Clear Sky Science · en
A method for detecting safety helmets underground based on the YOLOv11-SRA model
Why smarter helmet checks matter underground
Deep underground in mines and tunnels, workers depend on safety helmets as their last line of defense against rock falls, machinery and low ceilings. Yet in dark, dusty and crowded passages, it is hard for supervisors—and even conventional cameras—to tell who is properly protected. This paper presents a new computer-vision system, based on an improved YOLOv11-SRA model, that can automatically spot helmets and bare heads in real time, even when light is poor, views are blocked and people are far from the camera.
The dangers of relying on human checks
Traditional helmet inspection in mines still leans heavily on people walking through the tunnels to look for violations, or on turnstiles and checkpoints that workers must pass. These methods are slow, cover only a few locations and can miss risky behavior once people move deeper underground. Sensor-based helmets with tags or built-in electronics offer some automation, but they are expensive, hard to maintain in harsh conditions and require modifying every helmet. As mining expands and work shifts become longer, these older approaches struggle to provide the round-the-clock, mine-wide vigilance needed to prevent accidents.
Teaching cameras to see helmets in tough conditions
Recent advances in deep learning have transformed how computers interpret images, especially for spotting objects like cars or pedestrians. The YOLO family of algorithms is widely used because it can scan an image and locate objects in a single, fast pass—ideal for live video. However, underground scenes push these systems to their limits. Helmets may appear as tiny colored patches on a distant head, be half-hidden behind pipes or machinery, or blur into the background under dim, uneven lighting. The authors designed YOLOv11-SRA specifically to cope with these problems, so that mine cameras can reliably distinguish between protected and unprotected workers.
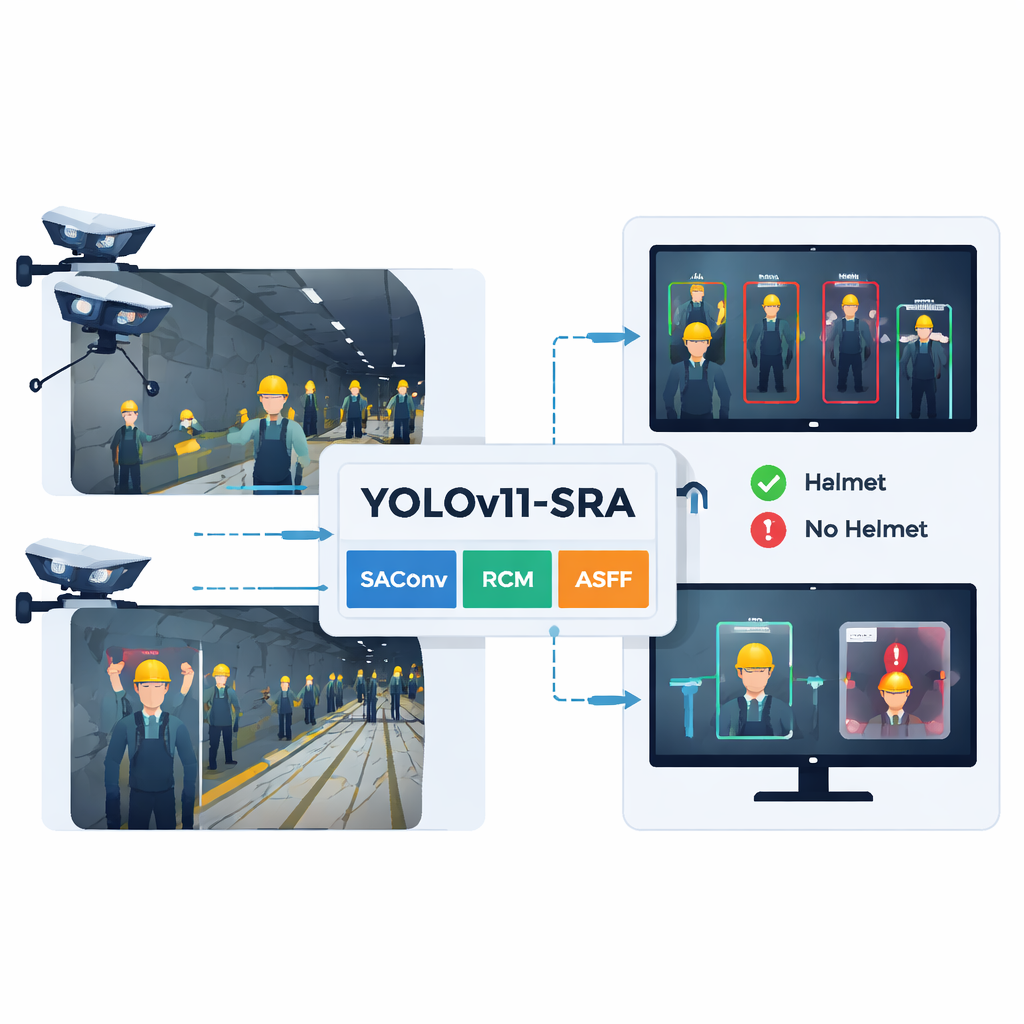
A three-part upgrade to a popular vision engine
The new model keeps the general structure of YOLOv11—input, backbone, neck and detection head—but adds three specialized modules. First, the SAConv block allows the network to look at each image with several "zoom levels" at once, so it can catch both small distant helmets and larger close-up ones without extra cost. Second, the RCM block guides the model to focus on long, rectangular regions that match the typical shape of a person’s head and shoulders in a tunnel, helping it trace helmet edges even when equipment or other workers get in the way. Third, the ASFF block blends information from multiple image scales, letting the system choose, pixel by pixel, which level best describes each part of the scene. Together, these upgrades reduce confusion between helmets and background clutter and sharpen the outlines of tiny or partially visible helmets.
