Clear Sky Science · en
AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning
Why smart helmet checks matter
On large construction projects and in underground tunnels, a simple safety helmet can mean the difference between a close call and a life‑changing injury. Yet in the chaos of real work sites, people forget or avoid wearing helmets, and human supervisors cannot watch every corner at all times. This study explores how to build an automated camera system that reliably spots who is and is not wearing a helmet, even when the tunnel is dim, flooded with glare from lamps, or packed with workers at many distances from the camera.
Challenges of seeing in harsh tunnel lighting
Tunnel construction sites are visually extreme places. Bright spotlights create glare, while deep pockets of shadow hide details. People move toward and away from the camera, so their helmets appear at many different sizes. Standard artificial‑intelligence detectors often fail in these conditions: they miss helmets in dark areas, confuse other rounded objects for helmets, or struggle with very small or distant workers. Many existing systems try to fix this by brightening or cleaning the images before detection, or by tweaking a few components of popular YOLO object‑detection models. But because these steps are usually bolt‑on fixes rather than part of a single learning process, they leave performance on the table and are not robust when lighting or scene layout changes.
A new way to teach cameras to ignore bad lighting
The authors propose an improved system called AE‑LFOG‑YOLO, built on the widely used YOLOv8 detector. The first key idea is an Illumination‑Invariant Module, a small unit added inside the network that learns to separate “what the light is doing” from “what the objects really look like.” It splits incoming feature maps into a part that mainly reflects lighting patterns and a part that captures more stable shape and texture, such as the curved edge of a helmet. By using special gating operations and a branch that focuses on edges and corners, the module downplays brightness swings and emphasizes stable geometry. Because this happens inside the detector rather than in a separate pre‑processing step, the whole system can be trained end‑to‑end to stay focused on the helmets themselves instead of being fooled by patches of glare or darkness.
Letting the model evolve its own viewing habits
The second main idea targets how the detector guesses where objects might appear. Many detectors start from a fixed set of “anchor boxes” that suggest likely object sizes and shapes; these are usually chosen once from the training data and never updated. In tunnels, however, the apparent size of a helmet can change dramatically with camera distance and viewing angle. AE‑LFOG‑YOLO replaces static anchors with a dynamic process called Adaptive Evolutionary – Light Field Optimized Generation. At the end of each training round, the system gently perturbs its anchor boxes, scores how well they match real helmets of all sizes, and also checks whether their dimensions make sense given basic camera optics—how big a real helmet should look on the sensor at typical working distances. Better‑scoring anchor sets survive to the next round. Over time, the detector “evolves” anchors that both fit the data and respect how cameras actually image the world.
