Clear Sky Science · en
Real-world face super-resolution based on generative adversarial and face alignment networks
Sharper Faces from Blurry Photos
Anyone who has tried to zoom in on a face from an old security video or a tiny social media picture knows the frustration: the more you enlarge, the more the face turns into a blocky blur. This paper presents a new artificial intelligence approach that can turn such low-quality real-world face images into much clearer ones, in a way that better preserves a person’s identity and expression. That has obvious implications for security cameras, photo forensics, and even everyday photo enhancement apps.
Why Blurry Faces Are So Hard to Fix
Making a small, fuzzy face image look sharp is not just a matter of “adding pixels.” Traditional methods relied on hand-crafted rules or simple patterns, and more recent deep-learning techniques often learned from artificially degraded images: take a clean high-resolution face, blur and shrink it, then teach a network to reverse the process. The problem is that real-world images—like those from surveillance cameras or compressed video—are degraded in messy, unpredictable ways. The blur, noise, and compression artifacts rarely match the neat synthetic examples used in training, so models that look great in the lab often fail on real footage. Worse, they can produce faces that look plausible but no longer resemble the original person.
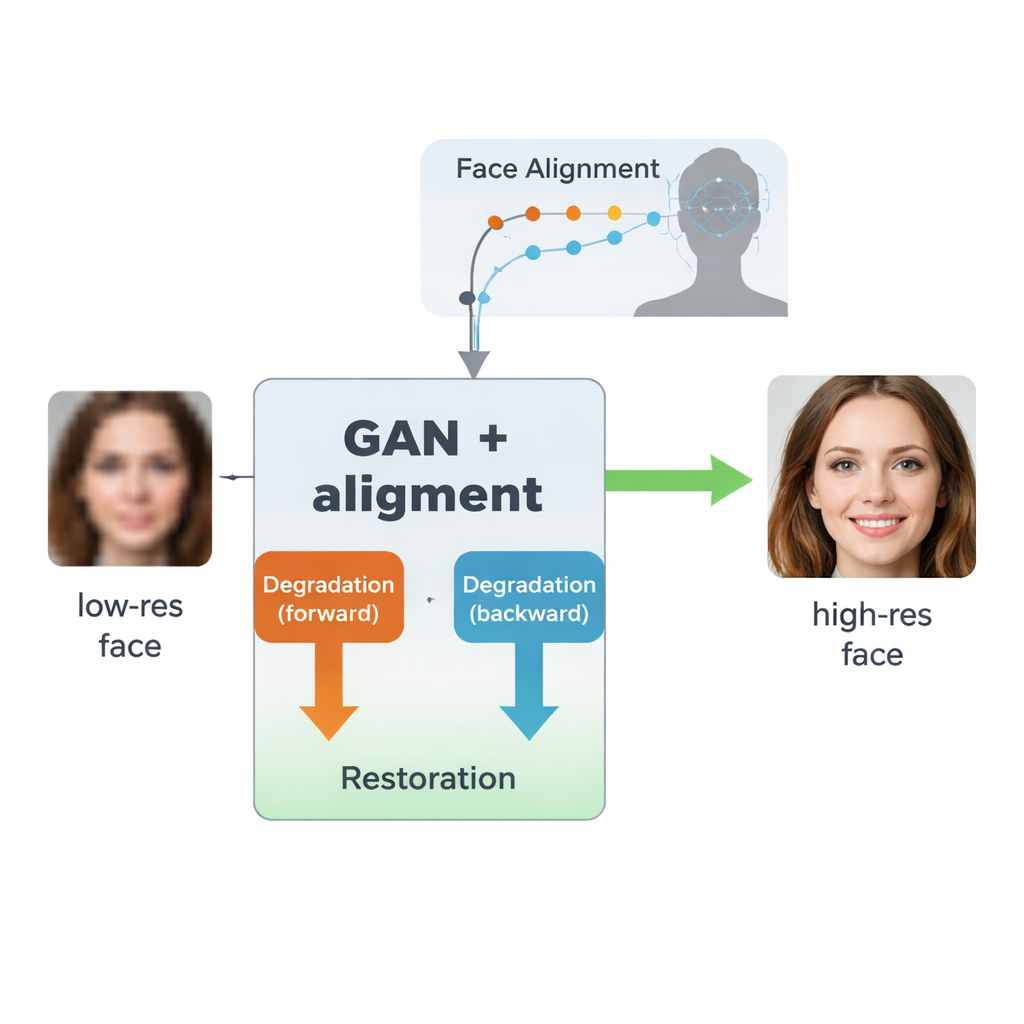
A Two-Way Learning Loop for Real-World Images
The authors build on a type of AI called a generative adversarial network (GAN), which learns to create realistic images by pitting two neural networks against each other: one generates images, the other judges how real they look. Their design, inspired by an earlier model called SCGAN, uses a “semi-cycle” structure with two complementary loops. In the forward loop, real high-resolution faces are intentionally degraded by one branch to produce synthetic low-resolution versions, then restored by a shared restoration branch. In the backward loop, truly low-quality real-world faces are enhanced by that same restoration branch and then degraded again by another branch to resemble real low-resolution images. By forcing consistency across both directions—degrade then restore, or restore then degrade—the system learns a realistic model of how faces get ruined in practice, and how to reverse that process without ever needing perfectly matched pairs of low- and high-quality real images.
