Clear Sky Science · en
DNS fingerprint based on user activity
Why your web visits leave a hidden trail
Every time you browse the web, your computer quietly asks a special kind of address book, called the Domain Name System (DNS), how to reach each site. Those questions don’t just vanish. Over days and weeks, they form a pattern of which kinds of sites you visit, when, and how often. This paper shows that those patterns are distinctive enough to act like a behavioral fingerprint, allowing powerful algorithms to tell users apart—even if their visible IP address changes—raising both opportunities for security and serious questions about privacy.
The internet’s phone book and your habits
DNS exists to translate human-readable web addresses, like www.google.com, into the numeric IP addresses that computers use to talk to one another. Most people never think about it, but every search, video stream, email check, or app update triggers one or more DNS queries. These queries are typically handled by local or public DNS servers and logged as simple records: which IP address asked about which domain, and when. Collect enough of these records and you get a detailed picture of what kinds of online services a user relies on, from business tools and cloud storage to social networks and streaming platforms. While earlier research used these traces to spot malware or identify device types, this study asks a more direct question: can they pinpoint individual users or machines purely from their recurring DNS behavior?
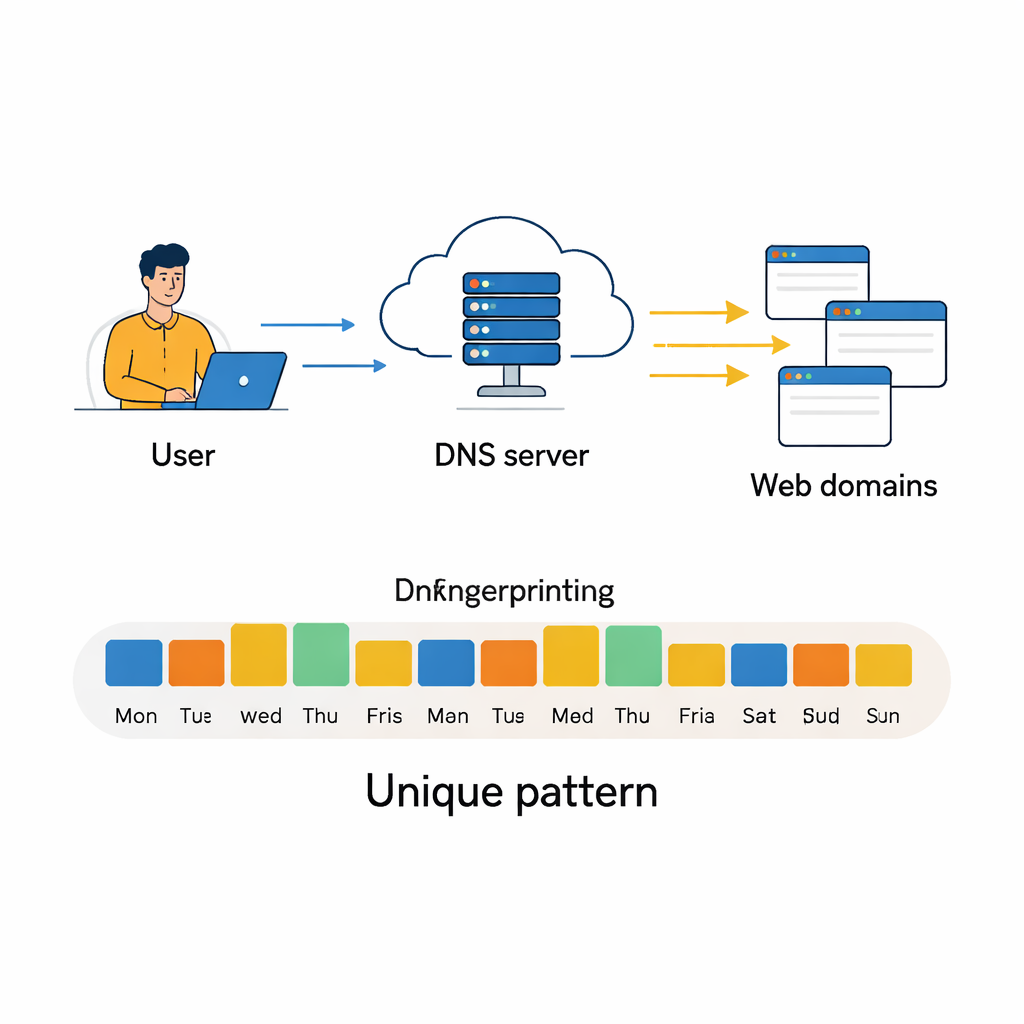
Turning daily clicks into a behavioral fingerprint
The authors build on a large, publicly available DNS dataset collected from a local internet provider over three months. Each day, they aggregate DNS activity for every active IP address into a compact summary: counts of total queries, how many different domains were contacted, and, crucially, how those domains fall into 75 content categories such as “General Business,” “Software / Hardware,” or “Social Networking.” They keep only IP addresses that appear on at least 80 percent of days, ensuring enough history per user, and carefully remove redundant or nearly empty features. They also apply statistical tools to detect highly correlated fields, filter out extreme outliers in query volume, and then compress the data with principal component analysis so that most of the useful variation is preserved in far fewer dimensions. Visualizing the cleaned data with a technique called t‑SNE, they find that many IP addresses form tight, well-separated clusters—an early sign that automatic classification may be feasible.
