Clear Sky Science · en
Research on multi-scale feature detection of open-pit mine road cracks
Why tiny cracks in mine roads matter
Open-pit mines rely on long, winding roads to move thousands of tons of rock every day. When those roads crack, trucks can be damaged, traffic slows, and in the worst cases accidents happen. Yet these cracks often start as hairline fractures that are hard to see with the naked eye, especially in dusty, shadowy mine environments. This study presents an artificial intelligence (AI) method that can spot and map road cracks in open-pit mines more accurately and more efficiently than existing techniques, paving the way for safer and more cost‑effective operations.
The challenge of finding cracks in a harsh landscape
Checking mine roads is still often done by workers walking or driving slowly along the haul routes and visually inspecting the surface. This approach is slow, subjective, and nearly impossible to scale across the many kilometers of roads in a large mine. Classic image-processing tricks, such as simple thresholding or edge finding, also struggle because open-pit roads are visually messy: loose rock, tire marks, water puddles, and strong lighting contrasts all create patterns that can be mistaken for cracks. Even modern deep-learning models have trouble in this setting, because the cracks themselves are thin, broken, and sometimes partly buried under debris, and standard networks tend to lose these fine details.
An AI model that fuses details from many levels
To overcome these hurdles, the authors start from U‑Net, a popular image-segmentation network, and redesign how it combines information. Their Adaptive Feature Fusion Module acts like a clever mixer that gathers features from several scales in the image—from fine textures close to the pixel level up to broad shapes—and lines them up to the same size. It then uses two attention steps: one that learns which channels carry the most useful crack clues, and another that injects information about the broader scene. By dynamically re‑weighting these inputs, the module boosts faint crack signals while pushing down distractions such as shadows and gravel, leading to sharper crack edges in the output map. 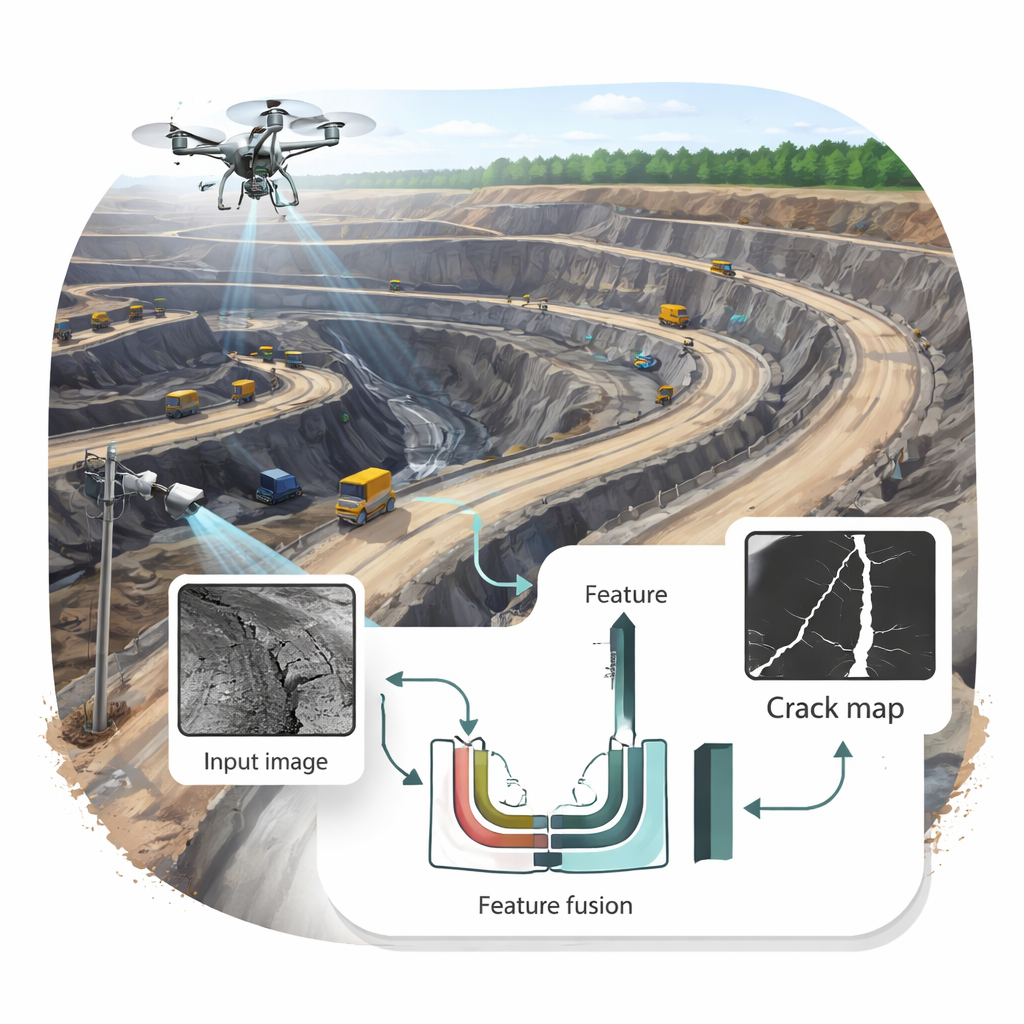
Teaching the network where to look
Beyond fusing features, the researchers introduce a Channel–Spatial Attention Module that teaches the network both what to look at and where to look. Inspired by self‑attention techniques widely used in language models, it first analyzes how different feature channels relate to each other, effectively asking which combinations tend to indicate “this is a crack.” It then adds a spatial attention stage that highlights the exact regions of the image where cracks are most likely to appear. In combination, these steps help the model tease out crack textures from cluttered backgrounds and keep thin, meandering fractures continuous, even when parts are obscured or low in contrast.
