Clear Sky Science · en
Knowledge-grounded large language model for personalized sports training plan generation
Smarter Workout Plans for Everyday People
Most fitness apps promise personalized training, but many still rely on generic templates that ignore how your body is actually doing. This paper introduces LLM-SPTRec, a new system that uses the same type of large language models behind modern chatbots, combined with vetted sports science knowledge and wearable data, to build safer, more effective workout plans. For anyone who has wondered why their app keeps suggesting the wrong exercises—or worried whether AI-made health advice is really safe—this work shows how to make digital coaching both more personal and more scientific.
Why Traditional Fitness Apps Fall Short
Conventional recommendation engines, like those that suggest movies or products, struggle when applied to exercise. They often copy and reuse standard templates, have trouble handling limited data for new users, and rarely look at how your body changes from day to day. Worse, they are not designed for high-stakes decisions where safety matters. General-purpose language models are good at talking about workouts, but because they are trained on broad internet text, they can “hallucinate” risky advice or skip important rest days. The authors argue that for exercise planning—where poor guidance can cause injury or overtraining—AI must be grounded in verified sports science and must track a person’s changing condition over time.
Building a Rich Picture of the Individual
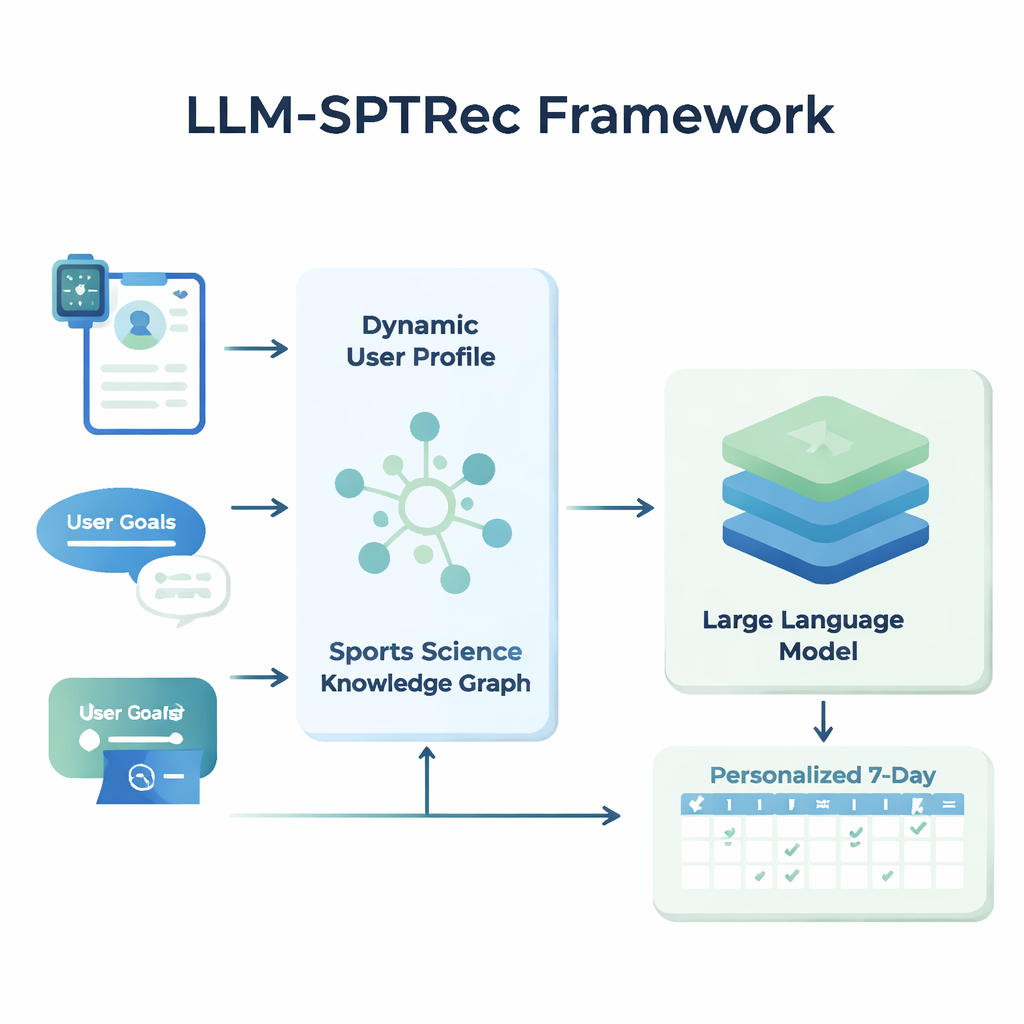
At the core of LLM-SPTRec is a module that creates a detailed snapshot of each user. Instead of only storing age, gender, or experience level, the system fuses three kinds of information: static traits (such as training history), dynamic signals (like heart rate, heart rate variability, sleep score, and previous workouts from wearables and logs), and free-text goals written by the user. A transformer-based model—related to the technology behind modern language models—learns patterns in these time-series data, such as how a hard workout yesterday might affect today’s readiness. An attention mechanism then weighs which signals matter most at a given moment, combining them into a single numeric representation of the user’s current state.
Teaching the AI Real Sports Science
To prevent unsafe or unscientific recommendations, the researchers built a Sports Science Knowledge Graph, essentially a structured map of expert-approved facts. It includes thousands of entries that link exercises to muscles, movement types, equipment, common injuries, and training principles like progressive overload and specificity. For each user, the system pulls out the most relevant parts of this graph—such as which muscles are targeted by bench press and which movements are bad for shoulder problems—and turns them into readable text that is fed into the language model alongside the user profile. The language model is then asked, via a carefully designed prompt, to generate a multi-day training plan in a structured format, obeying rules like rotating muscle groups between days and avoiding known contraindications.
