Clear Sky Science · en
Innovative temporal summarization for complex video classification
Why smarter video summaries matter
From security cameras to streaming platforms, the world is recording more video than humans or computers can comfortably handle. Every second of footage contains dozens of frames, yet many of those frames are nearly identical. This paper explores a way to shrink long videos down to just the most telling moments, so that computers can still recognize actions like cooking, playing sports, or walking a dog—while using far less time, memory, and energy. Such advances could help bring powerful video analysis to everyday devices, from home robots to wearable cameras.

From endless frames to key moments
Traditional video classification systems try to recognize what is happening in a clip—say, chopping vegetables or shooting a basketball—by feeding long sequences of frames into heavy deep-learning models. These models must juggle both appearance (what things look like) and timing (how they move over time). Processing all frames leads to large datasets, high storage demands, and slow, power-hungry computation. The authors argue that many of these frames are redundant: if nothing major changes from one frame to the next, the system gains little by analyzing both. The central idea of the paper is to pick out a much smaller set of “key frames” that still captures the important changes in the scene.
Measuring change between frames
To find those key moments, the researchers design and compare several ways of measuring how much one frame differs from another. Instead of relying only on the classic Euclidean distance, which compares all pixels evenly, they try alternatives that are more sensitive to structural changes. Their main proposal, called the “Norm of Rows” distance, focuses on the largest difference across each row of pixels and then takes the most pronounced row as the measure of change between two frames. They also explore column-based distances and methods based on the eigenvalues of matrices that summarize how pixel differences are spread out. All of these approaches aim to better detect meaningful motion or scene changes, such as a hand reaching for a utensil or a player jumping.
How the summarization pipeline works
The summarization process begins with the very first frame of a video, which is treated as the initial key frame. The system then compares this key frame with each subsequent frame using one of the distance measures. Whenever the distance peaks above a chosen threshold, the corresponding frame is marked as a new key frame, indicating that something visually important has changed. The procedure then repeats using this new key frame as the reference, stepping through the video and collecting a chain of representative snapshots. By adjusting the threshold, the method can keep as little as 20 percent or as much as 80 percent of the original frames, trading off between compactness and detail. These summarized sequences are then passed to a standard deep-learning classifier that combines a powerful image network (ResNet-50) with a timing-sensitive LSTM module.
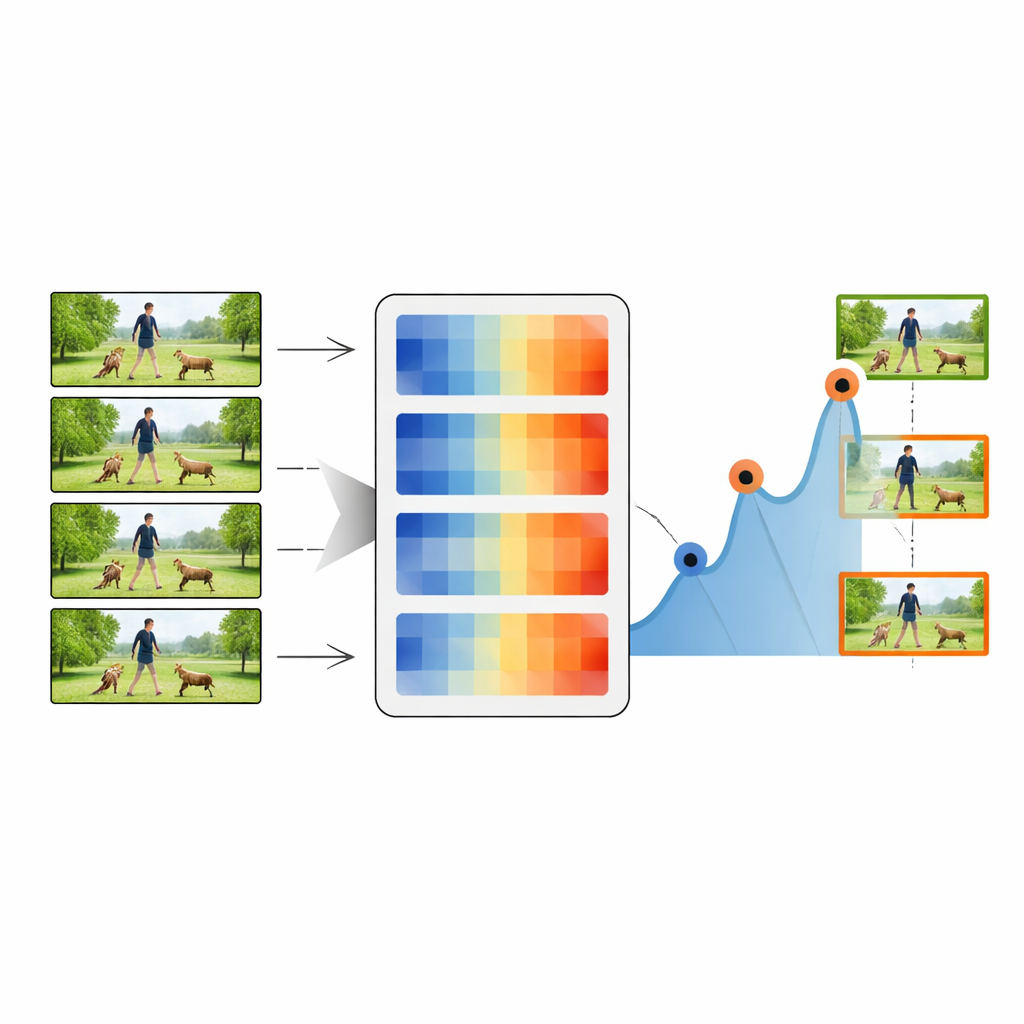
Putting the method to the test
The authors rigorously evaluate their approach on four well-known video collections: everyday kitchen activities (MMAC), sports and general actions (UCF101 and UCF11), and more varied, challenging clips (HMDB51). Across these benchmarks, the Norm of Rows distance consistently yields the best balance of speed and accuracy. With only about half the frames retained, their system reaches classification accuracies over 90 percent on several datasets—often matching or beating more complex methods that use full, unsummarized videos. They also measure how well the summaries cover the original content, how redundant the selected frames are, and how diverse the captured moments become. The proposed metric achieves high coverage with low redundancy, meaning it preserves the story of the video without repeating similar frames.
Faster decisions for real-world video
By cutting the number of frames roughly in half, the method nearly halves processing time on standard computer hardware and still gives noticeable speedups even on modern graphics cards. For real-world systems that must react in real time—such as surveillance, autonomous robots, or mobile apps—this reduction in workload is crucial. The study shows that a carefully designed distance measure can act as a smart gatekeeper, choosing which frames deserve attention and which can be safely skipped.
Takeaway for everyday use
In simple terms, this work shows that computers do not need to watch every single frame to understand what is happening in a video. By focusing on the moments when the picture truly changes and ignoring near-duplicates, the proposed technique keeps the essence of an action while slashing the amount of data. This makes high-quality video understanding more practical on limited hardware and opens the door to faster, more efficient tools for analyzing the growing flood of visual information in our daily lives.
Citation: Khan, A., Rahnama, A., Islam, A. et al. Innovative temporal summarization for complex video classification. Sci Rep 16, 7970 (2026). https://doi.org/10.1038/s41598-026-37111-y
Keywords: video classification, video summarization, keyframe selection, action recognition, computer vision efficiency