Clear Sky Science · en
DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks
Teaching Computers to Pay Better Attention
Modern image-recognition systems can spot cats, traffic signs, and tumors in scans—but they don’t always know what to focus on inside a picture. This paper presents a new way to help these systems concentrate on the most important parts of an image, improving accuracy and making them more reliable in the messy conditions of real life. The method, called Dynamic Multi-Scale Channel-Spatial Attention (DMSCA), plugs into existing convolutional neural networks and helps them see both the “what” and the “where” in an image more intelligently.
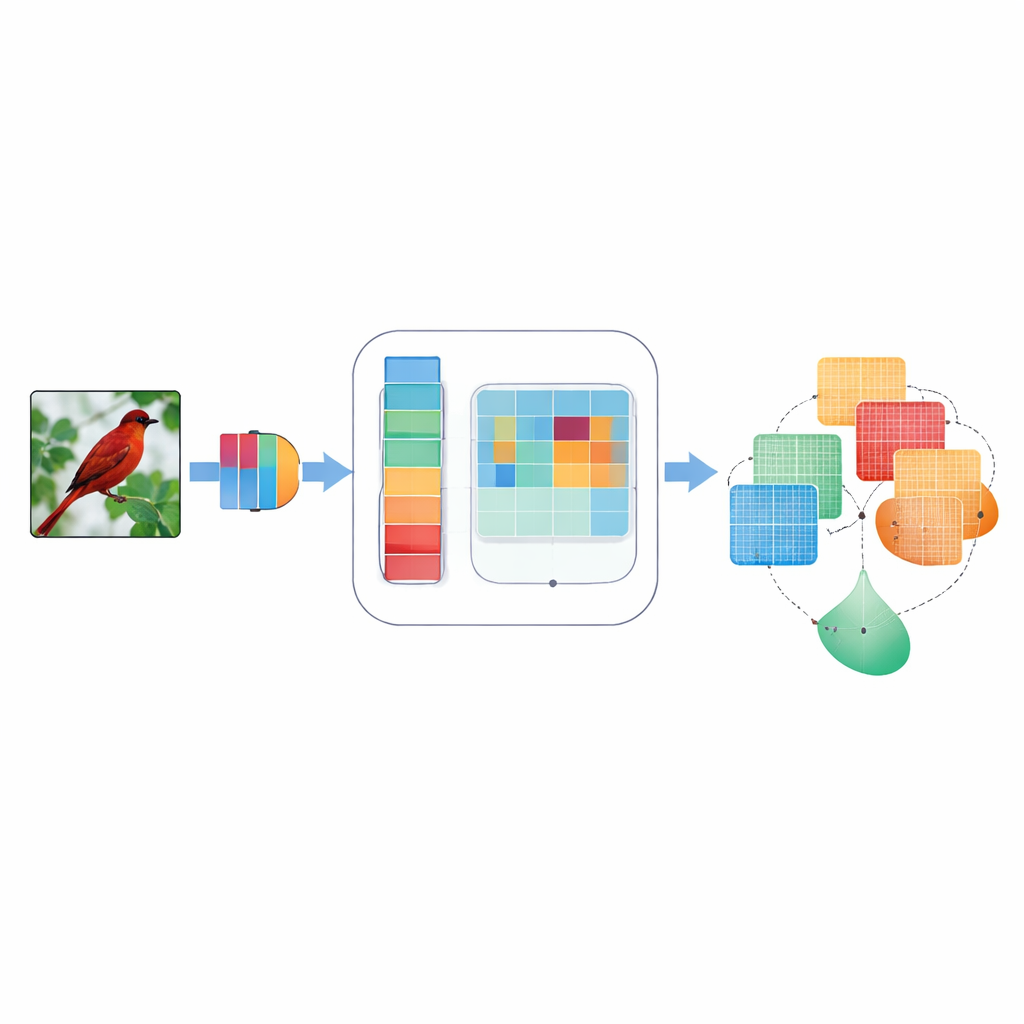
Why Focus Matters for Machine Vision
Convolutional neural networks, the workhorses behind many vision applications, normally treat every internal signal as equally important. That means a faint edge of a bird’s wing and a patch of sky may get similar attention, even though only one helps identify the species. Earlier “attention” methods tried to fix this by weighing some internal signals more than others—either across color-like channels or across the two-dimensional layout of an image. But those methods often used fixed, hand-designed rules, looked at only one scale of detail at a time, or combined information in a rigid way that could not adapt to different images. As a result, they sometimes missed fine details, ignored directions like “horizontal vs. vertical,” or struggled when images were noisy or blurred.