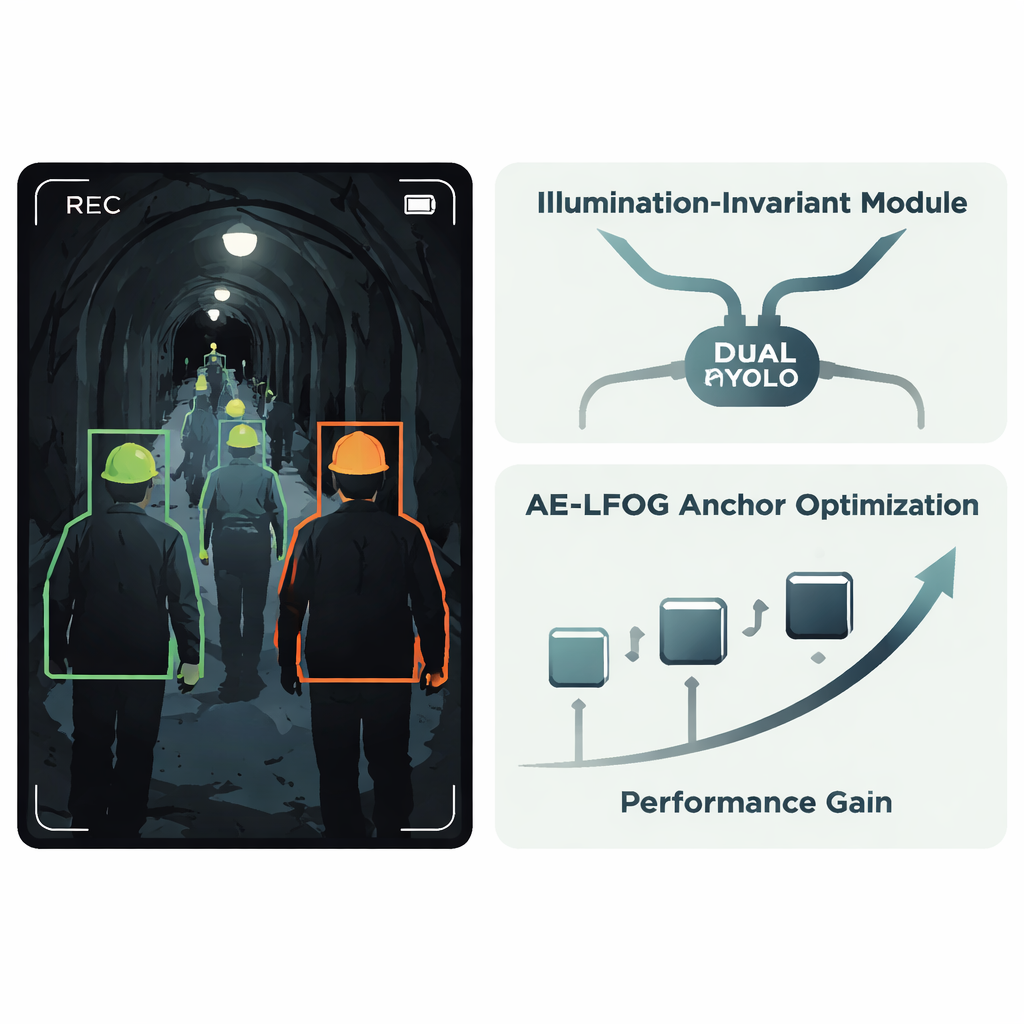
Adapting training to real‑world image quality
Beyond changing what the model looks for, the authors also change how it learns. They introduce a training strategy that pays more attention to precisely locating helmets when image quality is poor, and more attention to correctly labeling helmet versus no‑helmet when conditions are good. A physics‑based score, again derived from camera imaging principles, tells the system how trustworthy the images are at each stage. If lighting or focus is bad, the training process automatically increases the importance of getting the bounding boxes right; if conditions improve, it shifts weight toward classification. This creates a feedback loop in which the model continually adjusts its own priorities to match the physical environment it will face in real tunnels.
What the tests show in practice
The researchers test their approach on a real tunnel safety‑helmet dataset and compare it with several advanced YOLO‑based methods. AE‑LFOG‑YOLO detects helmets with very high accuracy, correctly identifying about 95 percent of helmets at a standard overlap threshold and outperforming the plain YOLOv8 baseline in both precision and recall. It runs fast enough for real‑time use and proves especially strong when lighting is heavily manipulated to simulate extreme darkness or overexposure. Under these tough conditions, the new model keeps its confidence higher, detects more small and distant workers, and operates over a brightness range that is more than one‑third wider than that of the baseline, meaning it stays reliable in a much larger set of real‑world scenes.
How this helps keep workers safer
For non‑specialists, the takeaway is straightforward: by teaching an AI system to understand not just pixels but also the physics of how cameras see in difficult environments, this work delivers a smarter, more dependable watcher on the tunnel wall. AE‑LFOG‑YOLO can better ignore misleading lighting and adapt to changing views, reducing missed detections and false alarms. Deployed for months on an operating rail‑transit line, it has already shown it can support safety teams in making sure workers keep their helmets on, offering a practical step toward safer, more closely monitored construction sites.
Citation: Liu, S., Wang, J. AE-LFOG-YOLO: robust safety helmet detection via adaptive anchors and illumination invariant learning. Sci Rep 16, 6402 (2026). https://doi.org/10.1038/s41598-026-37326-z
Keywords: safety helmet detection, tunnel construction, computer vision, low-light imaging, YOLOv8