Clear Sky Science · en
A lightweight convolutional neural network architecture for violence detection in video sequences
Watching Crowds So Humans Don’t Have To
From concerts and sports arenas to subway stations and shopping malls, cameras now watch almost every crowded space. Yet most of those video feeds are still monitored by tired human eyes that can easily miss the first signs of a fight or stampede. This paper explores how a slim, fast form of artificial intelligence can scan live video for violent behavior in real time, even on low‑cost hardware, helping security staff respond quickly before situations spin out of control.
Why Spotting Violence on Video Is So Hard
At first glance, asking a computer to tell “fight” from “no fight” sounds simple: just detect people hitting each other. In reality, the problem is messy. Lighting can be poor or change suddenly, crowds can block the view, and cameras are mounted at many different angles. A packed rock concert looks chaotic even when nothing dangerous is happening, while a boxing match looks violent but is perfectly normal inside a ring. Traditional vision systems looked at hand‑crafted motion patterns and edges frame by frame, and while they worked in the lab, they were often too slow or too inaccurate for busy, real‑world surveillance networks.
A Leaner Brain for Camera Feeds
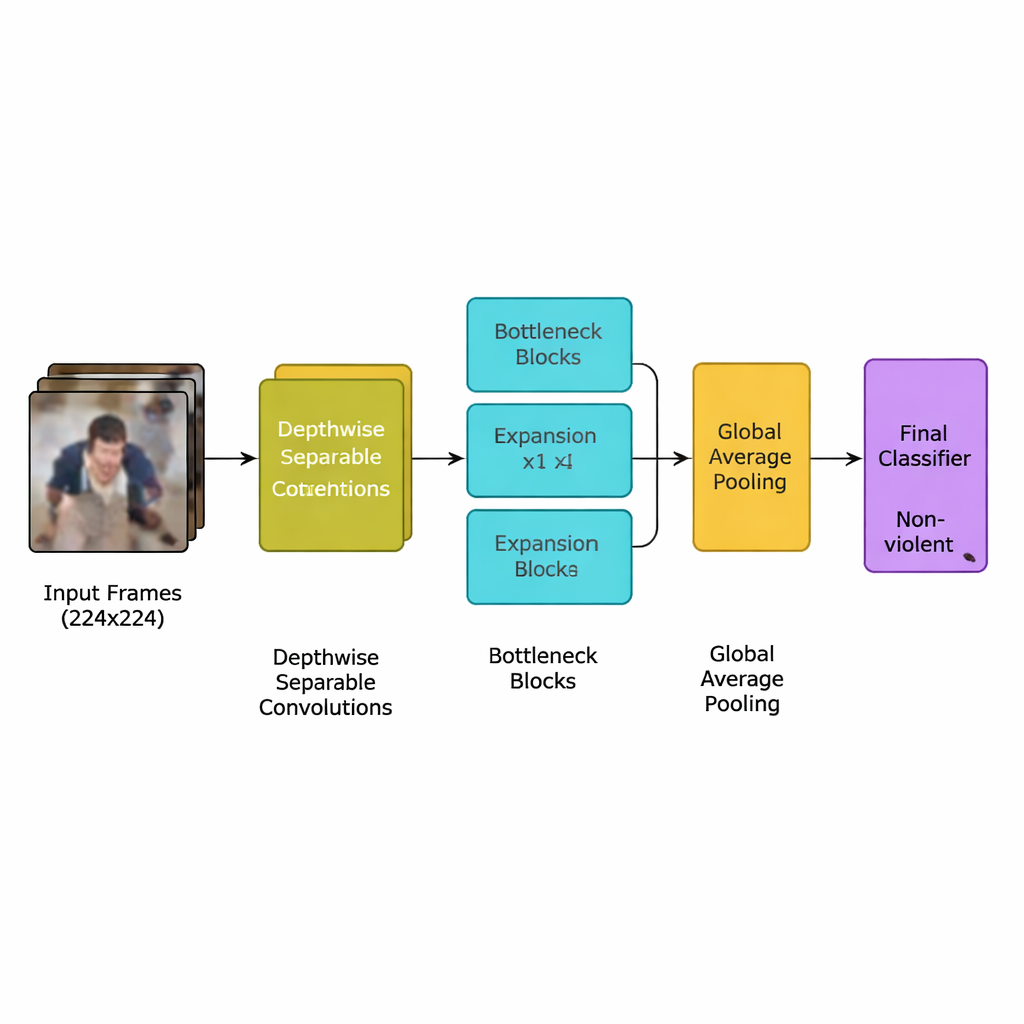
The authors present a new deep‑learning model designed specifically for this task: a lightweight convolutional neural network (CNN) derived from an efficient family of models known as MobileNetV2. Instead of using many heavy layers that demand powerful graphics processors, the network relies on depthwise separable convolutions—small, targeted computations that drastically cut the number of calculations. It also uses “inverted bottleneck” blocks, which briefly expand and then compress information to keep important motion cues while dropping redundancy. On top of this, the team adds an attention mechanism called squeeze‑and‑excitation, which helps the network focus on motion patterns in space and time that are most typical of violent incidents, while ignoring distracting background details.
From Raw Video to Violence Alerts
The full system follows a clear pipeline. First, video streams are broken into frames, and only every fifth frame is kept to remove near‑duplicates while preserving sudden movements that often signal a fight. Frames are resized to a standard 224×224 pixels, gently blurred to reduce background noise, and then randomly flipped or rotated during training so the model learns to cope with different camera viewpoints. These prepared images feed into the lightweight CNN, which gradually converts raw pixels into higher‑level patterns of crowd behavior. After a final pooling step that summarizes each frame, a small classifier outputs a simple decision: violent or non‑violent. Because the model uses only about 1.94 million parameters—less than its MobileNet and MobileNetV2 ancestors—it can run in real time on modest devices placed near the cameras rather than in a distant data center.
Putting the System to the Test
To find out whether this compact design could compete with bulkier networks, the researchers trained and evaluated it on two widely used benchmarks. The Real‑Life Violence Situations Dataset contains 2,000 short clips scraped from YouTube showing both everyday scenes and real fights in varied locations. The Hockey Fight Dataset offers 1,000 clips of professional hockey games, split between ordinary play and on‑ice brawls. On these datasets, the proposed model correctly labeled around 97 percent of clips in real‑life scenarios and 94 percent in hockey footage, matching or beating larger CNNs such as InceptionV3 and VGG‑19 while using far fewer computations. Cross‑testing between the two datasets—training on one and testing on the other—showed that the system still performed reasonably well, suggesting it captures general motion patterns rather than memorizing a single environment.
What This Means for Everyday Safety
For non‑experts, the key takeaway is that it is now possible to build camera systems that automatically flag likely violence quickly and cheaply, without needing giant servers or constant human attention. The study shows that a carefully trimmed and tuned neural network can watch many streams at once, send alerts when it detects dangerous behavior, and still run on low‑power hardware suitable for public transport hubs, schools, hospitals, and city streets. While challenges remain—such as handling very dark scenes, heavy crowding, or adding sound cues—the work points toward a future where smart cameras act as tireless early‑warning sensors, helping security teams protect people more effectively while reducing the burden on human watchers.
Citation: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Keywords: violence detection, video surveillance, lightweight CNN, MobileNetV2, public safety