Clear Sky Science · en
Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models
Why predicting cancer spread matters
Lung cancer is still one of the deadliest cancers, even when surgeons remove all visible tumors. Many patients later develop hidden cancer deposits that pop up in the brain, bones, liver, or other organs. Doctors would like to know, soon after surgery, which patients are more likely to have this kind of distant spread so they can tailor follow-up visits and treatments. This study explores whether modern computer programs, known as machine-learning models, can help forecast who is at higher risk, using information that hospitals already collect in routine care.
Looking closely at many patients
The researchers examined records from 3,120 people with stage I to III lung cancer who had their tumors removed at a single cancer center in China. All had at least two years of follow-up. For each patient, the team gathered 52 types of information, including age, sex, body weight, smoking history, scan findings, operation details, lab tests, and whether they received additional treatments such as chemotherapy or radiotherapy after surgery. Over time, 596 of these patients developed distant metastases, while 2,524 did not. This real-world mix allowed the team to see which features were linked to future spread.
Teaching computers to recognize risk patterns
Instead of relying on a single formula, the scientists compared nine different machine-learning methods, from simple decision trees to more advanced techniques that combine many small models. They first used a mathematical filter to shrink the original 52 factors down to a smaller, more informative set. Then, in repeated rounds, they trained each model on part of the data and tested it on patients it had never “seen” before. Because only about one in five patients developed metastasis, they adjusted the training so that the computer would not simply predict “low risk” for everyone. They judged performance using several measures, including how well the models separated high- from low-risk patients and how closely predicted risks matched what actually happened.
Finding the most reliable model
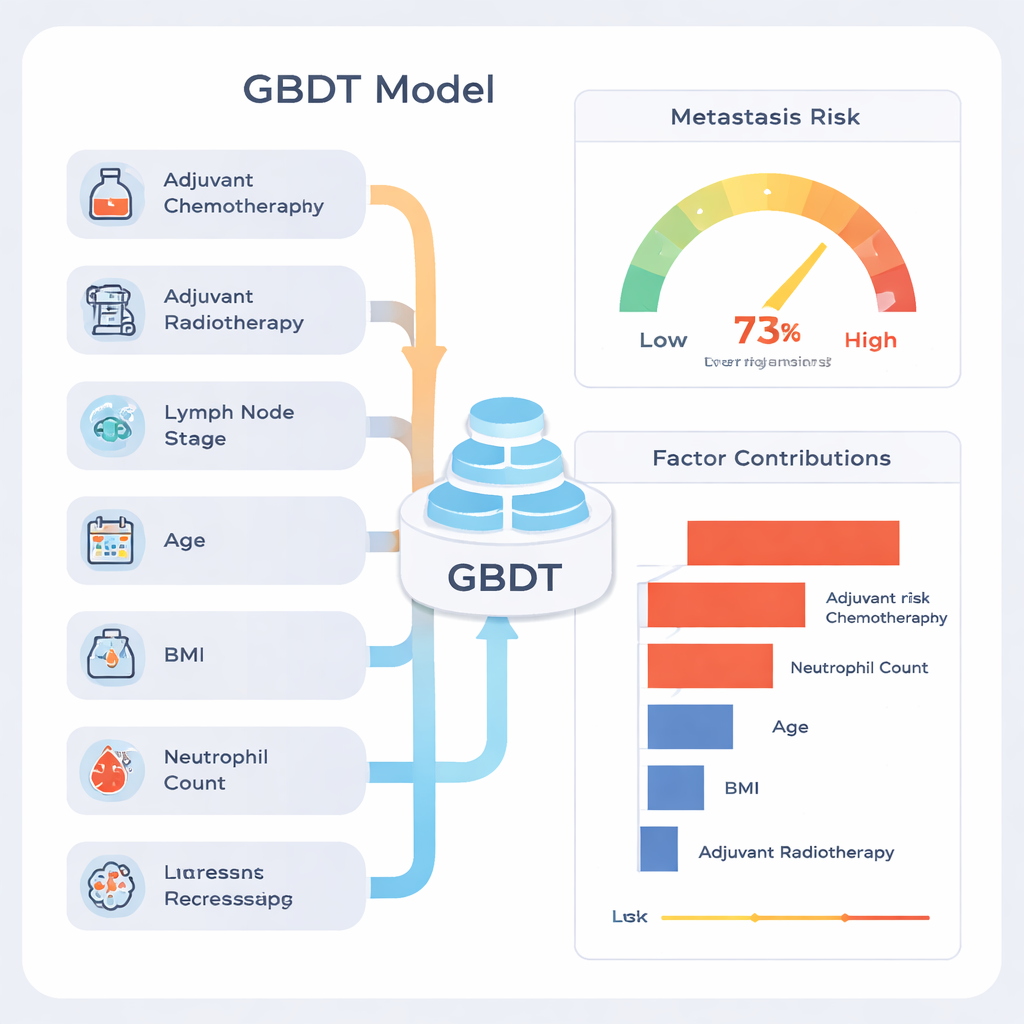
Among the nine approaches, one called Gradient Boosting Decision Tree (GBDT) stood out. On test data, it correctly ranked patients with an overall accuracy of about 77%, and its summary score for discrimination (the area under the ROC curve) was 0.81, which is considered strong for medical prediction tools. The model was especially good at identifying patients who would remain metastasis-free (high “negative predictive value”), meaning a low-risk result was usually reassuring. When the team examined how the model behaved across many different random splits of the data, its performance remained stable, suggesting it was not merely memorizing quirks of one particular subset.
What drives the model’s decisions
A common criticism of machine learning is that it can be a “black box.” To address this, the authors used an explanation method called SHAP, which assigns each factor a contribution to the final risk estimate for every patient. This analysis showed that the strongest signals were whether the patient had received chemotherapy or radiotherapy after surgery, how many lymph nodes contained cancer, age, body mass index (BMI), and the preoperative neutrophil count, a type of white blood cell. Patients with more advanced lymph-node involvement and signs of systemic inflammation tended to have higher predicted risk. The authors stress that high contributions from chemotherapy and radiotherapy do not mean these treatments cause metastasis; rather, they are markers that doctors had already judged the disease to be more aggressive, so these patients started out at higher risk.
How this could help patients in practice
Because the model uses information that most cancer centers already record, it could, after further testing, be built into hospital software. For a new patient who has just had lung surgery, the system could pull in their data and output a personalized probability of distant metastasis, along with a simple explanation of which factors push the risk up or down. Clinicians could then use this to decide who might need closer imaging follow-up, extra counseling, or enrollment in clinical trials, and who might safely avoid intensive surveillance. The study was done at a single hospital, so the tool still needs to be checked and refined in other regions and healthcare systems. But it offers a promising blueprint for combining routine clinical data with transparent machine learning to improve long-term care for people with lung cancer.
Citation: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Keywords: lung cancer, distant metastasis, machine learning, risk prediction, postoperative follow-up