Making the AI fast enough for the field
High accuracy alone is not enough for a working mine, where computers may sit in trucks, field offices, or drones with limited processing power. To address this, the team applies a pruning strategy called Layer‑Adaptive Magnitude Pruning. In simple terms, it measures how important each group of internal weights is to the model’s decisions and then trims away the least useful ones, layer by layer. Up to a moderate pruning level, the network becomes leaner and faster—cutting roughly a quarter of its parameters and nearly a third of its computations—without harming, and in this case even slightly improving, detection accuracy. The final model can process an image tile in about a third of a second, making near real‑time crack screening feasible.
How well the system works in real mines
The researchers tested their method on 2,847 high‑resolution images collected from an open‑pit coal mine in Inner Mongolia, covering a wide range of road surfaces, lighting conditions, and crack shapes. Compared with the original U‑Net and several other well‑known segmentation models, the improved network achieved higher overlap with human‑drawn crack masks, fewer false alarms, and better continuity for small or partially hidden cracks. At the same time, it ran faster and required less memory than many competitors. These gains suggest that the approach is not only academically strong, but also practical for deployment on edge devices such as mine‑site servers, cameras, or drone platforms. 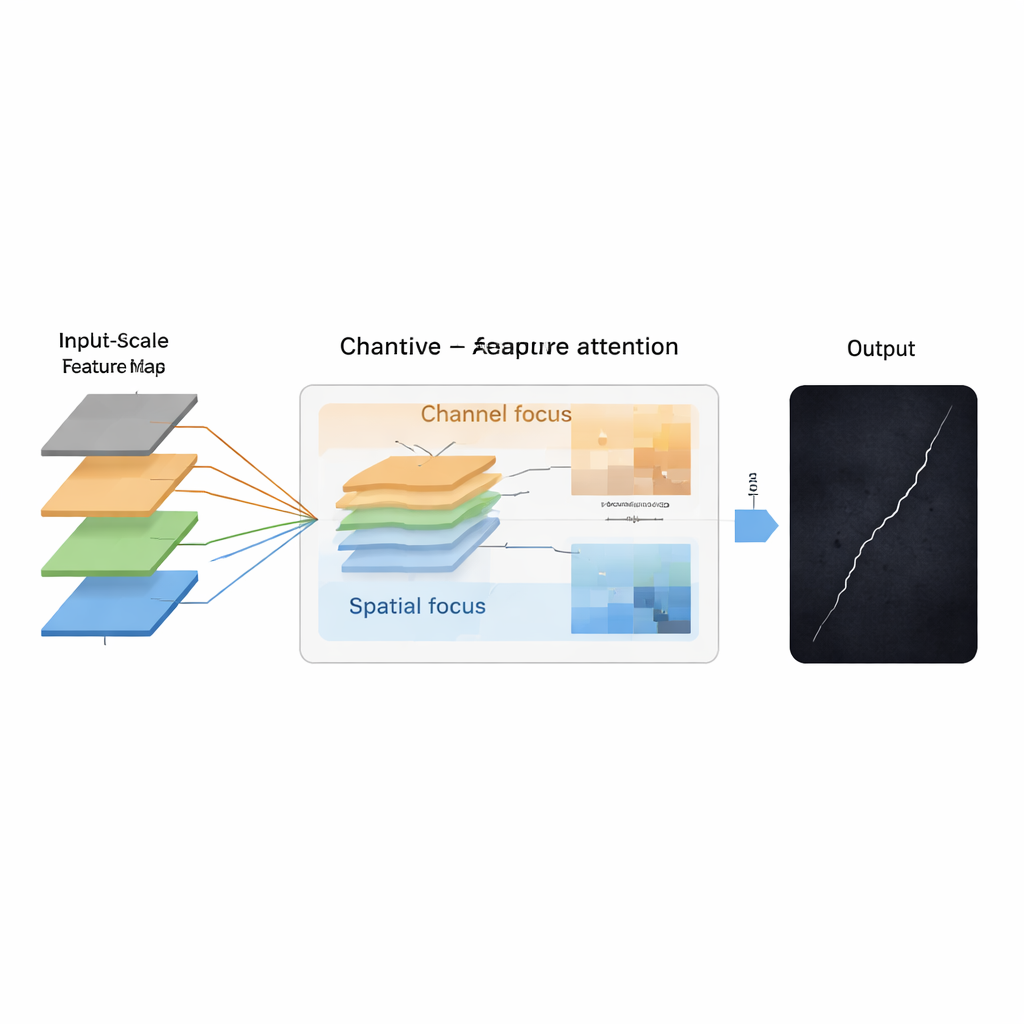
What this means for safer mine operations
For a non‑specialist, the bottom line is that this work turns raw pictures of dusty mine roads into accurate, machine‑readable crack maps using a compact AI model. That makes it possible to scan long stretches of road frequently—potentially by drones or vehicle‑mounted cameras—and pinpoint where maintenance is truly needed before small defects grow into serious hazards. While challenges remain in extremely noisy or unusual conditions, this feature‑fusion and attention‑based approach marks an important step toward smarter, more preventive road maintenance in large open‑pit mines.
Citation: Wang, L., Zhao, M., Yu, Z. et al. Research on multi-scale feature detection of open-pit mine road cracks. Sci Rep 16, 6060 (2026). https://doi.org/10.1038/s41598-026-37153-2
Keywords: open-pit mine roads, crack detection, computer vision, deep learning, infrastructure safety