Clear Sky Science · en
YOLO-DC for vehicle detection using deformable convolutional networks and cross-channel coordinate attention
Why spotting cars from cameras really matters
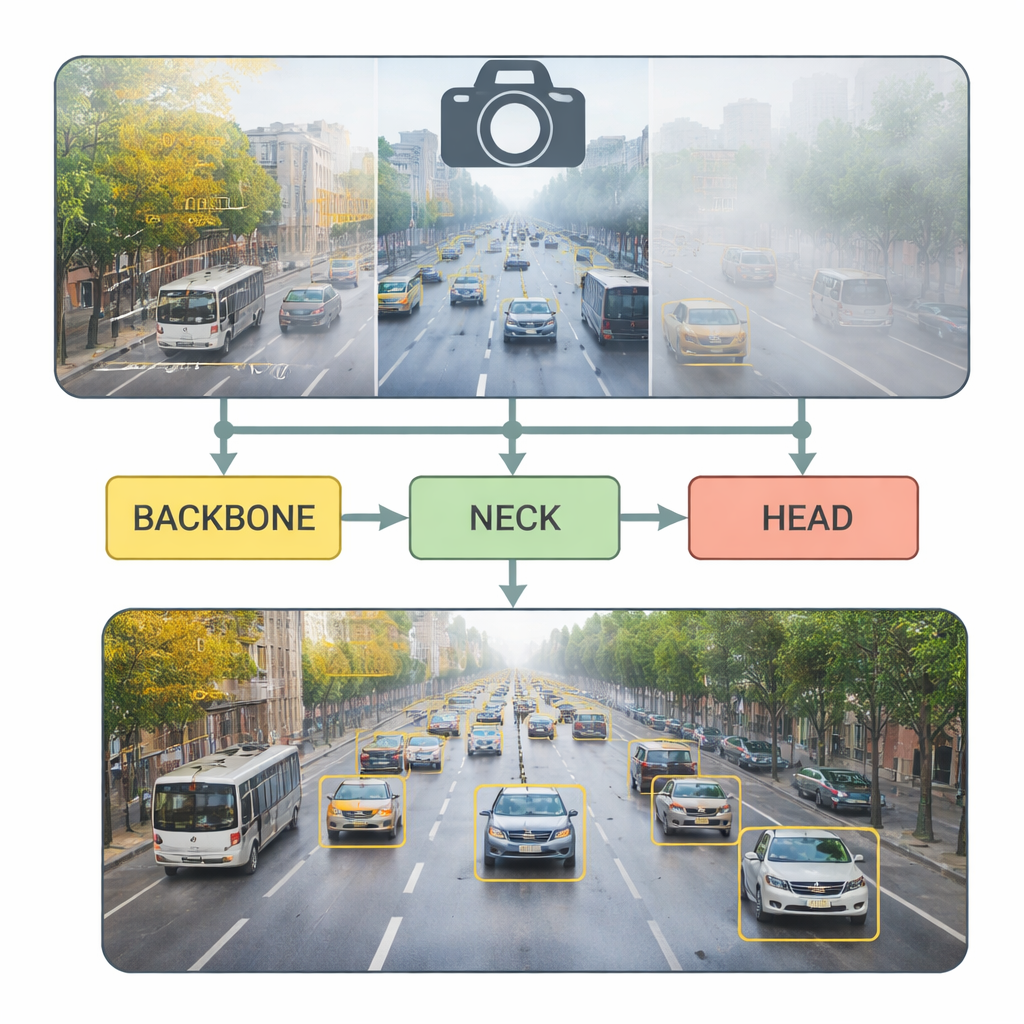
Modern cities depend on cameras watching over busy roads, helping manage traffic jams and paving the way for self-driving cars. But reliably picking out every vehicle in those camera feeds is surprisingly hard, especially when cars are tiny in the distance, partly hidden in congestion, or blurred by rain, fog, or darkness. This paper introduces YOLO‑DC, a new computer vision system that aims to spot cars, buses, and other vehicles quickly and accurately, even in messy real‑world conditions and on devices with limited computing power.
The traffic problem behind the research
Growing cities face clogged roads, more crashes, and rising emissions. Smart transportation systems promise help by monitoring traffic in real time and guiding both human and autonomous drivers. The core ingredient is fast, reliable vehicle detection in video. Earlier “two‑stage” algorithms scan images in multiple passes and can be very accurate, but are often too slow for real‑time use on roadside cameras or in cars. Newer “single‑stage” systems, such as the YOLO (“You Only Look Once”) family, trade a bit of complexity for much higher speed, making them popular in practice. However, they still struggle with small, overlapping vehicles and with harsh weather that hides details. YOLO‑DC builds on the latest YOLOv8 model and redesigns its inner layers to better cope with these challenges.
