Clear Sky Science · en
Interpretation drift in explainable AI under label noise
Why AI Explanations Can Quietly Go Wrong
Many people now rely on artificial intelligence not just for answers, but for reasons: Why was a loan denied? Why did a system flag a patient as high risk? This study shows that even when an AI model’s accuracy looks reassuringly stable, the story it tells about why it made a decision can drift dramatically if the training data contain mistakes. That hidden shift in explanations—what the authors call “interpretation drift” —could mislead professionals who depend on AI to justify important choices.
When Clean Data Meet Messy Labels
Most modern AI systems are “black boxes,” offering predictions without clear reasons. To make AI more transparent, many applications turn to rule-based models that resemble human if–then reasoning: for example, “if blood pressure is high and age is over 60, then risk is high.” These rule sets are especially attractive in sensitive areas like healthcare, law, and finance, where users need to inspect and trust the logic. But real-world data are rarely perfect. One common problem is label noise—cases in which the supposed “correct answer” in the training data is wrong, such as a misrecorded diagnosis or a mislabeled customer outcome. While label noise is known to hurt prediction quality, its impact on the stability of AI explanations had not been systematically studied.
Testing How Explanations Hold Up Under Noise
The authors evaluated how robust rule-based explanations remain when labels are gradually corrupted. They used four different datasets from healthcare, banking, liver disease, and even number theory, all set up as yes–no prediction tasks. Three rule-learning methods were compared: two popular, fast algorithms (IREP and RIPPER) and a more computationally intensive approach called Human Knowledge Models (HKM), which explicitly aims to produce very simple, human-like rule sets. For each method, the researchers repeatedly trained models while randomly flipping a growing fraction of the training labels—from almost perfectly clean data all the way to near-complete nonsense. They tracked two things in parallel: how well the models still predicted on a clean test set, and how much the learned rules changed compared with those from noise-free data.
Accuracy Steady, Logic in Flux
On the surface, the results could lull users into a false sense of security. For moderate noise levels, especially with the HKM method, predictive performance appeared relatively stable when measured by the common F1 score. Yet a closer look at the rule sets told a different story. Using a similarity measure that compares collections of rules, the authors found that even modest amounts of label noise rapidly eroded the overlap between the original and noisy explanations. In other words, the model might still be right about many cases, but for increasingly different reasons. More complex rule sets were especially fragile: as the number of conditions in a rule grew, small changes in the data more easily fractured or replaced those rules, accelerating the loss of interpretability stability.
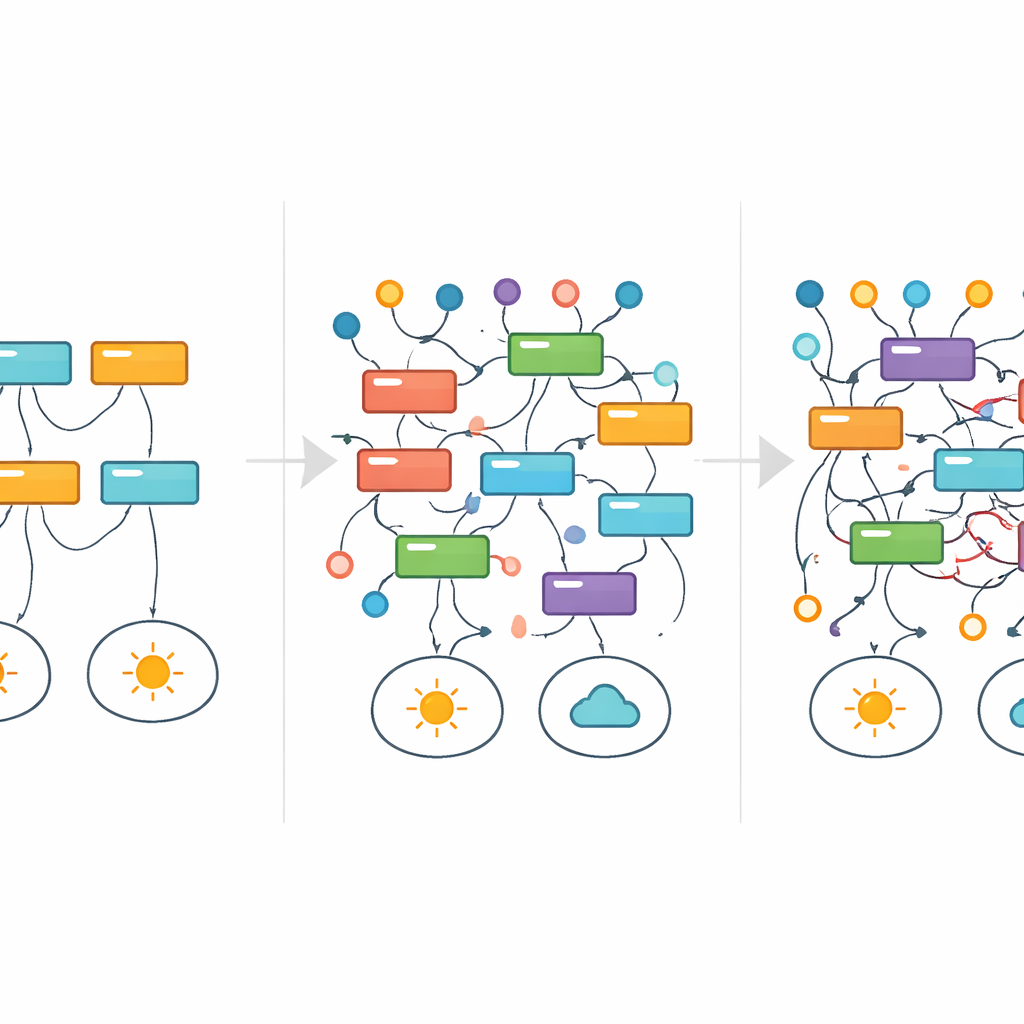
Following Rules as They Appear and Vanish
To visualize how individual explanations survive or fail as noise rises, the researchers borrowed a tool from medicine: survival analysis. Instead of tracking patient survival over time, they tracked how long a particular rule continued to appear among the best models as label noise increased. Rather than gently fading away, many rules flickered in and out—a sign that entirely different explanations could dominate at different noise levels, even for the same underlying task. In a simple number-divisibility dataset, for example, clean and mathematically correct rules were gradually replaced by broader approximations and eventually by convoluted, seemingly arbitrary patterns that still fit the corrupted labels. Throughout much of this process, headline performance metrics did not clearly signal anything was amiss.
What This Means for People Who Rely on AI
The central message is that “trustworthy” AI cannot be judged by accuracy alone. Even models that present their logic in human-readable rules can quietly change their reasoning when the labels they learn from are imperfect—which is exactly the situation in most real-world databases. The authors argue that developers and regulators should treat explanation stability as a first-class requirement, alongside accuracy and fairness. New metrics that directly measure how consistent a model’s explanations remain under noise, and tools that alert users to interpretation drift, will be essential if we want AI systems whose stories about the world are as reliable as their predictions.
Citation: Raikovskaia, A., Rakhimzhanov, N. & Pianykh, O.S. Interpretation drift in explainable AI under label noise. Sci Rep 16, 8528 (2026). https://doi.org/10.1038/s41598-026-37070-4
Keywords: explainable AI, label noise, model interpretability, rule-based models, interpretation drift