Clear Sky Science · en
LightECA-UNet: a lightweight model for segmentation of coal fracture CT images
Why Cracks Inside Coal Matter
Deep underground, coal is crisscrossed with tiny cracks that control how the rock breaks and how gas and water move through it. Understanding these hidden fracture networks is vital for preventing mine disasters, improving gas drainage, and even planning carbon storage. Modern CT scanners can take detailed X‑ray slices of coal, but turning these gray‑scale images into clear maps of fractures is hard, especially right at the mine where computing power is limited. This study introduces a new, lean artificial intelligence model, LightECA‑UNet, designed to read coal CT scans accurately while being small and fast enough to run on modest on‑site hardware.
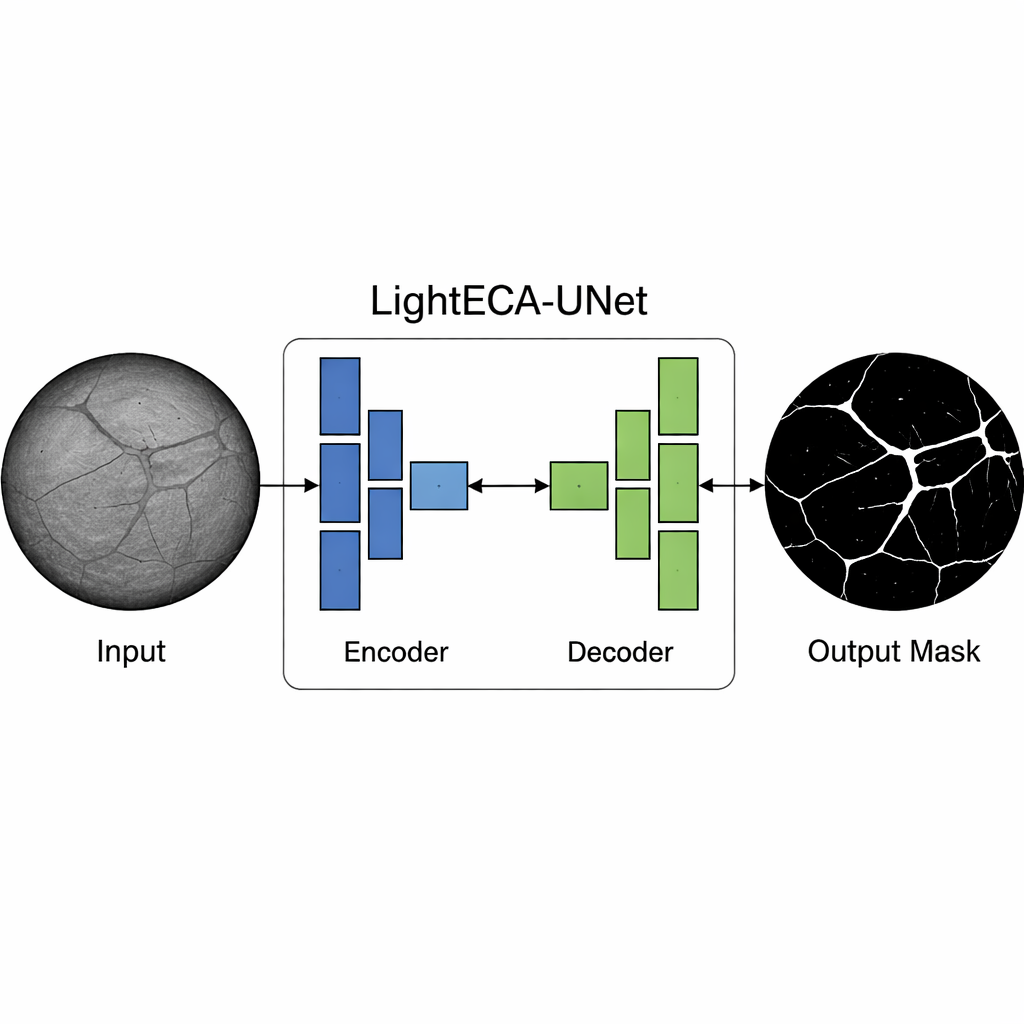
The Challenge of Seeing Cracks in Gray Rock
Coal fractures are tricky to pick out in CT images. Their gray values are often almost the same as the surrounding coal, edges are blurred, and the finest cracks may be only a few pixels wide. Traditional image‑processing methods struggle with this, and even popular deep‑learning models tend to be large, power‑hungry, and trained on everyday photographs rather than geological data. A widely used architecture called UNet can segment images well, but in its basic form it demands heavy computation, wastes parameters on redundant features, and can overfit small, specialized datasets such as coal CT scans. These drawbacks make it hard to deploy directly on the compact, intrinsically safe devices allowed in underground mines.
