Clear Sky Science · en
Research on plug-and-play correlation enhancement modules in deep multi-label learning
Teaching machines to handle too many tags
Online stores, legal archives, and medical databases all depend on software that can quickly tag each new document with the right labels. But modern systems often face tens of thousands, or even millions, of possible tags—from product categories to medical subjects—while each text only needs a handful. This paper introduces a new add-on, called the Label Correlation Enhancement Network (LCENet), that helps existing deep-learning models make better use of how labels naturally appear together in real data, leading to more accurate and faster text tagging.
Why labeling at web scale is so hard
Many real-world applications fall into what researchers call extreme multi-label text classification: given a short description or long document, the system must pick a small subset of relevant labels from an enormous catalog. Examples include assigning categories to products on an e-commerce site, indexing biomedical articles with MeSH terms, matching ads to web pages, or mapping legal texts to detailed legal codes. These settings share three challenges: the label list is extremely large, most labels are rare, and any given text uses only a few labels. Traditional techniques either split the problem into many small classifiers or compress labels into lower-dimensional vectors, but they often rely on simple word counts and cannot fully capture meaning or relationships between labels.
What standard deep models still miss
Modern deep-learning approaches, such as convolutional networks, recurrent networks, and Transformer-based models like BERT, have greatly improved text understanding by learning rich semantic representations. Yet almost all of them make a crucial simplification at the final step: once the text is encoded into a vector, they predict each label independently. In practice, however, labels interact strongly. A medical paper labeled with “diabetes” is more likely to also involve “insulin resistance,” and a gadget labeled “smartphone” is usually related to “electronics” and “communication devices.” Ignoring these patterns means models cannot use high-confidence labels to support weaker ones, and they may even output combinations that do not make sense together.
A plug-in that learns label relationships
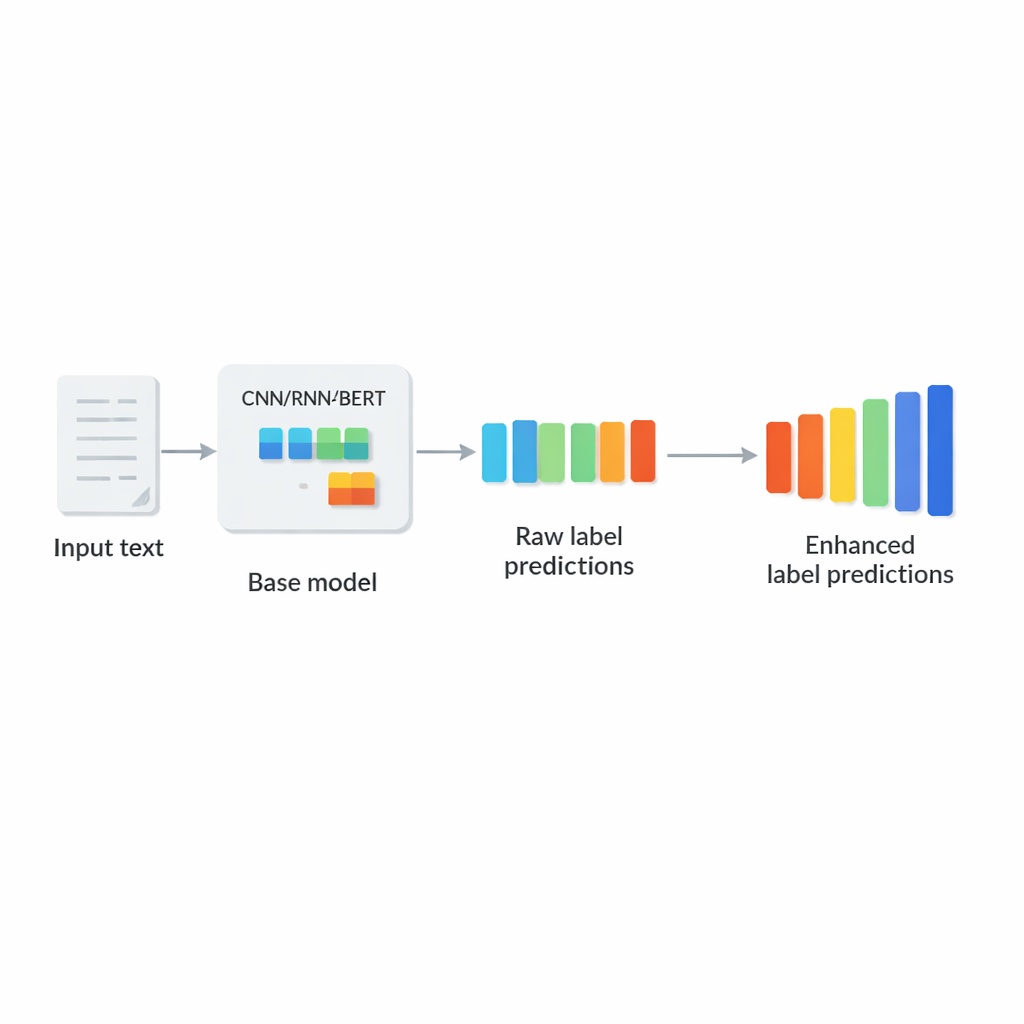
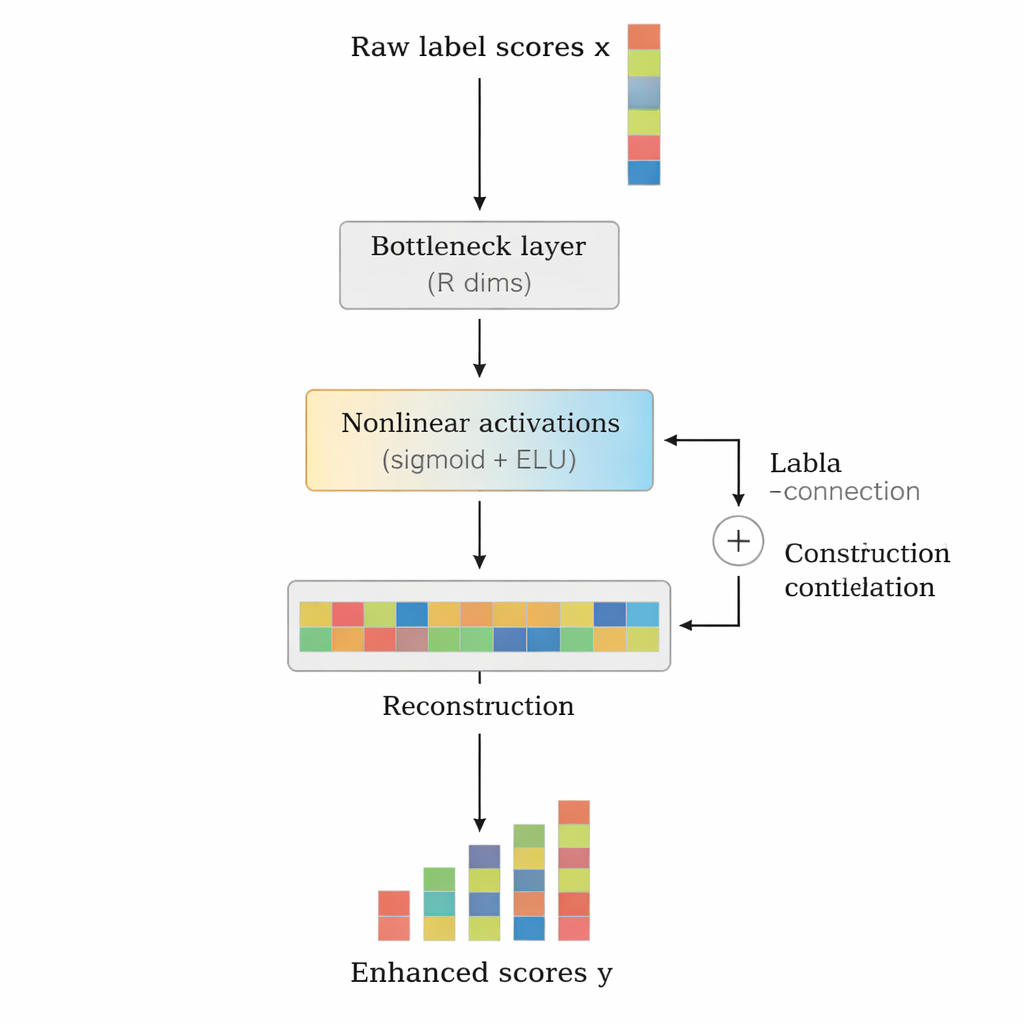
