Clear Sky Science · en
The evolution of object detection from CNNs to transformers and multi-modal fusion
Teaching Computers to See Everyday Objects
Every time your phone tags friends in a photo, a car spots a pedestrian, or a doctor’s tool highlights a tumor on a scan, a quietly powerful technology is at work: object detection. This survey article explains how object detection has rapidly evolved over the past decade, from early image-processing tricks to today’s transformer-based and multi-sensor systems, and why these advances matter for safer streets, smarter robots, and more accurate medical diagnoses.
From Pixels to Recognizable Things
Object detection is the task of finding and labeling specific items in pictures or video—cars, cyclists, animals, medical structures, and more. The article begins by mapping out how widely this capability is used: in autonomous driving, surveillance, medical imaging, and robotics. Early systems relied on hand-crafted rules to pick out shapes and textures, but modern approaches learn directly from data using deep learning. Two broad families now dominate: convolutional neural networks (CNNs), which are very good at spotting local patterns such as edges and corners, and transformers, which excel at understanding the broader scene and relationships among distant objects. Together, they define how current machines “see” the world.
How Classic Vision Engines Work
CNN-based methods still power many real-time applications. They scan images with small filters to build up richer and richer feature maps, then feed these into detection heads that draw bounding boxes and assign labels. The survey explains two main strategies. Two-stage systems like Faster R-CNN first propose likely object regions, then refine them, often achieving high accuracy at a computational cost. One-stage systems like the YOLO family skip the proposal step and predict boxes and labels in a single pass, trading a bit of accuracy for speed. Recent versions of YOLOv5 and YOLOv8 have been heavily tuned—adding smarter feature pyramids for small objects, lightweight building blocks for edge devices, and improved loss functions—to reach hundreds of frames per second while staying competitive on tough benchmarks.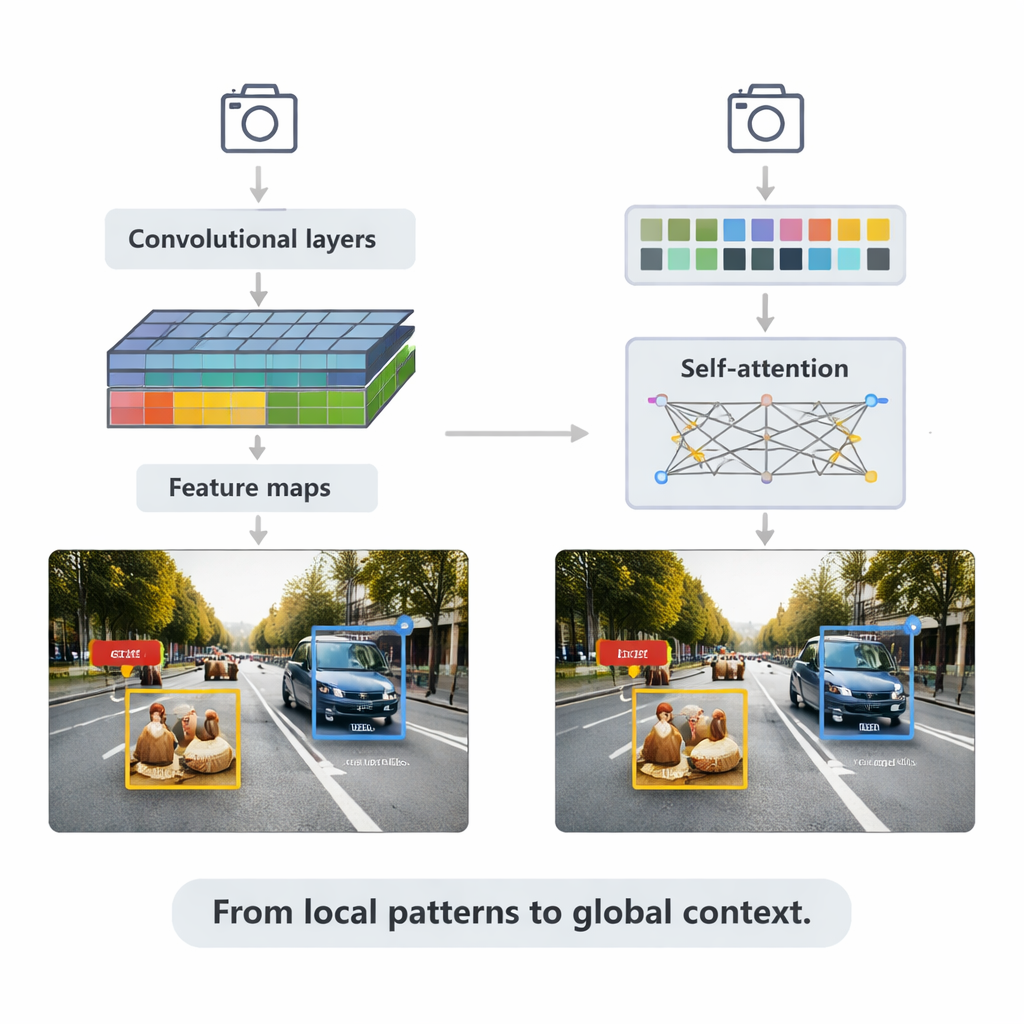
Transformers and the Power of Context
The article then turns to transformers, a newer architecture borrowed from language models. Instead of focusing only on local neighborhoods, transformers use “self-attention” to compare every patch of an image with every other patch, learning which regions are most relevant to each decision. Detection Transformer (DETR) and its successors remove many hand-designed tricks, aiming for cleaner, end-to-end pipelines. Variants such as Deformable DETR and RT-DETR reduce computation and improve training speed, allowing transformers to run in real time while achieving some of the highest accuracy scores on the widely used COCO benchmark. These models particularly shine in complex scenes with overlapping objects and confusing backgrounds, where global context helps distinguish, for example, a pedestrian partly hidden behind a car.