How YOLO‑DC sees more with smarter focus
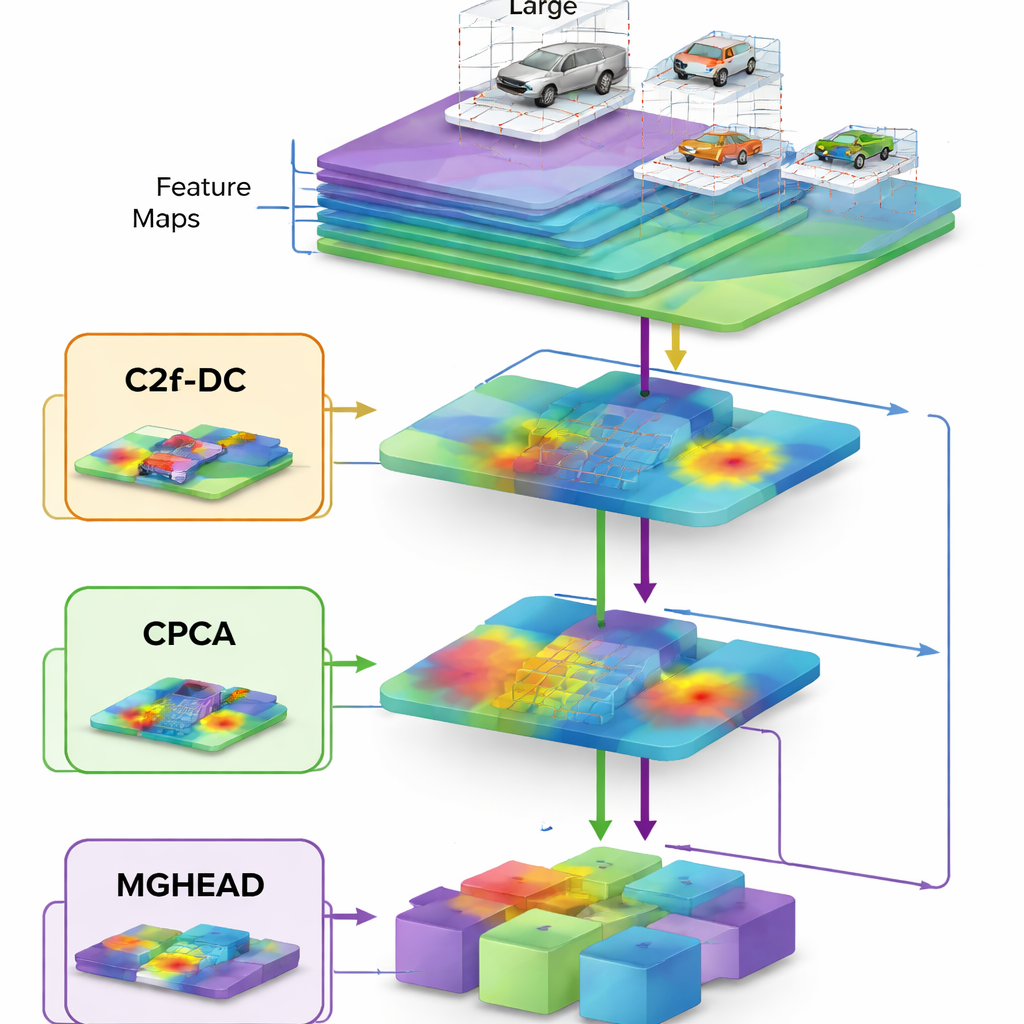
At the heart of YOLO‑DC is a revamped “backbone” network, the part that first digests raw images into abstract features. The authors introduce a mechanism called cross‑channel coordinate attention, which effectively teaches the network not only where to look in the image but also which types of visual patterns deserve more weight. Combined with so‑called deformable convolutions—filters that can bend their sampling pattern to follow slanted or oddly shaped vehicles—this backbone can better adapt to cars seen at different angles, scales, and positions. Instead of treating every patch of road equally, the system learns to emphasize the telltale outlines and textures that distinguish real vehicles from buildings, trees, or road markings.
Capturing small and distant vehicles without slowing down
The middle part of the model, known as the neck, is responsible for fusing information from coarse, zoomed‑out views with fine, close‑up details. YOLO‑DC upgrades this stage in two ways. First, a channel prior attention module helps the network suppress noise and highlight subtle cues from tiny vehicles far away in the frame. Second, a redesigned block inspired by the lightweight FasterNet architecture trims the number of operations by applying full convolutions to only a portion of the data and then mixing it efficiently. This careful redesign reduces both the number of parameters and the amount of memory traffic, letting the model run faster while actually improving accuracy—an unusual but highly desirable combination for edge devices like traffic cameras and in‑car computers.
Seeing vehicles across many sizes and in bad weather
The final stage, or head, decides where objects are and what they are. YOLO‑DC introduces multi‑scale grouped convolutions here, splitting feature maps into several channel groups that each use different filter sizes before being recombined. This gives the detector a richer sense of scale, so that it can recognize huge buses filling the frame, midsize trucks, and tiny cars barely visible in the distance, all at once. In extensive tests on the UA‑DETRAC dataset, which contains road scenes under cloudy, sunny, rainy, and nighttime conditions, YOLO‑DC matched or exceeded the accuracy of top‑tier detectors while using only a fraction of their computation and running hundreds of frames per second on modern hardware. On the DAWN dataset, designed specifically for fog, rain, snow, and sandstorms, the new model delivered especially large gains in heavy rain and dense fog, where traditional systems often fail.
What the results mean for everyday roads
For non‑experts, the main message is that YOLO‑DC is better at “seeing” real traffic the way it actually looks: crowded, messy, and often obscured by bad weather or poor lighting. By combining flexible filters that follow vehicle shapes with attention mechanisms that focus on the most informative regions, the system detects more vehicles, misses fewer, and runs quickly enough for live video analysis on modest hardware. That makes it a promising building block for smarter traffic management, more reliable accident monitoring, and safer autonomous driving—all while keeping processing costs low enough to deploy widely across city streets and future vehicles.
Citation: Liu, Z., Zhu, M., Gao, B. et al. YOLO-DC for vehicle detection using deformable convolutional networks and cross-channel coordinate attention. Sci Rep 16, 6284 (2026). https://doi.org/10.1038/s41598-026-37094-w
Keywords: vehicle detection, intelligent transportation, YOLO, adverse weather, real-time vision