Clear Sky Science · en
Medical knowledge representation enhancement in large language models through clinical tokens optimization
Why smarter medical reading matters
Behind every medical AI assistant lies a simple but critical skill: how it cuts text into pieces it can understand. When this “chopping” goes wrong—especially for complex Chinese medical terms—the AI may miss key ideas in doctors’ notes or patient questions. This paper shows how a small but targeted change to that first step can make large language models better at reading, reasoning about, and answering questions on Chinese medical data, without building an entirely new system from scratch.
Breaking text into pieces the right way
Modern language models do not read characters or words directly; they first convert text into short units called tokens. For English, this works fairly well, because spaces already mark word boundaries. Chinese is trickier: there are no spaces, and many medical expressions are long, specialized phrases. Standard tokenizers, designed mainly for English, tend to slice these phrases into many arbitrary fragments. When a model sees a disease name or a lab test split into several disjoint pieces, it has a harder time learning what that term really means, and its answers to medical questions can become vague or inaccurate.
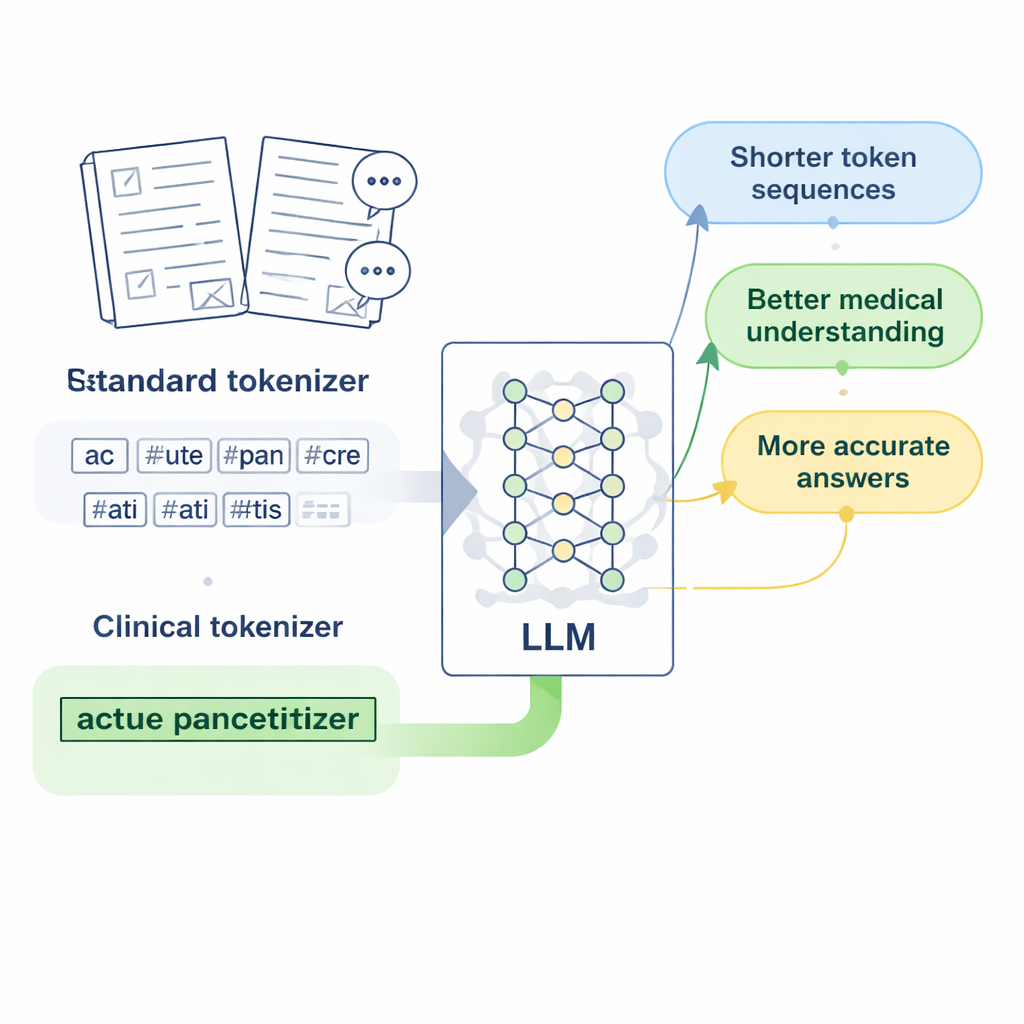
Designing “clinical tokens” for Chinese medicine
The researchers focus on LLaMA2, a popular open-source large language model, and ask: what if we simply teach its tokenizer a richer medical vocabulary? They gather large collections of Chinese medical text, including carefully edited traditional Chinese medicine databases, thousands of clinical records, and doctor–patient question-and-answer pairs. Using a byte-level version of the Byte Pair Encoding algorithm, implemented with the SentencePiece tool, they train a new tokenizer that learns to keep common medical expressions together as single units. These new units, which the authors call “clinical tokens,” are then merged into LLaMA2’s original vocabulary, expanding it to better cover Chinese medical language without discarding what the model already knows.
