Clear Sky Science · en
Application of hierarchical self-supervised contrastive learning in domain adaptation matching of multimodal remote sensing image
Seeing Earth Through Different Eyes
Weather satellites, radar missions, and high‑resolution cameras in space all look at the same planet in very different ways. This diversity is a strength for tasks such as tracking floods, mapping cities, or monitoring forests—if we can reliably line up the images. The paper summarized here introduces a new artificial‑intelligence method that teaches computers to match these very different views of Earth more accurately and with far less human labeling, opening the door to faster and more robust environmental monitoring.
Why Matching Different Images Is So Hard
Remote sensing images come from many kinds of sensors: optical cameras that see like our eyes, radar systems that measure surface roughness, and multispectral instruments that capture subtle color differences. Because each sensor has its own way of “seeing,” the same building, ship, or field can look completely different from one image to another—grainy in radar, sharp in optical, or tinted in unusual colors in multispectral views. Traditional matching methods either depend on hand‑crafted visual features or on fully supervised deep learning that needs huge amounts of carefully labeled data. Both approaches tend to fail when the appearance gap between sensors is large, or when labeled examples are scarce, as is often the case during disasters or in remote regions.
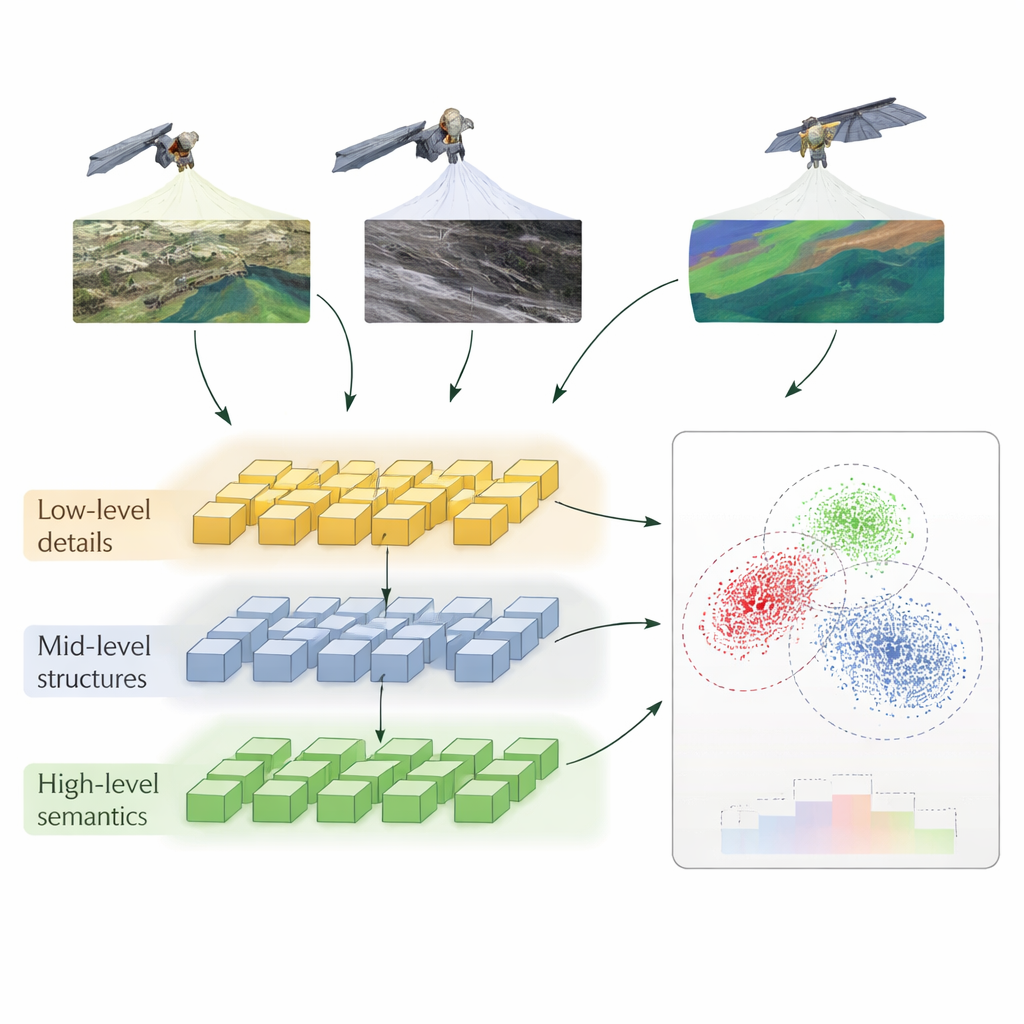
A Layered Way of Teaching Computers to Compare
The authors propose a method called Hierarchical Self‑Supervised Contrastive Learning (HSSCL), which changes how a neural network learns to compare images. Instead of looking only at a single summary of each image, the network extracts information at three levels: fine details such as edges and textures, mid‑scale patterns such as roads and building outlines, and broad patterns such as city layouts or land‑cover types. At each level, the system encourages features from different sensors that depict the same area to become more similar, while pushing apart features that come from unrelated areas. This “contrastive” training happens without human labels: the model uses the known pairing of images from different sensors over the same location, plus automatically found similar examples, to build up a rich sense of what “the same place” looks like across modalities.