Putting machine learning models to the test
With this processed dataset in hand, the team treats user identification as a massive classification problem: given one day of DNS statistics, decide which of 1,727 IP addresses it belongs to. They compare a suite of models, from classic methods like Naive Bayes and Random Forests to more advanced tools such as XGBoost and deep neural networks. Each model is trained and validated on different versions of the data (raw, rescaled, standardized, or dimension-reduced) and evaluated by how often it correctly assigns the right class, along with measures of precision and recall. Traditional models perform reasonably well—Random Forests reach about 73 percent accuracy, and XGBoost exceeds 81 percent while correctly distinguishing more than 99 percent of all classes. But the standout performers are the neural networks, especially a custom convolutional neural network (CNN) that treats the feature vector like a one-dimensional image of daily behavior.
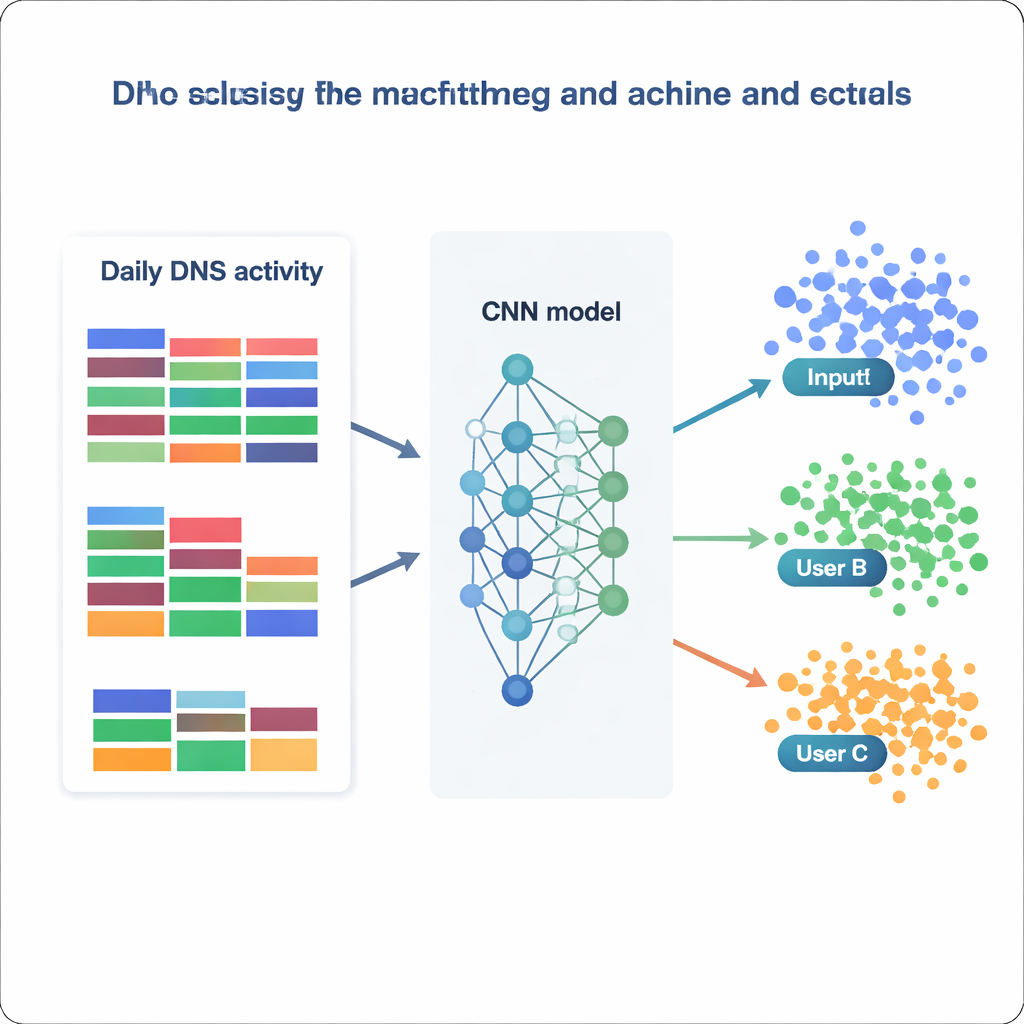
How well can a model know “who” you are?
The best CNN, trained on normalized data, correctly identifies the source IP on nearly 87 percent of held-out days and successfully predicts 1,694 of the 1,727 distinct IP addresses. In practical terms, this means that most users—or small groups hiding behind a shared IP—display stable, recognizable DNS patterns over time. By examining which features the models rely on most, the authors find two complementary strategies. Some models lean heavily on very common categories, such as general business or software services, capturing broad habits. Others, like XGBoost, gain extra power from rare but telling categories tied to security, politics, or niche interests. Together, these results show that even simple, aggregated statistics—without looking at the full list of domain names—can encode enough structure to re-identify users with striking reliability.
Promise, limits, and privacy stakes
For law enforcement and network defenders, DNS fingerprints could become a valuable tool for tracing repeat offenders, spotting compromised machines, or detecting botnets that use changing IP addresses to evade blocking. At the same time, the study highlights clear limits: DNS fingerprints are most stable when a public IP is tied to a single user, which is more realistic in modern IPv6 networks than in today’s IPv4 world where many users share one address via NAT. Frequent switching of DNS servers or public Wi‑Fi also weakens the signal. Most importantly, the work underlines a privacy risk that is hard for ordinary users to see. Because DNS logging is largely invisible and passive, behavioral tracking can happen without installing cookies or intrusive scripts. The authors release their dataset and models openly, arguing that transparent research is needed so that society can weigh the security benefits of DNS-based fingerprinting against its potential for silent surveillance and decide what protections and policies should govern this powerful new form of online identification.
Citation: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Keywords: DNS fingerprinting, user tracking, internet privacy, network security, machine learning