Putting the system to the test
To see whether these ideas work in practice, the researchers trained and tested the model on CUMT-HelmeT, a public collection of underground surveillance images labeled with "helmet" and "no-helmet" cases, as well as other common objects. Because the raw dataset is relatively small, they expanded it fivefold by cropping, rotating and brightening images to mimic different camera angles and lighting. On this challenging benchmark, YOLOv11-SRA achieved a mean average precision of about 84% and a recall near 80%, clearly beating several well-known detectors, including newer YOLO versions, RetinaNet, SSD and Faster R-CNN. Despite its improved accuracy, the model remains compact and efficient: it uses fewer parameters and less computation than most competitors, and can analyze nearly 100 images per second on a modern graphics card, fast enough for real-time alerts.
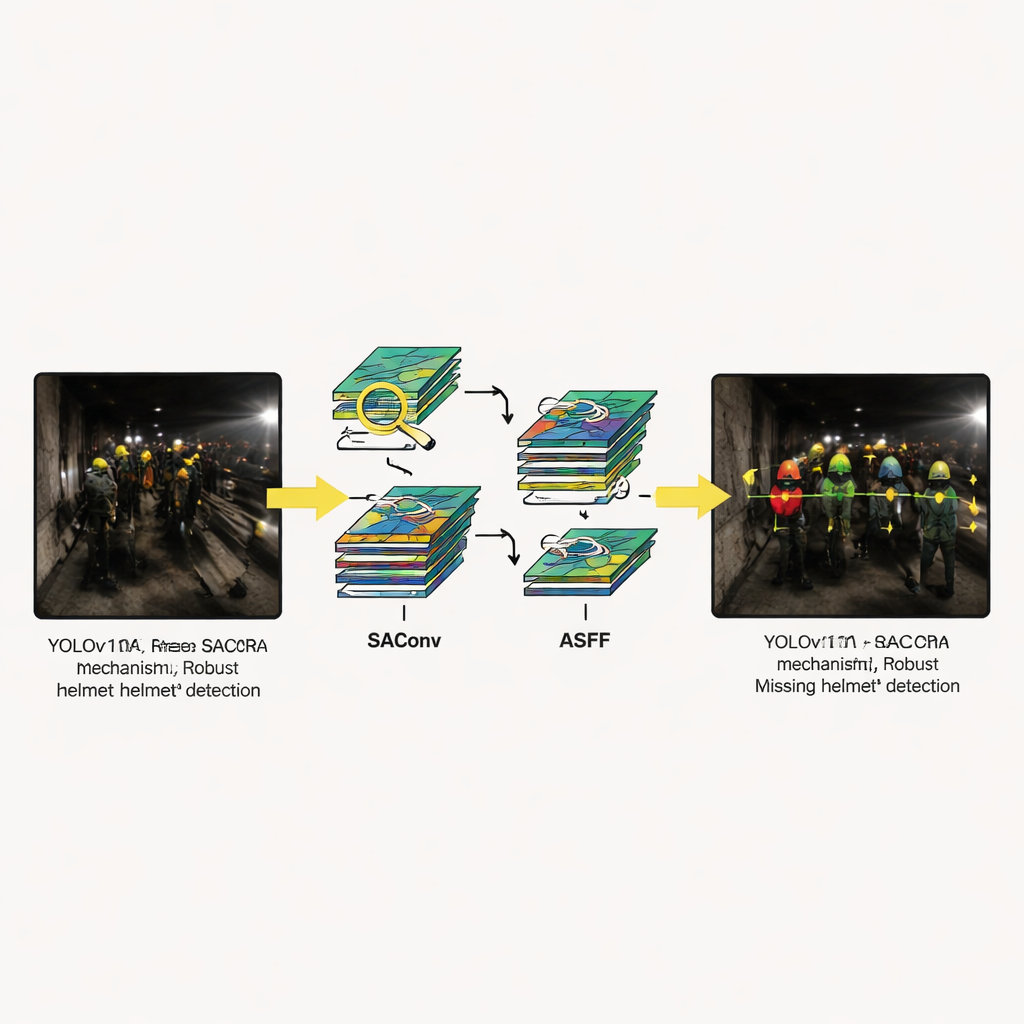
Seeing through darkness, dust and glare
Visual examples highlight how the system behaves in situations that regularly confound older methods: helmets that are half-obscured, scenes lit only by weak lamps, workers far from the camera and harsh reflections off shiny surfaces. In each case, YOLOv11-SRA produces more confident and consistent detections than rival models. It is less likely to miss small or dim helmets and better at avoiding false alarms when bright spots or pipes mimic helmet colors. Ablation studies—where the authors turn individual modules on and off—show that each part helps, but that the biggest gains come when all three are combined, confirming that the design works as an integrated whole rather than as a collection of isolated tricks.
From research prototype to safer shifts
In accessible terms, this work amounts to giving mine cameras a sharper, more adaptable "eye" for basic protective gear. By more reliably flagging workers who lack helmets, even in noisy, low-light video feeds, the YOLOv11-SRA system could help supervisors intervene earlier and reduce the chance of head injuries. Because the model is relatively lightweight, it can be deployed on embedded devices close to the cameras rather than only in distant data centers. The authors note that broader training data and further streamlining could make the approach even more robust, but their results already point toward smarter, more scalable safety monitoring in the demanding conditions of modern underground mining.
Citation: Wang, L., Wan, X., Shi, X. et al. A method for detecting safety helmets underground based on the YOLOv11-SRA model. Sci Rep 16, 6194 (2026). https://doi.org/10.1038/s41598-026-37148-z
Keywords: underground mining safety, helmet detection, computer vision, real-time monitoring, deep learning