Clear Sky Science · en
Construction and application of knowledge graph for seed quality standard documents
Why Seed Rules Matter to Everyone’s Food
Behind every bag of rice or packet of vegetable seeds lies a maze of technical standards that quietly protect crop yields and food security. Yet these seed quality rules are usually buried in dense PDF documents that are hard for farmers, regulators, and companies to search or interpret. This study shows how turning those static documents into a living “map” of connected facts—a knowledge graph—can make agricultural standards more transparent, searchable, and ready for the age of digital farming. 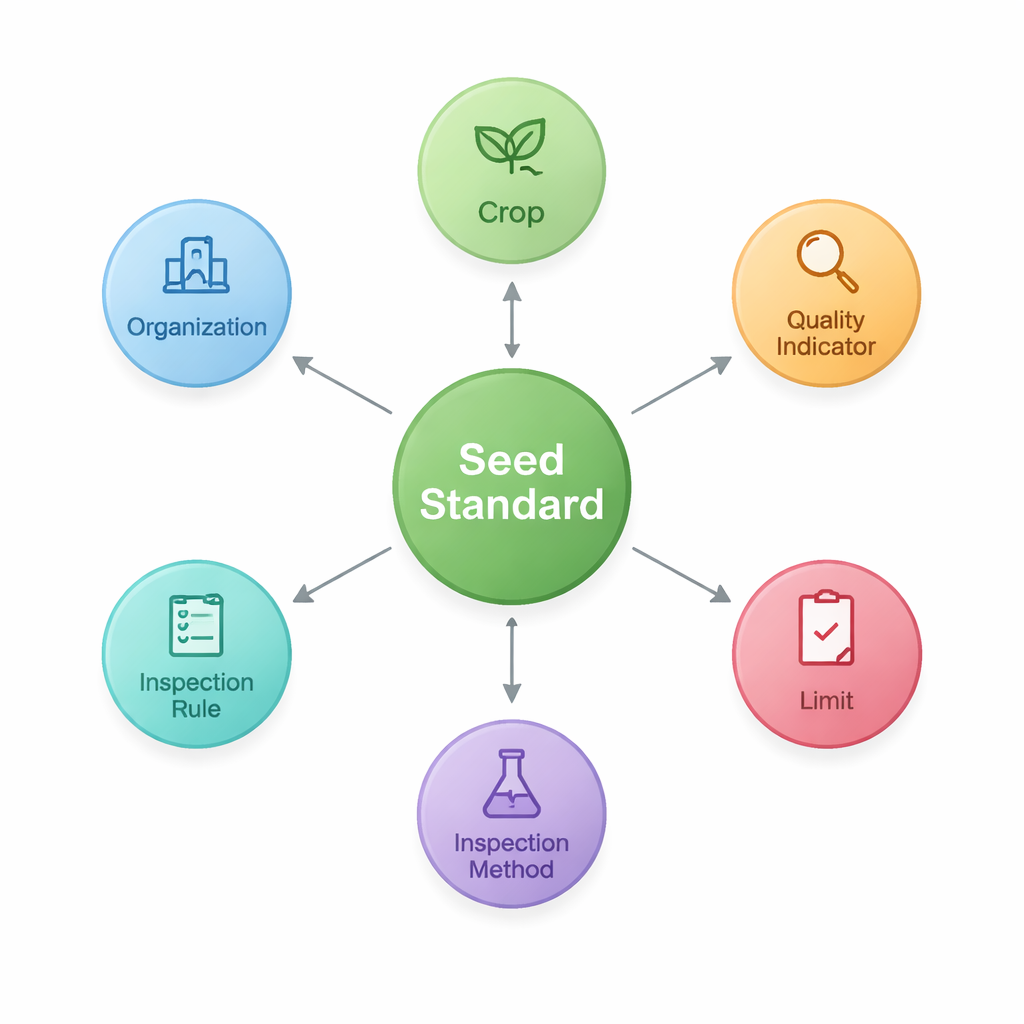
From Paper Standards to Smart Information
Seed quality standards spell out what counts as acceptable seed: how pure the batch must be, how many seeds should germinate, how much moisture is allowed, and the methods used to test these traits. In China, the number of such documents has exploded, and many still exist only as scanned pages or unstructured text. Simple keyword search struggles to answer practical questions like “What are the purity limits for this crop?” or “Which rule replaced an older one?”. The authors argue that to keep pace with rapid changes in agriculture, these standards must shift from human-readable pages to machine-understandable knowledge that can support fast queries, comparisons, and automated checks.
Building a Map of Seed Knowledge
To achieve this, the researchers first design an “ontology”—a shared blueprint that defines the main building blocks of seed standards and how they connect. They identify seven core types of things, including the standard itself, the crop it covers, quality indicators such as purity or germination rate, the numerical limits for those indicators, the inspection methods and rules, and the organizations that draft or publish the documents. This structure captures patterns like “Crop–Quality Indicator–Limit,” which are especially important in agriculture. Using this blueprint, they then store the extracted facts as nodes and links in a graph database (Neo4j), creating a web of 2,436 entities tied together by 3,011 relationships.
