Clear Sky Science · en
Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions
Searching Smarter Across Images and Words
Every day we scroll through oceans of photos, videos, and text. Finding exactly what we want—say, all pictures that match a short caption—depends on how well computers can connect images with language. This paper explores a new way to make that connection more accurate, especially in messy, real-world scenes where many ideas and objects appear at once. The result is smarter search tools that better “understand” what we mean, not just what we type.
Why Many Meanings in One Picture Matter
A single image rarely shows just one thing. A photo of a whale breaching at sea might involve the ocean, sky, waves, wind, and wildlife all at once. When we tag such a picture, we often attach several labels that are related in subtle ways. Existing search systems usually treat these labels as if they were unrelated checkboxes. That simplification throws away useful clues: if “whale” often appears with “sea,” then seeing one should raise the odds of the other. This work focuses on capturing those hidden ties among labels so that a search for one idea can still find images and texts that express closely related ones.

Building a Web of Connected Labels
The authors introduce a technique called a Two-Layer Graph Convolutional Network, or L2-GCN, to model how labels relate to each other. In simple terms, each label (like “sky” or “whale”) is treated as a point in a network, and lines between points reflect how often those labels appear together. The method repeatedly lets each label “listen” to its neighbors, blending information from related labels while still keeping its own identity. After this process, the system ends up with richer label descriptions that better capture how real scenes are structured, from parallel ideas (“sea” and “beach”) to more layered ones (“animal” and “whale”).
Teaching Images and Text to Share a Common Space
Of course, labels are only half the story; the system also needs to learn from the images and texts themselves. The framework uses established tools to turn raw pixels and words into numerical features, then pushes both types of data into a shared space where their meanings can be directly compared. An adversarial module—loosely inspired by the push-and-pull of generative adversarial networks—discourages the model from clinging to quirks of either images or text alone. This helps the shared space focus on content rather than format, so that a picture of a bustling street and a short caption describing it end up close together in this common map of meaning.
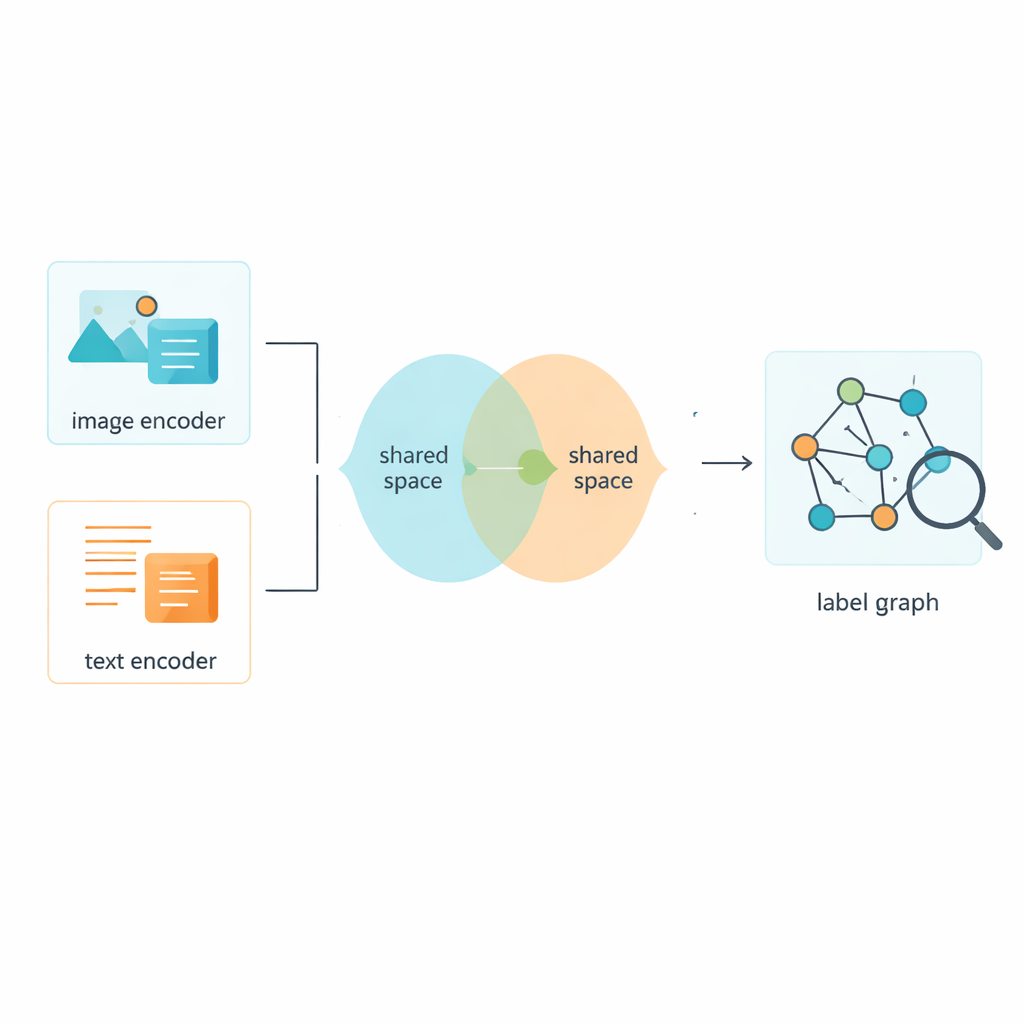
A Hybrid Training Strategy for Sharper Distinctions
Training such a system requires more than one learning rule. The authors design a combined loss function, dubbed Circle-Soft, that blends two complementary ideas. One part encourages examples from the same category to cluster tightly together while pushing different categories apart in a flexible, adaptive way. The other part focuses on how well images and texts that describe the same scene align across formats. A tunable weight balances these two goals so the model does not overfit to either neat category boundaries or cross-modal alignment alone. Additional classification and adversarial losses further encourage consistency between the refined labels and the shared image–text features.
How Much Better Does This Make Search?
To see whether these ideas translate into better search, the authors tested their method on three popular collections of real-world image–text pairs: MIRFlickr, NUS-WIDE, and MS-COCO. These datasets contain thousands to hundreds of thousands of photos with associated tags or captions, covering everyday scenes from city streets to wildlife. Across all three benchmarks, the new approach consistently edged out a wide range of competing methods, including other advanced systems that already use graph-based label modeling. The gains—around half a percentage point to a full percentage point in a strict retrieval score—may sound modest, but in mature benchmarks even small improvements signal a more precise understanding of content. In practical terms, this means that when a user enters a short text query or submits an image, the system is more likely to surface the most relevant cross-modal matches near the top of the results.
What This Means for Everyday Users
For non-specialists, the key message is that smarter handling of labels and training rules can noticeably improve how machines connect pictures and words. By treating labels as an interconnected web rather than isolated tags, and by carefully shaping how visual and textual information meet in a shared space, this framework makes cross-modal search more reliable in complex, multi-topic scenes. Over time, techniques like this could power more intuitive photo libraries, media platforms, and intelligent assistants that find what we mean—even when our words do not perfectly match the images we have in mind.
Citation: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Keywords: image-text retrieval, multimodal search, graph neural networks, semantic labels, machine learning