Clear Sky Science · en
MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos
Swallowing a Camera, Drowning in Images
Imagine diagnosing gut diseases by swallowing a vitamin-sized camera that quietly photographs your entire digestive tract. Wireless capsule endoscopy already makes this possible, but each exam produces around 55,000 images, most of which look almost the same. Doctors must sift through this visual flood to spot tiny patches of bleeding, inflammation, or tumors. The study behind MSRCTNet asks a simple but crucial question: can an intelligent system safely throw away the look‑alike frames, so physicians see only what really matters?
Why Too Many Pictures Can Be a Problem
Conventional endoscopy requires a flexible tube passed through the mouth or rectum, a procedure many patients find unpleasant and that cannot always reach the entire small intestine. Capsule endoscopy solves this by letting a pill‑camera drift through the gut, snapping pictures every second. The downside is overload: only about 1% of frames carry clearly useful information, while the rest mostly repeat the same folds of tissue. Reviewing such volumes is slow and tiring, raising the risk that an exhausted clinician might miss a subtle lesion. Earlier computer methods tried to help by clustering similar frames, compressing data, or relying on simple color and texture cues, but they often failed when lighting changed, the intestine moved in complex ways, or rare abnormalities appeared in only a handful of examples.
A Smarter Way to Spot Repetition
MSRCTNet (Multi‑Scale Capsule Triplet Network) is a deep‑learning system designed to act as an intelligent filter for capsule videos. Rather than treating each image as a flat picture, the system looks at patterns at multiple sizes simultaneously—fine textures of the gut lining and broader shapes of the intestinal wall—while using an attention mechanism to emphasize the most informative details. These enriched features are then passed into a capsule‑style layer that preserves how parts of the image relate to each other in space, such as the orientation and arrangement of folds or lesions. Finally, a specialized similarity module compares triplets of frames—one reference image, one that should be similar, and one that should be different—to learn a representation in which truly redundant frames cluster tightly together and distinctive frames stand apart.
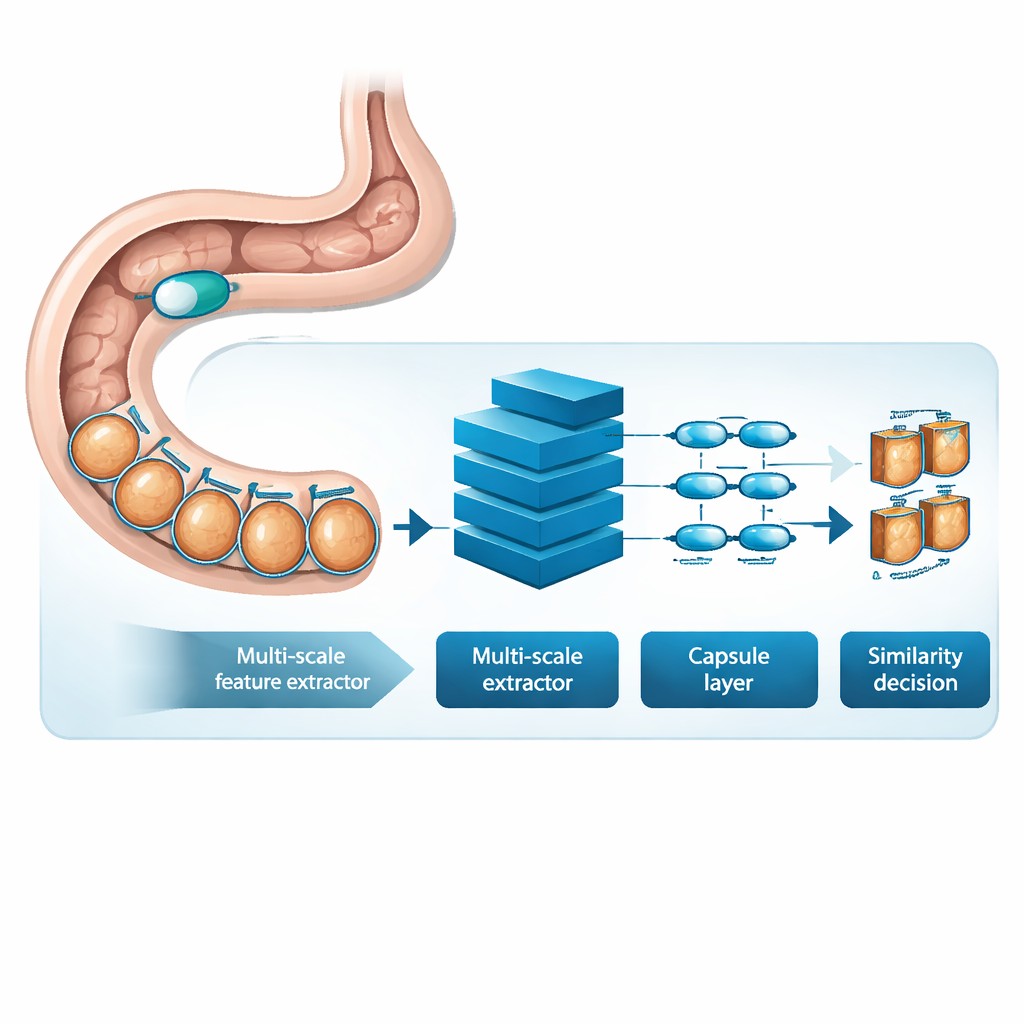
Learning from Real Patient Exams
To test MSRCTNet, the researchers assembled a large dataset of 257,362 images from 60 capsule exams performed at a hospital in China. The pictures included normal tissue, bubble‑obscured regions, and clear abnormalities such as bleeding and inflammation, all labeled by experienced clinicians. The system was trained to judge whether pairs of frames were similar or not, using a combination of two learning goals: one that pulls together frames from the same category and pushes apart those from different categories, and another that teaches the network to say directly whether a pair is similar. Once trained, the model reviews a video three frames at a time and decides which of the neighboring images are truly redundant. By applying simple rules to these similarity decisions, it discards repeated views while keeping representative keyframes.
