Clear Sky Science · en
A hybrid framework of feature selection and interpretability for dissolved oxygen prediction in drinking water treatment plants
Why oxygen in drinking water matters
Dissolved oxygen—the tiny bubbles of oxygen gas mixed into water—quietly shapes whether our drinking water stays clear, safe, and good-tasting. Too little oxygen in raw water can unleash metals like iron and manganese, encourage harmful microbes, and make treatment more difficult and expensive. This study shows how smart use of real operating data and modern machine learning can forecast oxygen levels in a large drinking water plant, helping operators keep water quality high while saving time, energy, and laboratory costs.
Breathing life into water treatment
In many reservoirs and rivers, oxygen levels rise and fall with seasons, pollution, and water movement. When water becomes stagnant or overloaded with nutrients, oxygen can drop, creating conditions that release unwanted substances from sediments and favor troublesome microbes. In drinking water treatment plants, maintaining healthy oxygen levels is especially important for biological filters and for preventing the release of metals and other compounds that are hard to remove. Yet most past studies have focused on rivers or wastewater plants, leaving a knowledge gap for treated drinking water systems, where process steps such as coagulation, filtration, and chlorination change oxygen behavior in unique ways.
A decade of data from river to tap
The researchers drew on ten years of daily records from a full-scale water treatment plant in Ahvaz, Iran, which treats water from the Karun River for about 450,000 people. They used seven routinely measured properties of filtered inflow water—historical dissolved oxygen, nitrite, chloride, electrical conductivity, turbidity, pH, and temperature—to predict the oxygen level at the plant’s outlet basin. After carefully checking the data, handling outliers, and standardizing the measurements, they trained two popular tree-based machine learning models, Random Forest and XGBoost. These models learn patterns by building many decision trees and combining their results, allowing them to capture complex, nonlinear relationships without needing hand-crafted equations. 
Finding the signals that matter most
A key challenge was deciding which of the seven input measurements truly drive oxygen behavior and which add noise or unnecessary complexity. Instead of trusting a single ranking method, the team built a “hybrid” selection pipeline that looked at the data from several angles. Mutual Information highlighted variables most strongly linked to oxygen, Mean Decrease in Impurity captured which measurements were most useful inside the trees, and Permutation Importance tested how much predictions worsened when a variable’s values were scrambled. On top of this, the SHAP method explained, instance by instance, how each feature nudged the forecast up or down, offering both global and case-specific insight. Across all four techniques, three inputs clearly stood out: the previous day’s oxygen level, water temperature, and turbidity. Measures like pH and nitrite, while scientifically interesting, contributed little to improving predictions in this plant.
Accurate forecasts with leaner models
By focusing on the most informative inputs and dropping the least useful ones, the researchers cut model complexity by up to 70 percent while keeping accuracy almost unchanged. Both Random Forest and XGBoost reproduced measured outlet oxygen levels with high precision, explaining more than 93 percent of the variation and keeping typical errors below 0.3 milligrams per liter—well within the range useful for day-to-day operations. XGBoost performed slightly better overall, but both models were robust even when the input set was reduced. This efficiency matters in practice: fewer required measurements mean lower monitoring costs and faster, more reliable forecasts that can be integrated into plant control systems. 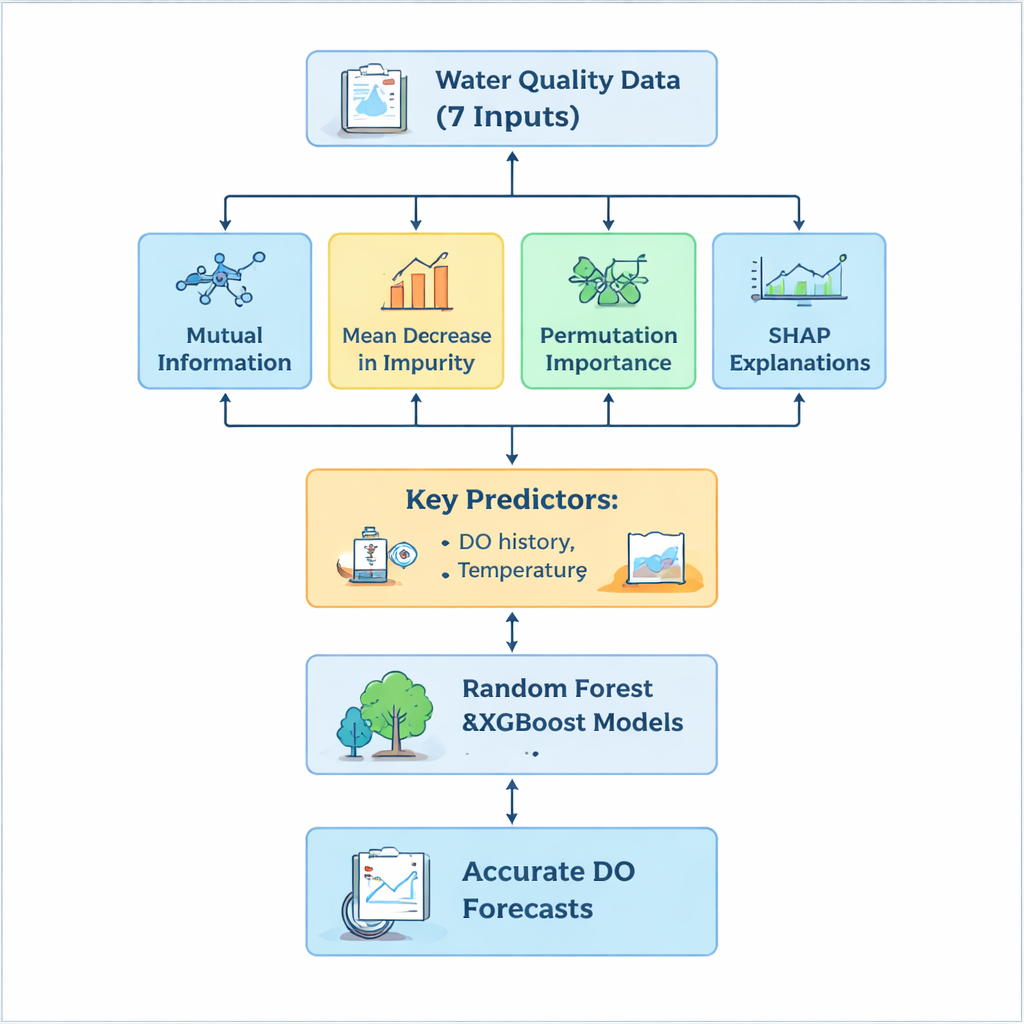
What this means for safe, efficient drinking water
For non-specialists, the bottom line is straightforward: by letting different data-driven methods “vote” on which measurements matter most, operators can build compact, transparent prediction tools that reliably forecast dissolved oxygen in real time. Knowing in advance when oxygen might dip allows a plant to fine-tune aeration, protect filters, and avoid conditions that release metals or support harmful microbes—all while avoiding overuse of energy and chemicals. Beyond this single plant and parameter, the same hybrid approach could be applied to other environmental questions, from tracking pollutants to anticipating algal blooms, offering clearer and more trustworthy guidance wherever water quality and public health intersect.
Citation: Hoshyarzadeh, R., Hafshejani, L.D., Tishehzan, P. et al. A hybrid framework of feature selection and interpretability for dissolved oxygen prediction in drinking water treatment plants. Sci Rep 16, 6912 (2026). https://doi.org/10.1038/s41598-026-37276-6
Keywords: dissolved oxygen, drinking water treatment, machine learning, feature selection, water quality monitoring