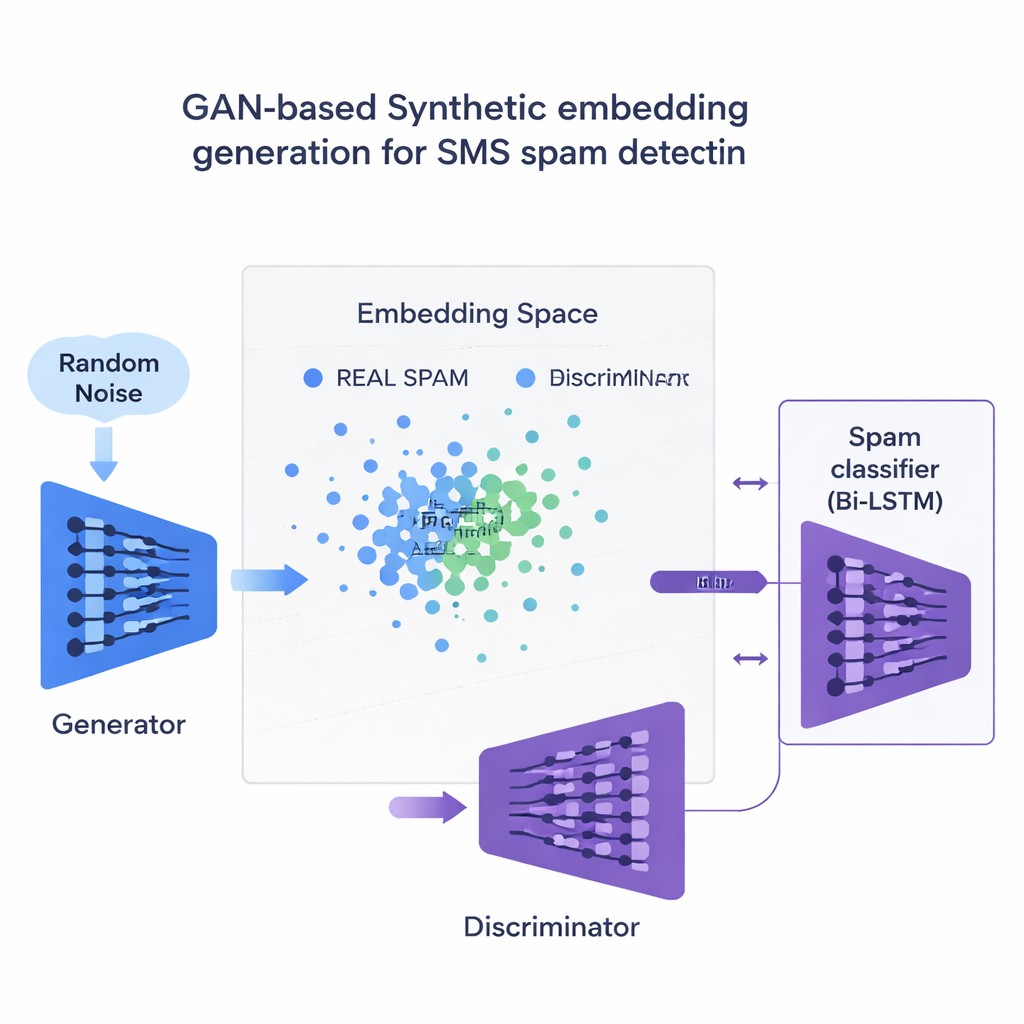
Results across languages and devices
The researchers test 120 different combinations of models, embeddings, and data-balancing methods, both on an English SMS dataset and on a multilingual version translated into French, German, and Hindi. Across the board, contextual embeddings like BERT outperform older word-count approaches. The best setup—a bidirectional LSTM fed with BERT embeddings and trained with GAN-generated spam examples—reaches an F1-score around 97.6% on English messages and 94.4% on the multilingual set, edging past existing state-of-the-art systems. Crucially, it does this while keeping false alarms extremely low, an important requirement so one-time passwords and bank alerts are not mistakenly hidden from users. The study also compares this GAN strategy with more common balancing tools like SMOTE and ADASYN, finding that the GAN produces cleaner, more realistic training data and slightly better overall performance.
What this means for everyday users
For non-specialists, the takeaway is that spam filters are starting to understand the meaning and context of your messages, not just individual words, and can be “taught” with carefully crafted synthetic data rather than seeing more of your real texts. By working directly in the space where message meaning is encoded, the proposed method gives security systems a richer picture of how spam looks in many languages, without flooding them with clumsy fakes. This makes it more likely that dangerous messages are caught and genuine ones are delivered, offering a stronger, more adaptable shield for mobile users as scammers keep changing tactics.
Citation: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Keywords: SMS spam detection, GAN data augmentation, BERT text embeddings, multilingual cybersecurity, mobile phishing