From better tokens to a better medical model
Adding new tokens is only the first step; the model must learn good representations for them. The team adjusts LLaMA2’s internal embedding layer so it can store vectors for the expanded vocabulary and tests two ways to initialize these new vectors. One method averages the vectors of older sub-pieces of each word, while the other uses carefully scaled random values. Counterintuitively, the random method performs better, likely because it avoids locking the model into a poor initial guess about each term’s meaning. The authors then continue training the model on medical text, and fine-tune it on instruction-style medical Q&A using a resource-efficient method called LoRA, producing a specialized version they call Medical-LLaMA.
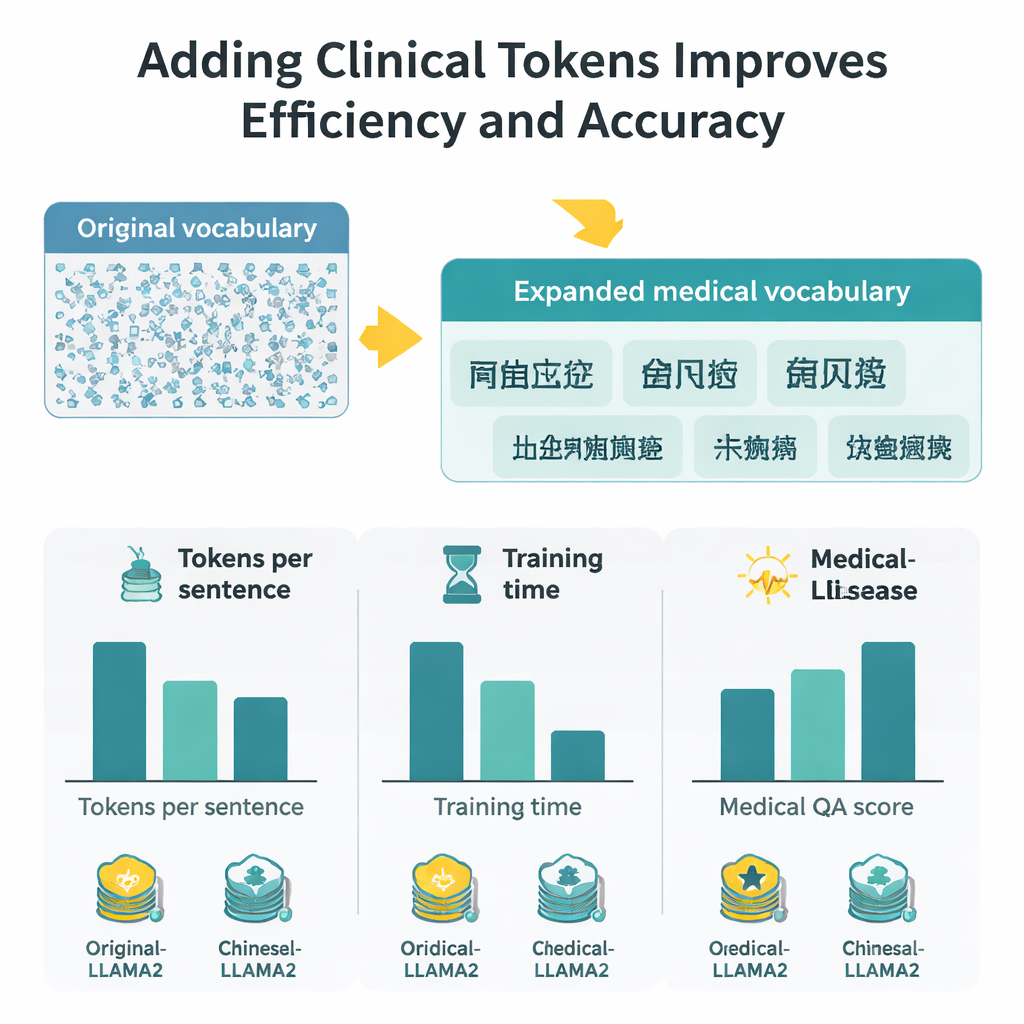
Measuring gains in speed, context, and accuracy
With the expanded vocabulary, each Chinese character now requires about half as many tokens as before, which means the model can process longer passages in the same fixed token window. In practice, the effective Chinese context length roughly doubles, and fine-tuning time on a large medical Q&A set is cut by nearly half. To judge answer quality, the authors combine two evaluation strategies: BERTScore, which measures how semantically close a generated answer is to a reference, and a sophisticated rating model (DeepSeek-R1) that scores relevance, accuracy, completeness, and fluency. Across these measures, Medical-LLaMA consistently beats both the original LLaMA2 and a Chinese-optimized variant that did not include medical-specific tokens. It also shows small but steady improvements on related tasks such as recognizing medical entities and classifying clinical text, all while preserving performance on general, non-medical questions.
What this means for future medical AI
For non-specialists, the key message is that smarter “reading glasses” for AI—here, a better way of slicing up medical language—can noticeably improve how well it understands and answers health questions. By inserting well-chosen clinical tokens into an existing model’s vocabulary, the authors boost both efficiency and accuracy without requiring massive new training runs or wholly new architectures. While the work is limited to a 7-billion-parameter model and Chinese medical text, it points to a practical recipe: tailor the earliest layer of language processing to the domain, then lightly retrain. This strategy may help future medical AI tools become more reliable partners for clinicians and patients, especially in languages and specialties that standard models struggle to read.
Citation: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Keywords: medical language models, Chinese clinical text, tokenization, clinical vocabulary, medical question answering