Clear Sky Science · en
Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions
Why choosing the right expert really matters
When thousands of research proposals compete for limited funding, everything hinges on who evaluates them. If the assigned experts do not truly understand a proposal’s topic, promising ideas can be misunderstood or overlooked. This article explores how artificial intelligence, specifically modern language-processing systems, can help match proposals with the best possible experts more accurately and fairly than today’s keyword-based tools.
The problem with keyword checklists
Until now, expert assignment in major European funding schemes such as Marie Skłodowska-Curie postdoctoral fellowships has relied heavily on keywords. The current platform scans proposal descriptions and reviewer profiles to find matching terms, then suggests three experts plus alternatives. But Vice Chairs—senior scientists who oversee the process—end up changing around 40% of these assignments. That level of human correction makes the system labor-intensive, slow, and somewhat opaque, especially as up to 10,000 proposals arrive each year, often in emerging areas where fixed keyword lists perform poorly.
Reading research like a human, at scale
The authors developed a new assignment system that tries to “read” research more like a human expert would. Instead of relying on labels, it collects each expert’s publications via ORCID, a global researcher ID system, and builds a database of more than 2,800 article summaries. Both proposal abstracts and publication abstracts are then processed by GALACTICA, a large language model trained specifically on scientific texts. GALACTICA turns each abstract into a numerical fingerprint that captures its meaning, not just its wording. By comparing these fingerprints, the system can estimate how closely a proposal’s content aligns with each expert’s past work.
Three ways to add up expertise
One challenge is that experts may have dozens of publications. The system needs a single score per expert and proposal, so the authors tested three simple ways to combine similarities. The Sum strategy adds up all similarity scores, rewarding broad and repeated relevance. The Product strategy multiplies them, emphasizing consistent similarity across many publications but heavily punishing any weak match. The Maximum strategy keeps only the single strongest match, assuming that one very closely related paper may be enough to justify an assignment. These scores are then used to rank 48 candidate experts for each of 181 proposals, and the rankings are compared to the final expert choices made by Vice Chairs.
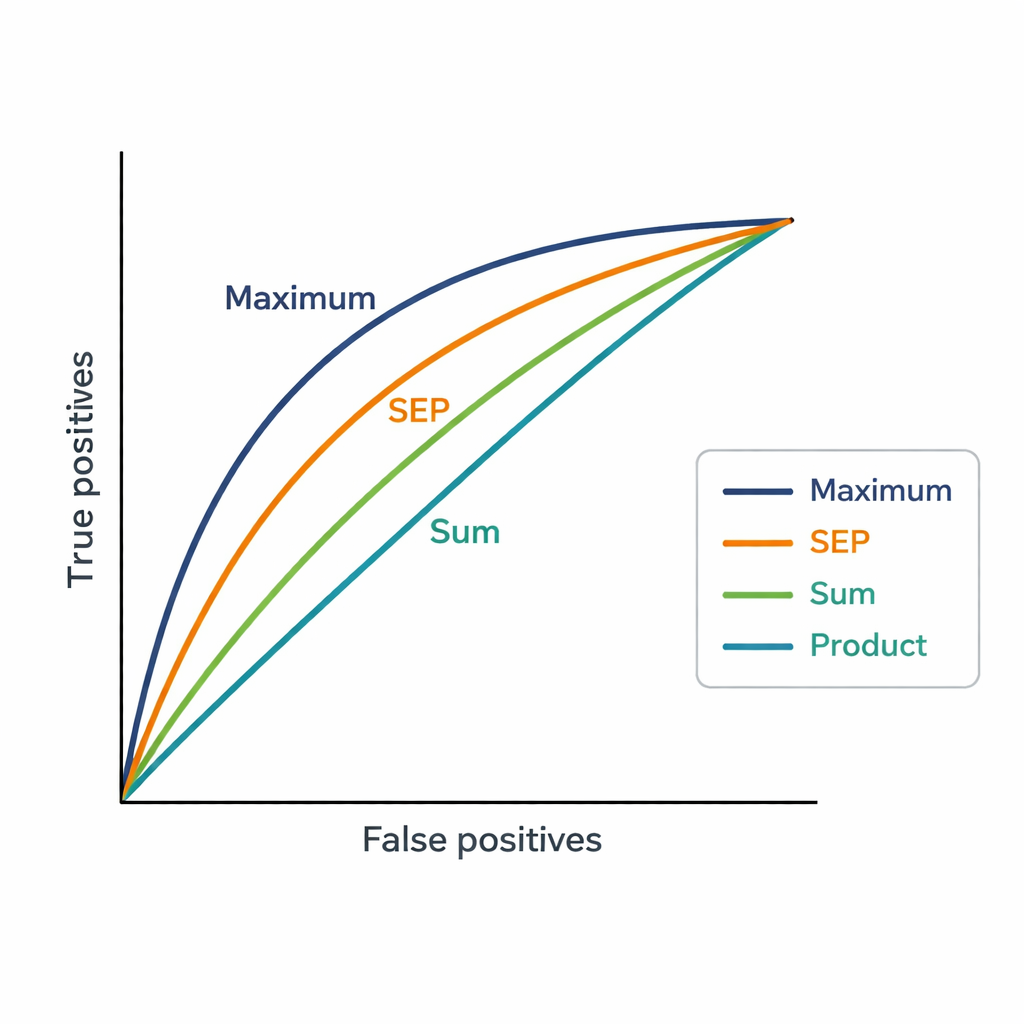
What the numbers reveal about human choices
The Maximum strategy matched Vice Chairs’ decisions most closely, achieving an AUC of 0.82, better than both the existing keyword-based system (AUC 0.75) and the other aggregation methods. In practice, the expert chosen by Vice Chairs usually appeared among the top four suggestions produced by Maximum. This suggests that, when assigning reviewers, people tend to focus on whether there is at least one very strong connection between an expert’s previous work and a proposal, rather than demanding that all of the expert’s publications align. The new method also generates much more fine-grained scores than the platform’s coarse “affinity” levels, allowing clearer distinction among closely ranked experts.
What this means for future grant reviews
To a lay reader, the takeaway is straightforward: by using AI that understands scientific language, funding agencies can better match proposals with the right experts, cut down on manual corrections, and make the process more consistent and transparent. While different ways of combining evidence from publications highlight different aspects of expertise, the simple “best single match” rule seems to mirror how humans actually decide. As such systems are tested more widely and with newer language models, they could become a key part of fairer and more efficient research evaluation worldwide.
Citation: Álvarez-García, E., García-Costa, D., De Waele, I. et al. Expert assignment system based on natural language processing for Marie Sklodowska-Curie actions. Sci Rep 16, 6396 (2026). https://doi.org/10.1038/s41598-026-37115-8
Keywords: peer review, expert matching, research funding, natural language processing, large language models