The authors propose LCENet as a lightweight, plug-and-play module that sits after any existing deep text classifier. Instead of changing how the base model reads text, LCENet takes the raw label scores it produces and passes them through a compact “bottleneck” that forces the system to discover a low-dimensional representation where related labels cluster together. Nonlinear activation functions then allow the module to capture complex, higher-order associations, not just simple pairwise links. A residual, or skip, connection feeds the original scores directly to the output alongside the corrected scores, which stabilizes training and ensures that the add-on cannot easily make things worse. Crucially, LCENet reduces the number of extra parameters from something that would grow with the square of the label count to a far more manageable linear growth, so it remains feasible even for hundreds of thousands of labels.
Proving the benefits across models and datasets
To test whether LCENet is truly general, the authors attached it to four very different deep models, including CNN‑based and BERT‑based architectures, as well as systems designed specifically for biomedical and extreme-label settings. They evaluated these combinations on three public benchmark datasets: a European legal corpus (EUR-Lex), an Amazon product dataset (AmazonCat-13K), and a massive Wikipedia collection with over half a million labels (Wiki-500K). Across all models, datasets, and six ranking-focused metrics, LCENet consistently improved performance, sometimes raising top-1 precision by more than five percentage points on the largest dataset. Training curves further showed that LCENet often cuts the number of training steps needed to reach a given accuracy nearly in half, because the added label-correlation structure provides clearer learning signals from the start.
Why this matters for everyday systems
For practitioners who already rely on deep models to tag text, LCENet offers a practical way to upgrade accuracy and training speed without redesigning their systems or collecting new kinds of annotations. It treats the label space itself as a source of knowledge, learning which tags tend to move together or exclude one another, and then nudging predictions accordingly. While developed for text, the same idea of enhancing predictions using learned relationships between outputs could be applied to images, multimodal data, and other structured prediction tasks. In simple terms, LCENet helps machines “remember” how labels relate, so they guess less like isolated checkboxes and more like a knowledgeable human who understands how concepts fit together.
Citation: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Keywords: extreme multi-label text classification, label correlation, deep learning, text classification, neural networks