Clear Sky Science · en
Hyperparameter optimization to enhance the performance of deep learning models for the early detection of invasive turtles in Korea
Why smarter turtle spotting matters
Freshwater turtles may look harmless basking on a rock, but when non‑native species take over rivers and ponds, they can quietly push local wildlife toward extinction. Korea now faces this problem with several invasive turtle species that are spreading through trade and releases from the pet market. The study summarized here shows how fine‑tuning artificial intelligence—specifically deep learning models—can make automatic turtle detection faster and more accurate, giving conservationists a powerful new tool for early warning before ecosystems are irreversibly damaged.
Unwelcome guests in local waters
Invasive turtles such as the red‑eared slider have been introduced across Asia through the global wildlife trade. Once released, they compete with native animals for food and basking sites, may spread diseases, and often cope better with warming temperatures than native species. Korea manages six freshwater turtle species as invasive or high‑risk. Finding them early is essential, but traditional monitoring depends on experts visiting many wetlands and then carefully checking photographs—work that is accurate but slow and limited in scope. As drones, camera traps, and citizen‑science platforms like iNaturalist produce more and more images, automatic image analysis has become essential to keep up.
Teaching computers to recognize turtles
The researchers set out to build a deep learning model that could both locate invasive turtles in photos and tell the six species apart. They gathered thousands of citizen‑science images from iNaturalist and carefully rechecked each one, removing misidentifications and poor‑quality shots. For every usable image, they drew a box around each turtle so the model could learn where turtles appear and what they look like. The final dataset was split into training, validation, and test sets, and included varied lighting, backgrounds, and viewing angles to ensure the model would be robust to real‑world conditions.
Finding the best way to train the model
The team used a popular object‑detection framework called YOLO11, choosing a compact version that balances speed and accuracy. But instead of accepting the software’s default training settings—originally tuned on everyday objects like cars and cups—they asked a simple question: could they do better for turtles? First, they compared six different “optimizers,” the routines that adjust the model’s internal weights as it learns. Two of these performed poorly or became unstable, while a classic method called stochastic gradient descent (SGD) gave the most reliable improvements and highest scores on a held‑out set of images.
With the best optimizer chosen, the researchers then tackled 16 training settings, or hyperparameters. These control how quickly the model learns, how strongly it avoids overfitting, and how images are randomly altered during training to improve generalization. Using a random search strategy—testing 300 different combinations sampled from reasonable ranges—they hunted for a configuration that maximized overall detection and classification performance. Key settings shifted notably: the importance of getting the species label right was increased, regularization was strengthened to reduce overfitting, brightness changes in data augmentation were toned down, and a complex image‑mixing technique was used less often so the artificial images stayed closer to real photographs.
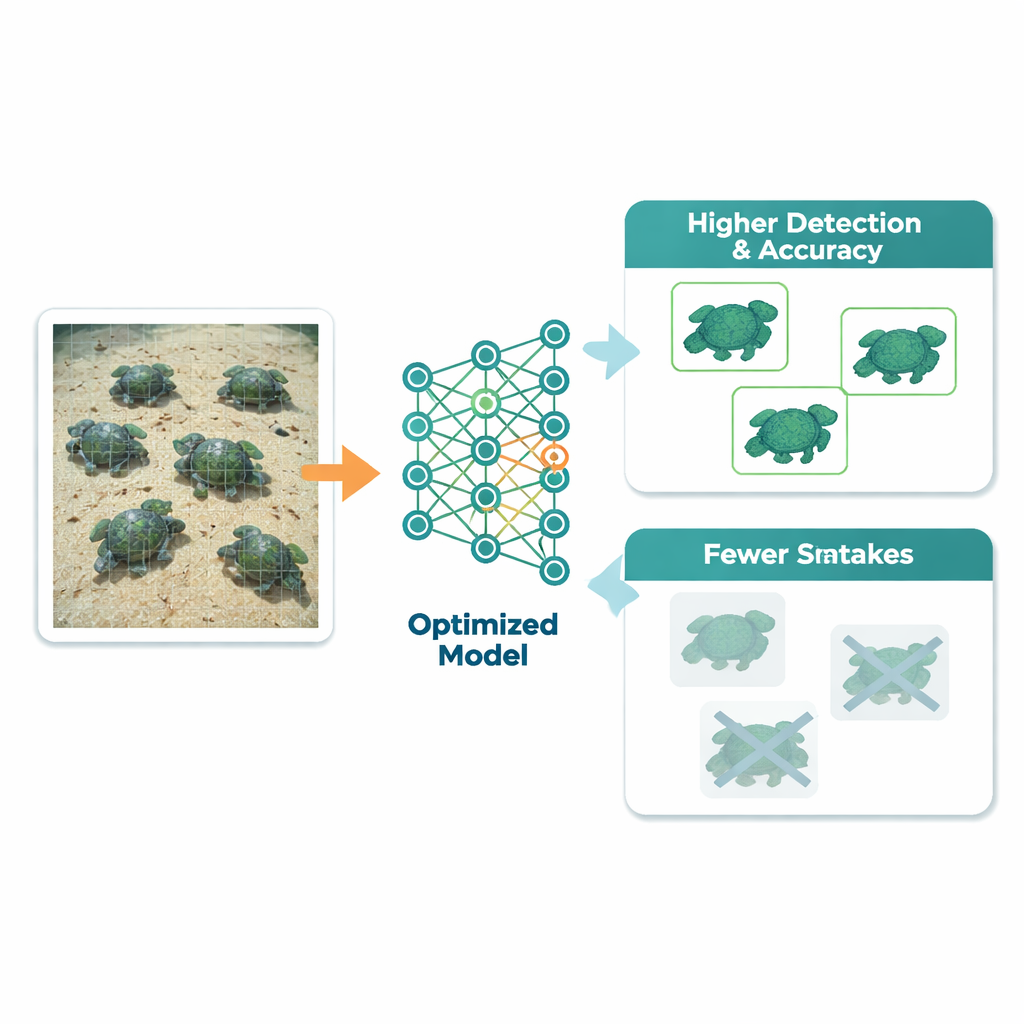
Sharper eyes, fewer mix‑ups
When the dust settled, the optimized model clearly outperformed a version trained with standard defaults. For measuring how well the system finds and correctly labels turtles, the study used a score called mean average precision. At a commonly used matching threshold, this score rose from 0.959 to 0.973, and across a tougher range of thresholds it climbed from 0.815 to 0.841. Overall species‑level classification accuracy increased from 89.9% to 92.7%. Particularly striking was the reduction in confusion between look‑alike species: for example, one turtle that was frequently misread as another in the default model was much more often correctly identified after tuning. These gains came with almost no extra training time and only a tiny slowdown when processing new images.
What this means for protecting wildlife
To a non‑specialist, the numbers mean that computers are getting noticeably better at spotting the right turtles in cluttered, real‑world pictures, and at telling tough species apart. By carefully choosing how the model learns—rather than relying on generic settings—the authors show that early detection systems for invasive species can be made more accurate without collecting new data or building entirely new algorithms. Deployed on camera traps, drones, or citizen‑science photo streams, such optimized models could alert managers sooner when invasive turtles appear or spread, helping protect native wildlife and the health of freshwater ecosystems.
Citation: Baek, JW., Kim, JI., Mun, MH. et al. Hyperparameter optimization to enhance the performance of deep learning models for the early detection of invasive turtles in Korea. Sci Rep 16, 7561 (2026). https://doi.org/10.1038/s41598-026-37636-2
Keywords: invasive turtles, deep learning, wildlife monitoring, hyperparameter optimization, biodiversity conservation