Blending Cameras, Lasers, and Language
Real-world conditions—fog, darkness, glare, clutter—often defeat single-sensor systems. A major focus of the survey is multi-modal fusion: combining data from regular cameras (RGB), depth sensors like LiDAR, thermal cameras, and even text descriptions. The authors introduce a clear taxonomy for how this blending can happen: early fusion mixes raw data up front, middle fusion merges learned features inside the network, and late fusion combines separate detectors’ outputs at the end. Modern “fusion transformers” use attention mechanisms to align these streams, so that crisp distance measurements from LiDAR, rich appearance from RGB images, and semantic hints from language reinforce one another. This approach boosts detection in autonomous driving, medical imaging, video understanding, and text-rich scenes.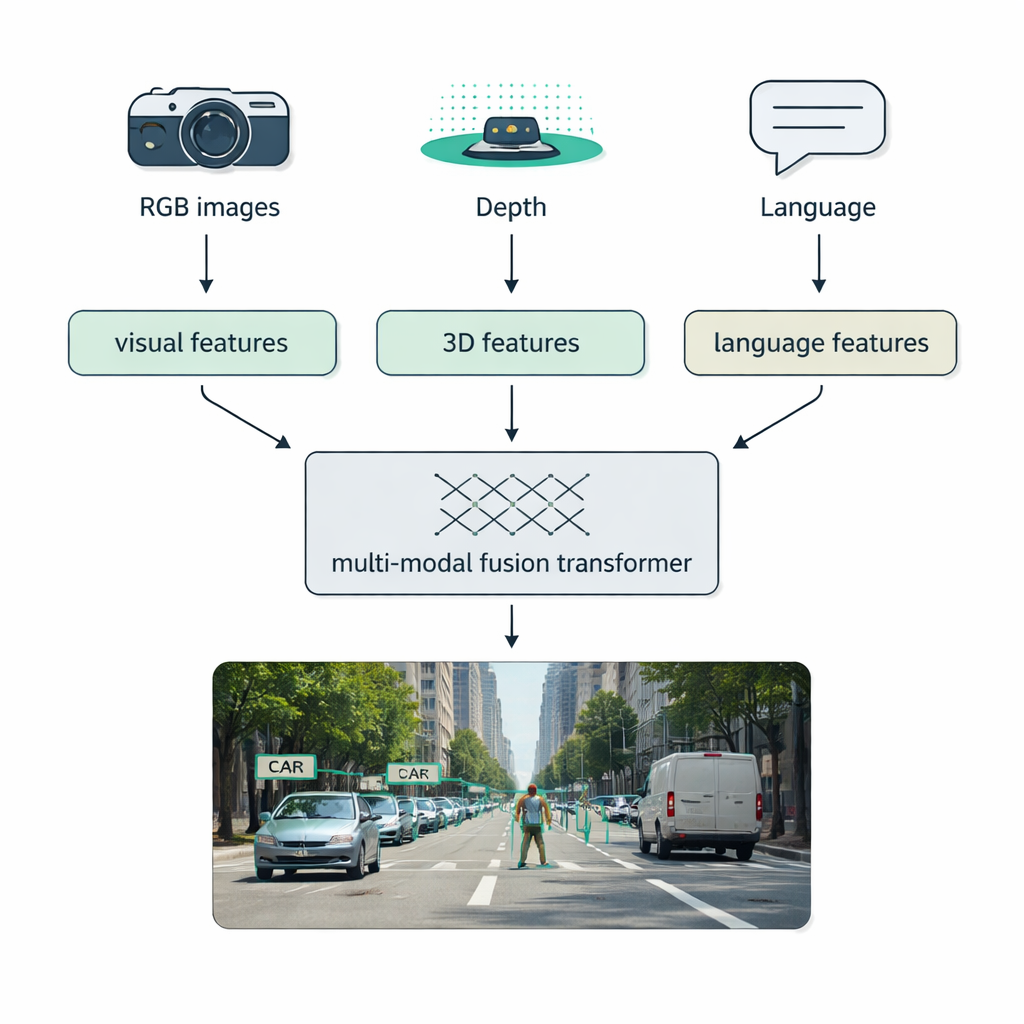
Benchmarks, Limits, and What Comes Next
Across standard tests like MS COCO, the survey compares CNN and transformer detectors by both accuracy and speed. Classic two-stage CNNs remain strong but are slower, YOLO-style models dominate on lightweight hardware, and transformer-based systems now lead on accuracy while closing the speed gap. Specialized infrared methods achieve very high scores in low-visibility conditions. Yet tough problems remain: very small or extremely large objects, heavy occlusion, changing weather and lighting, and the need to run reliably on tiny devices. Looking ahead, the authors highlight trends toward unified perception models that handle detection, segmentation, and captioning together, and “foundation models” that fuse vision and language to recognize objects described in plain text, even if they were never labeled in the training data.
Why This Matters for Everyday Life
For non-specialists, the key message is that object detection is moving from narrow, hand-tuned systems toward flexible, general-purpose vision engines that can adapt to new tasks, new environments, and new sensors. CNNs provide fast, efficient pattern recognition; transformers add a more global, context-aware understanding; and multi-modal fusion ties in extra clues from depth, temperature, and language. Together, these advances promise cars that better anticipate hazards, tools that assist doctors with more confidence, and home devices that interact more safely and intelligently with their surroundings—bringing machine perception closer to the richness of human sight.
Citation: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Keywords: object detection, computer vision, deep learning, transformer models, multi-modal fusion