A Smarter Attention Add-On
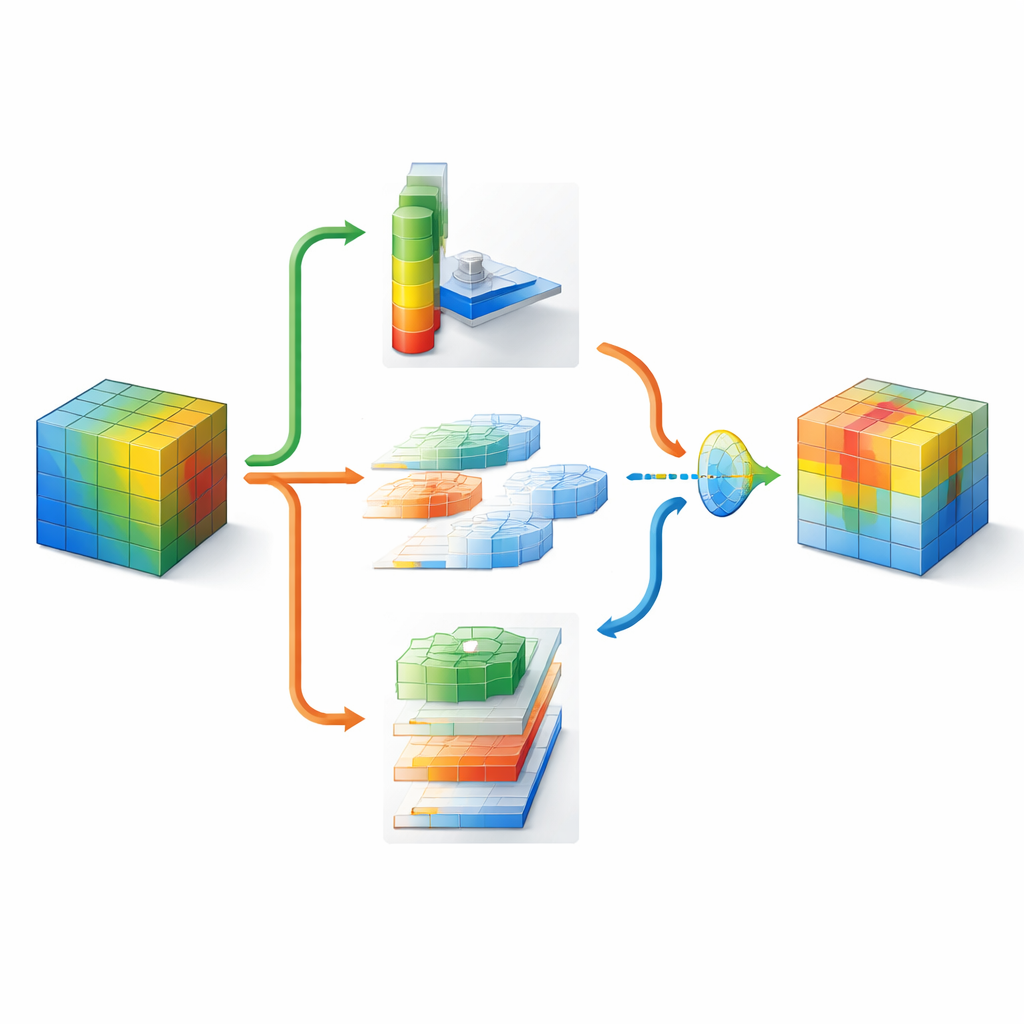
DMSCA is designed as a small, attachable module that can be inserted into well-known neural networks such as ResNet without changing their overall structure. Inside, it coordinates six tightly linked parts that work together rather than in isolation. One part summarizes the entire image to capture what is happening globally, while another learns how strongly each internal channel should matter, using a controllable “temperature” that can make decisions sharper or softer as needed. On the spatial side, DMSCA uses several window sizes at once to capture both tiny textures and larger shapes, and it explicitly pays attention to horizontal and vertical directions so that long edges or stripes are not washed out. Finally, instead of simply adding these signals together, the module learns, pixel by pixel, how much to trust “what” information from channels versus “where” information from space.
Looking at Images at Many Scales and Directions
To understand where to look in an image, DMSCA first compresses the many internal channels into a compact two-layer map that highlights both background trends and standout features. It then passes this map through several parallel filters of different sizes. Small filters see fine-grained details like fur or feathers, while larger ones capture shapes such as whole heads or bodies. In parallel, a directional unit scans along rows and columns separately, preserving the exact position of important structures. These horizontal and vertical views are then allowed to interact, so that a strong vertical signal, for example, can reinforce the right horizontal locations. The result is a rich attention map that tells the network not just that something is important, but where it is and at what scale.
Letting the Network Decide What Matters Most
Because different parts of an image can call for different strategies, DMSCA does not impose a fixed recipe for combining channel and spatial information. Instead, it builds a tiny “gate” that examines both and decides—independently for each pixel—how much weight to give to each type. In a cluttered background, the system may rely more on which channels stand out, while around crisp object edges it may emphasize spatial cues. A final adaptive activation stage then acts like a learned dimmer switch, boosting truly informative regions and dimming down residual noise. This multi-stage process helps steer the network’s attention toward coherent, object-related regions, as confirmed by visual heatmaps and quantitative measures of how well the highlighted areas match ground-truth objects.
Sharper Vision with Modest Extra Effort
The authors tested DMSCA on several standard benchmarks, from small collections of tiny images to the large-scale ImageNet dataset. When added to popular ResNet models, DMSCA consistently improved classification accuracy—by up to about 2 percentage points on small sets and 1.5 percentage points on ImageNet—outperforming a range of existing attention methods. It also made models more robust to common image degradations like noise, blur, and heavy compression, and improved performance on related tasks such as object detection and scene labeling. These gains came with only a modest increase in computation and memory. In simple terms, DMSCA gives convolutional networks a more flexible and context-aware way to decide what to look at and what to ignore, bringing machine vision a step closer to the selective focus of human sight.
Citation: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Keywords: attention mechanisms, image recognition, convolutional neural networks, feature representation, robust computer vision