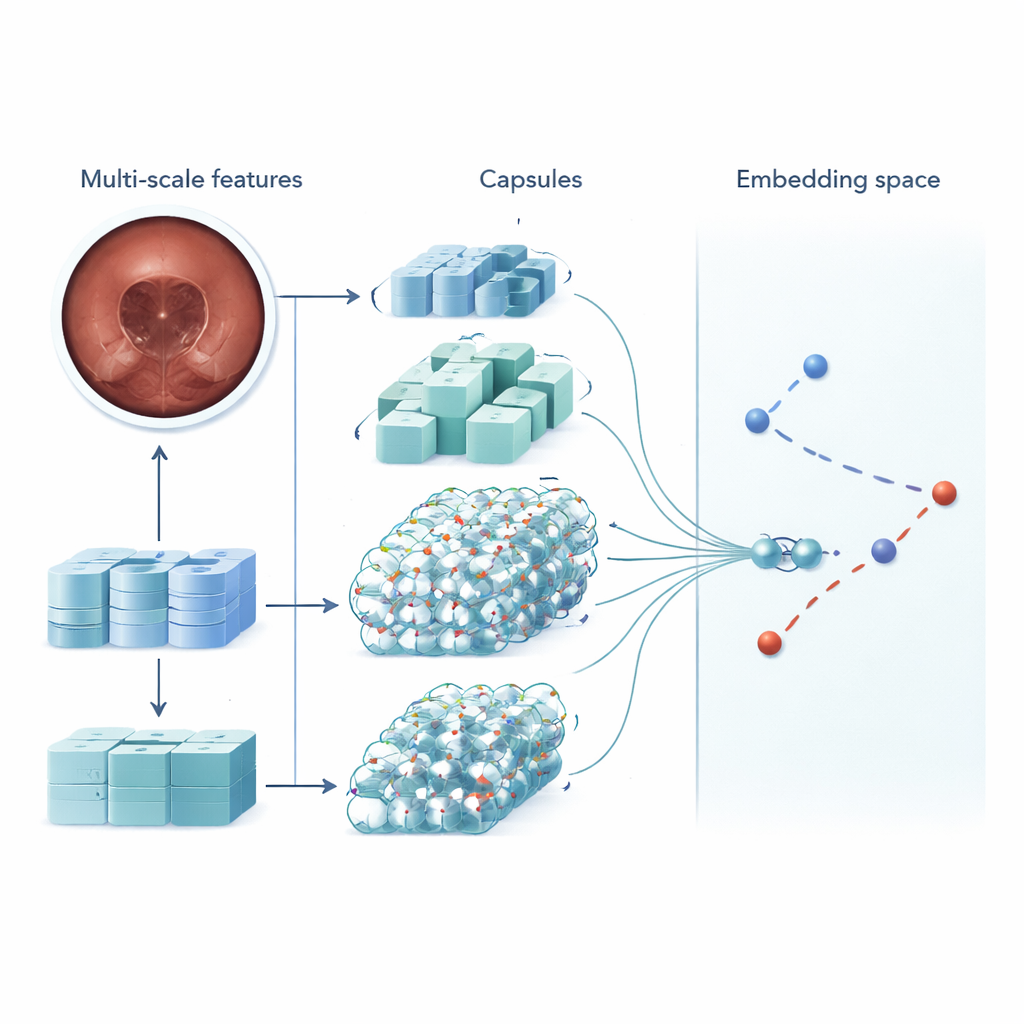
Speed, Accuracy, and Fewer Missed Problems
On the test data, MSRCTNet correctly handled frame redundancy in about 96% of cases, with a false alarm rate under 3% and a missed‑frame rate below 0.2%. In practice, for a 50,000‑frame exam this corresponds to missing fewer than 100 potentially relevant frames—small enough that surrounding images still provide context at six frames per second. Compared with several earlier techniques based on clustering, motion analysis, or simpler neural networks, MSRCTNet was both more accurate and more robust when the data were unbalanced, meaning when normal images vastly outnumbered rare lesions. The system also ran fast: roughly 0.02 seconds per frame, or about 15 minutes to shrink a full exam down to around 2,500 keyframes, a volume much more manageable for human review.
What This Means for Patients and Doctors
For patients, the advance described in this paper does not change the capsule they swallow, but it could make their exam more effective. By automatically trimming away near‑duplicate images without hand‑tuned thresholds or fragile heuristics, MSRCTNet allows clinicians to focus their attention on a concise, information‑rich summary of the journey through the gut. The approach preserves clinically important findings while reducing fatigue and time at the reading console, potentially making noninvasive capsule exams more attractive and widely used. In essence, the method turns a torrent of pictures into a carefully curated highlight reel, bringing the promise of artificial intelligence one step closer to everyday digestive‑disease care.
Citation: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Keywords: wireless capsule endoscopy, medical video summarization, deep learning, redundant frame removal, gastrointestinal imaging