A Leaner Network Built for Coal CT Scans
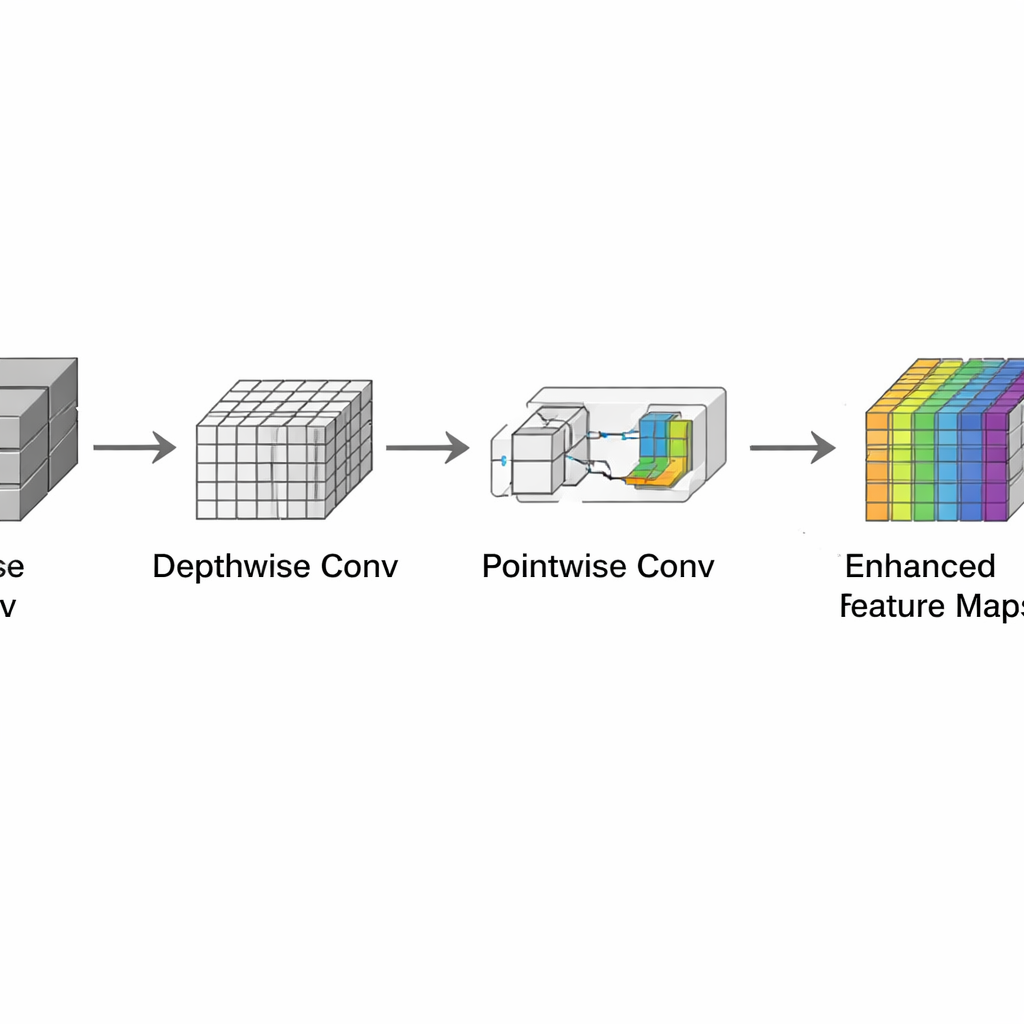
The authors re‑engineer UNet into a coal‑specific, resource‑efficient model. First, they replace the usual convolution layers with “depthwise separable” convolutions. Instead of mixing information from all image channels at once, the model first processes each channel separately in space and then combines them with simple 1×1 operations. This change cuts the arithmetic cost of early layers to about one‑ninth of the original design, allowing high‑resolution CT images to be processed without overwhelming limited hardware. Second, they trim the number of channels in each stage of the network. Rather than doubling channels up to very large values, LightECA‑UNet caps them at modest levels that are sufficient for coal’s relatively narrow range of textures. This targeted pruning slashes the parameter count from about 31 million to just 0.55 million.
Teaching the Model to Focus on Faint Fractures
Shrinking a network usually risks losing accuracy, so the authors add a lightweight “attention” mechanism called Efficient Channel Attention (ECA). In simple terms, ECA lets the model weigh which internal feature channels are most informative. It summarizes each channel, looks at how neighboring channels relate to one another, and learns which ones tend to carry crack‑like signatures—such as fine edges or subtle gray‑level shifts. These channels are then emphasized, while those dominated by background noise are toned down. Crucially, ECA does this without heavy extra layers, so it preserves the model’s compactness while sharpening its sensitivity to faint, low‑contrast fractures that standard methods often miss. Combined with the depthwise separable convolutions, this forms a “symbiotic block” that is both efficient and crack‑aware.
Putting the New Model to the Test
To evaluate LightECA‑UNet, the team built a specialized dataset of 600 high‑resolution CT slices from cylindrical coal samples. They created precise fracture labels using a mix of automated thresholding and meticulous manual correction, then trained and compared multiple model variants under identical conditions. Ablation experiments showed that each ingredient—lighter convolutions, channel pruning, and ECA attention—contributes, but the full combination gives the best balance of speed and accuracy. Across five rounds of cross‑validation, LightECA‑UNet consistently achieved around 97% overlap between predicted and true crack regions while keeping computation very low. When benchmarked against six leading segmentation networks, including both heavy and “lightweight” designs, the new model had the smallest size and fastest inference time, yet delivered the highest crack‑detection scores and the cleanest visual segmentations.
What This Means for Safer, Smarter Mining
In everyday terms, LightECA‑UNet acts like a highly trained eye that can reliably trace hairline fractures in murky X‑ray images without needing a supercomputer. Because it is so compact and quick, it can be integrated into portable CT systems or edge devices deployed near the working face of a mine. That opens the door to real‑time assessments of coal stability, better estimates of how easily gas and fluids can move through a seam, and more informed decisions about drilling, support, and hazard mitigation. While this study focuses on one coal type, the design principles—tailoring a network to the specific textures, contrasts, and hardware limits of a domain—could be extended to other rock types and to related tasks like tunnel crack mapping or pore analysis in shale, bringing more precise, low‑cost imaging tools to the broader geoscience community.
Citation: Xing, X., Li, Y., Zhang, Y. et al. LightECA-UNet: a lightweight model for segmentation of coal fracture CT images. Sci Rep 16, 6040 (2026). https://doi.org/10.1038/s41598-026-37291-7
Keywords: coal CT imaging, fracture segmentation, lightweight deep learning, UNet architecture, mine safety