Keeping Plans Structured, Safe, and Improving Over Time
LLM-SPTRec does more than just generate text. A validation module checks each plan against hard rules, such as not overloading the same primary muscle groups on consecutive days, and flags conflicts with injury risks stored in the knowledge graph. If a plan fails these checks, the system prompts the model again, explicitly pointing out what went wrong, until a safe plan is produced. Training the system also happens in two stages. First, it learns from a large collection of expert-designed plans. Then it is further refined using feedback, where simulated or real user ratings reward plans that are coherent, aligned with goals, and satisfying to follow, while heavily penalizing unsafe suggestions. This feedback loop nudges the model toward recommendations that work better in practice.
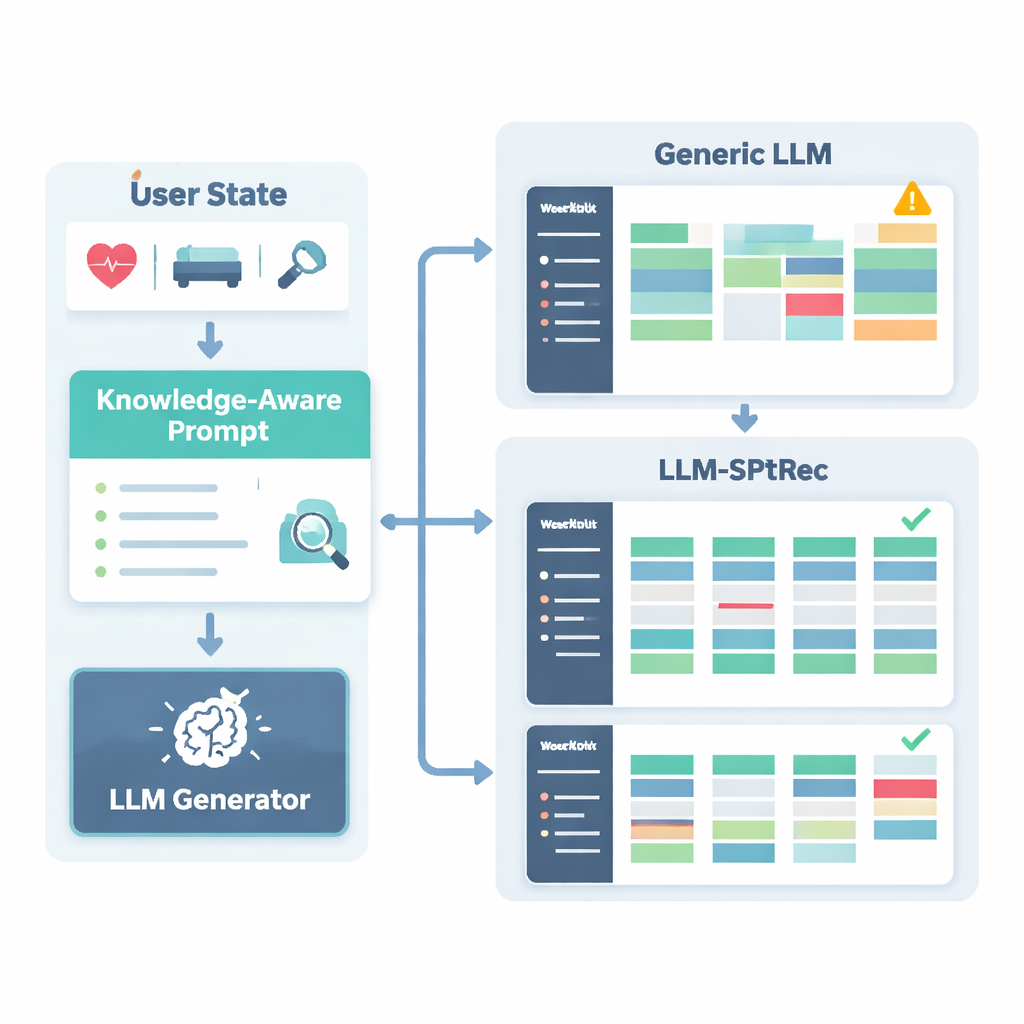
How Well the System Performs in Practice
The authors tested LLM-SPTRec on a large, real-world dataset called SportFit-1M, which combines anonymized data from fitness apps and wearable devices, covering tens of thousands of users and millions of training logs and physiological records. They compared their system with strong baselines: classic collaborative filtering, a sequence model that only looks at past choices, a cutting-edge knowledge-graph recommender, and a general-purpose language-model-based framework. LLM-SPTRec beat all of them not only at picking appropriate exercises, but—more importantly—at producing complete plans that experts judged to be more coherent and more closely aligned with user goals. Predicted user satisfaction scores were higher as well, and a small human study with certified trainers rated its safety much better than that of a general language model without sports-specific grounding.
What This Means for Future Digital Coaching
For a layperson, the takeaway is that smarter, safer AI coaching is possible when three ingredients come together: rich data from your devices, expert sports science encoded as structured knowledge, and powerful language models whose creativity is carefully guided and checked. LLM-SPTRec shows that such a combination can generate adaptive, day-by-day training plans that respect your body’s changing state and your personal goals, while reducing the risk of harmful or nonsensical advice. Looking ahead, the same recipe could extend beyond workouts to nutrition, injury rehabilitation, or even mental well-being, pointing toward a future in which AI assistants act less like generic chatbots and more like knowledgeable, safety-conscious digital coaches.
Citation: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Keywords: personalized training, sports science AI, fitness recommendation, wearable data, knowledge graph