Combining Rules and Machine Learning
The real challenge lies in pulling clean, reliable facts out of messy source documents. Seed standards mix neatly formatted tables, rigid front-page metadata, and long, free-flowing text clauses. No single technique handles all of these well. The team therefore builds a hybrid extraction system. They use precise rule patterns (regular expressions) to read structured tables and basic document information, which tend to follow strict formats. For the more complex narrative text—such as detailed inspection rules—they train a modern language model pipeline called BERT–BiLSTM–CRF to recognize key names, codes, and technical phrases. This model learns from carefully labeled examples and can spot entities even when they appear in varied wording and long sentences. 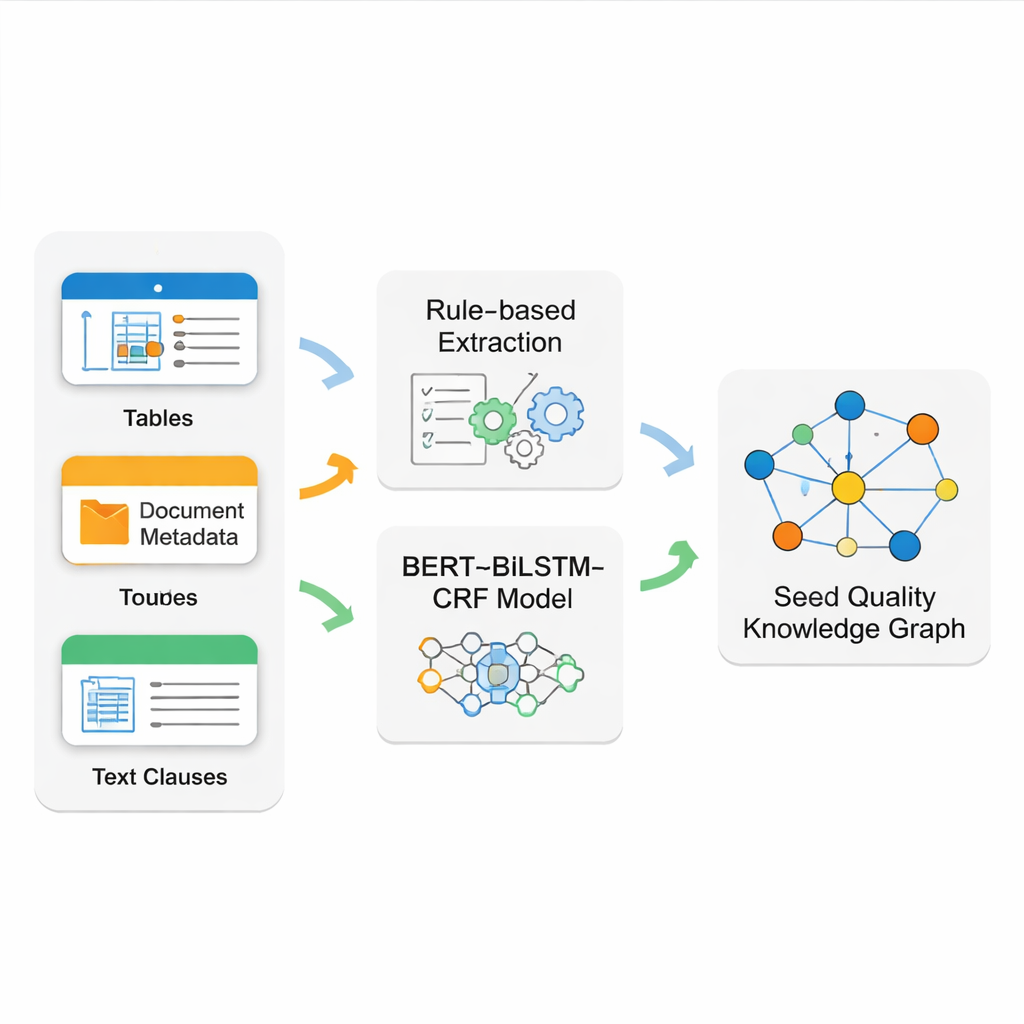
How Well the System Works in Practice
When tested, the hybrid approach performs strongly. The language model achieves an overall F1-score (a balance of accuracy and completeness) of about 91.6%, beating two commonly used baseline models. It is especially good at finding structured elements like standard codes and holds up well even on harder tasks such as long inspection rules. Once all of this information is loaded into the knowledge graph, users can visually explore how a given standard relates to earlier versions, which organizations drafted it, what crops and indicators it covers, and what testing methods it prescribes. Instead of paging through long PDFs, regulators and seed companies can run targeted searches and see connected results in seconds.
What This Means for Farmers and Food Systems
For non-specialists, the outcome is a smarter way to manage the rules that keep seeds reliable and crops productive. The study shows that by combining clear conceptual design with both rule-based and learning-based extraction, it is possible to turn scattered seed standards into a coherent, searchable knowledge base. This lays technical groundwork for “SMART” standards that computers can read, cross-check, and update as regulations change. In the long run, such tools could help farmers and agribusinesses quickly confirm whether seeds meet current quality requirements, support regulators in tracking revisions and gaps, and contribute to more stable harvests and food security.
Citation: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Keywords: seed quality standards, knowledge graph, agricultural digitization, named entity recognition, smart standards