Teaching the Network What a Face Really Looks Like
A key innovation in this work is to teach the system not just to make images look sharper, but to respect the underlying structure of a human face. To do that, the authors integrate a separate face alignment network, originally designed to locate landmarks such as the corners of the eyes, the tip of the nose, and the outline of the mouth. This alignment network predicts “heatmaps” that highlight where each landmark should be. During training, the model compares the heatmaps from the restored image with those from a real high-resolution face of the same person, and penalizes mismatches. Crucially, this uses a pre-trained alignment model and does not require manual landmark labels for every training image. The result is a kind of geometric guidance: the enhancement network is nudged to place eyes, nose, and mouth in the right positions and shapes, instead of simply painting over the blur with generic face-like textures.
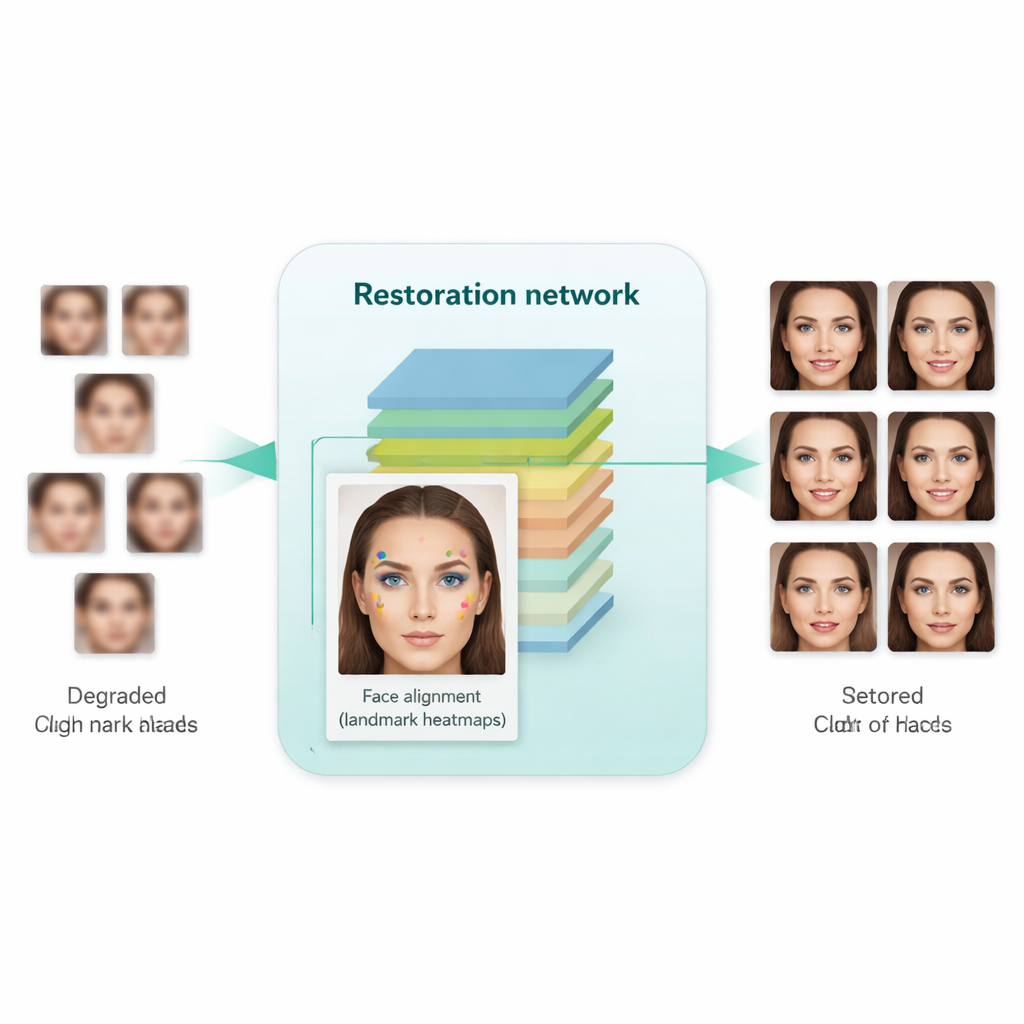
How Well Does It Work in Practice?
The researchers trained their system on a large collection of high-quality faces and a separate set of genuinely low-quality faces from real-world datasets. They then tested it on both synthetic benchmarks (where clean ground-truth images are available) and real-world images (where only visual realism and statistical measures can be used). Compared with earlier methods—including well-known tools like Real-ESRGAN, GFPGAN, and the original SCGAN—the new approach produced images that not only looked more natural and less distorted, but also led to better performance on practical tasks. When enhanced images were fed into standard face detectors and a popular face recognition model (FaceNet), detection and verification accuracy improved noticeably, indicating that identity-related details were better preserved. At the same time, automated quality metrics suggested that the generated faces were closer in distribution to real high-resolution photos.
What This Means for Everyday Use
In simple terms, this work shows that you can get sharper, more trustworthy faces from poor-quality images by combining two ideas: learn a realistic model of how images are ruined in the real world, and use facial landmark information to keep the structure of the face intact. Instead of merely “guessing” a nicer-looking face, the system is guided to reconstruct the right person with clearer eyes, mouth, and overall shape. That makes the method especially promising for applications like security, forensics, and archival restoration, where both visual clarity and correct identity are critical, and where original high-quality versions of the images are rarely available.
Citation: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Keywords: face super-resolution, generative adversarial networks, face alignment, facial recognition, image restoration