Cleaning Up Noise and Preserving Geometry
Real‑world remote sensing data are messy—radar images contain speckle noise, optical images can be hazy, and all of them may be misaligned by a few pixels. HSSCL tackles this by first dividing images into small blocks and applying tailored denoising, which helps the network focus on meaningful structure rather than random fluctuations. It then feeds features from different blocks into a graph‑based module that treats each region as a node and links regions that are close together and look similar. By operating on this graph, a specialized graph neural network strengthens the geometric consistency of matches, making it more likely that roads line up with roads and buildings with buildings, even under difficult conditions.
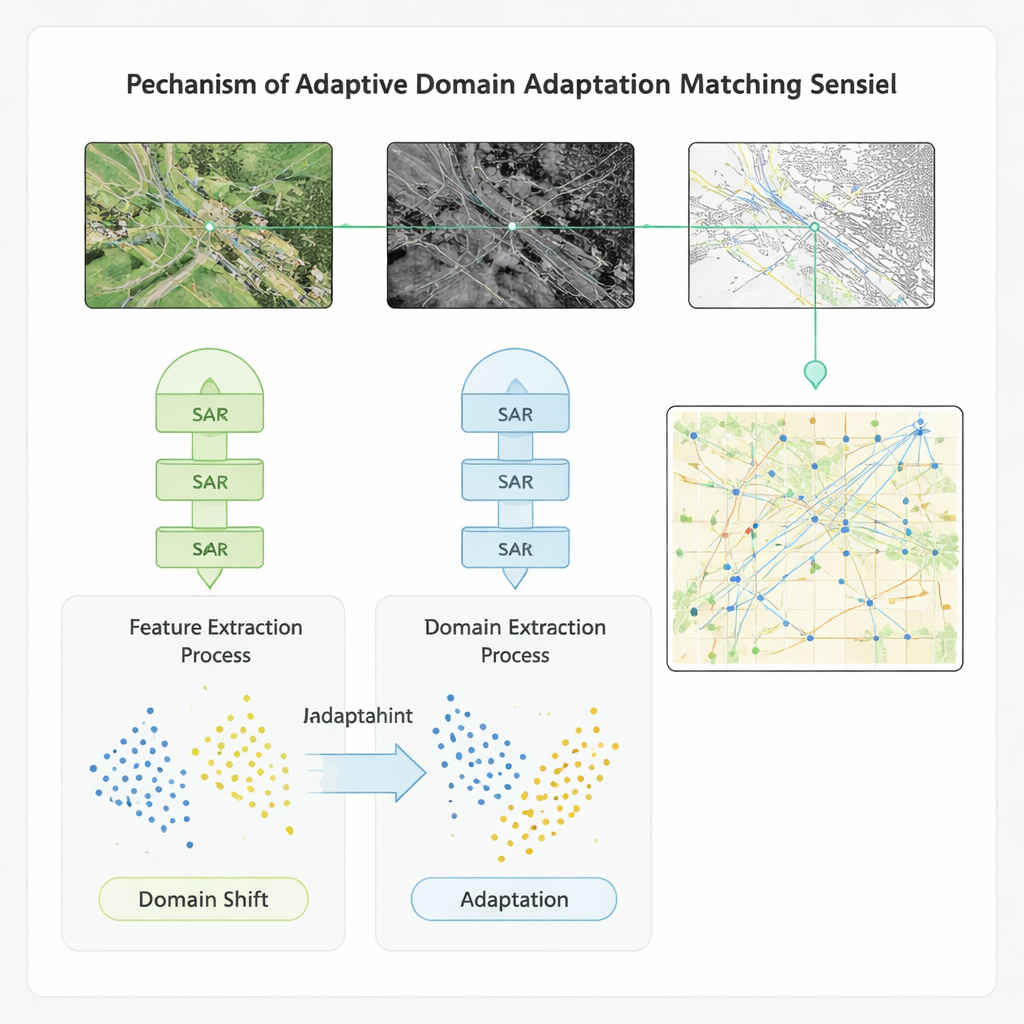
Adapting Across Datasets and Conditions
To ensure that the method works beyond a single benchmark, the authors embed their learning scheme in a domain‑adaptation model. This component explicitly narrows the gap between the statistical properties of features from different sensors and datasets, so that a model trained on one region or instrument can be applied to another with minimal loss of accuracy. Tested on four public datasets that include global multispectral imagery, high‑resolution radar‑optical pairs, land‑cover scenes, and ship imagery, the new approach outperforms several advanced baselines. It improves accuracy, recall, and F1‑score by roughly 20 percentage points, speeds up matching by more than 20%, and boosts video‑style defect detection accuracy—important for monitoring changes over time—by over 40%. The method also shows stronger resilience to noise and to shifts between training and deployment conditions.
What This Means for Real‑World Monitoring
From a layperson’s perspective, the study shows how computers can be trained to recognize “this is the same place” across images that look nothing alike to human eyes. By learning at several detail levels, cleaning away noise, and explicitly adapting to new sensors and regions, the HSSCL method makes it easier to combine many streams of satellite data into a coherent picture. This, in turn, can help emergency responders more quickly align radar and optical images after a storm, aid planners in tracking how cities or forests change over years, and support continuous ship tracking at sea. While the authors note that extreme noise and very large distortions still pose challenges, their work offers a promising and practical path toward faster, more reliable matching of the many eyes we have in orbit.
Citation: Li, Y., Luo, Z., Zhu, G. et al. Application of hierarchical self-supervised contrastive learning in domain adaptation matching of multimodal remote sensing image. Sci Rep 16, 6445 (2026). https://doi.org/10.1038/s41598-026-37312-5
Keywords: remote sensing, multimodal imagery, self-supervised learning, contrastive learning, domain adaptation