Clear Sky Science · en
Mobility functional status ascertainment in electronic health records using large language models
Why walking ability is a powerful health signal
As people live longer, doctors are paying more attention not just to how long we live, but to how well we can move, walk, and take care of ourselves. Difficulties getting out of a chair, climbing stairs, or getting around town often show up long before a medical crisis. Yet the most detailed descriptions of a person’s daily abilities are usually buried in free‑text doctor and therapist notes inside electronic health records, where they are hard for computers to find. This study explores whether modern large language models—the same kind of AI behind many chatbots—can reliably read those notes and turn descriptions of movement into structured, searchable information.
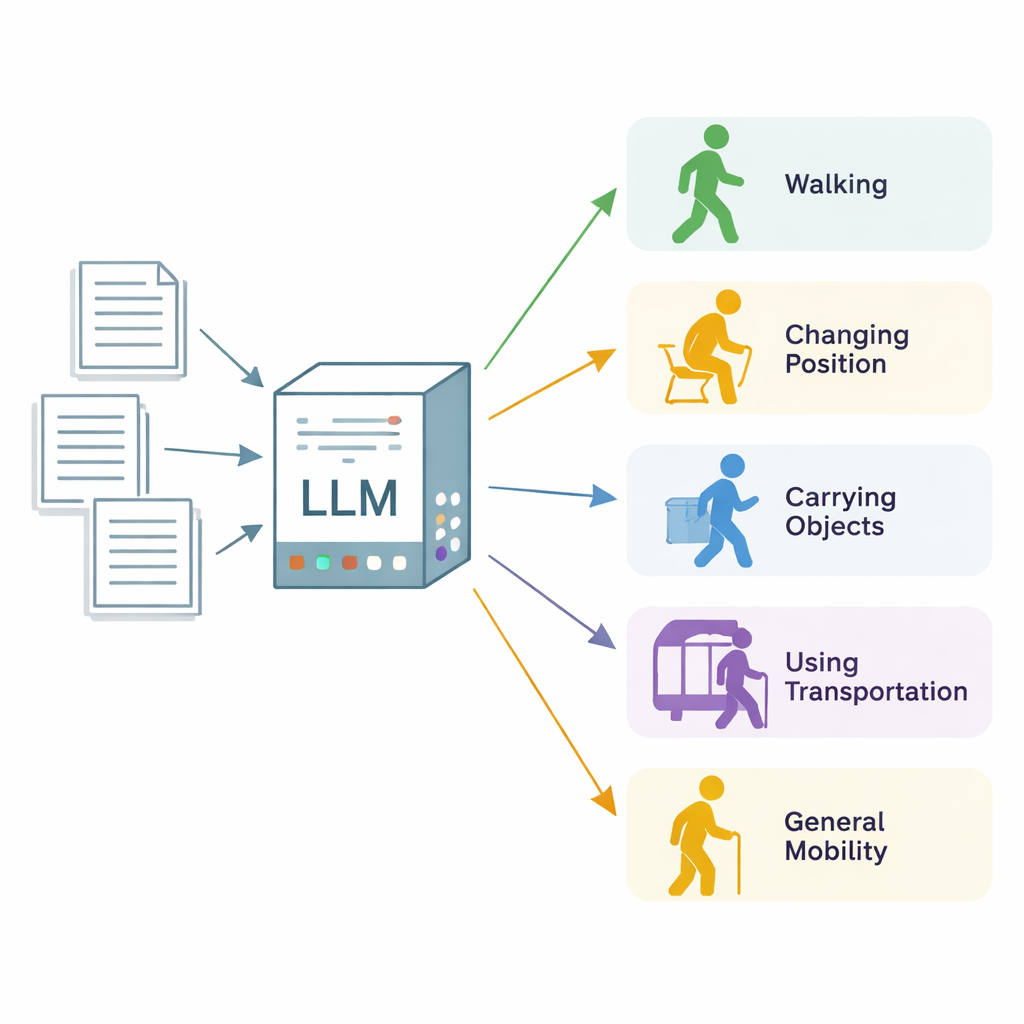
Turning messy notes into usable mobility data
The researchers focused on “mobility functional status,” a broad term for how well a person can change body position, walk, carry and handle objects, use transportation, and move in everyday life. They drew on 600 real clinical notes from three health care institutions in Minnesota and Wisconsin, most from physical and occupational therapy visits, plus a set of more general clinic notes. Expert annotators combed through each note, section by section, and labeled every passage that described one of five mobility categories, marking whether the patient was clearly limited (“impaired”) or functioning normally (“unimpaired”). These expert labels served as the gold standard for evaluating the AI system.
How the AI model was trained to read like a clinician
The team used Llama 3, an open‑source large language model, and ran it on secure local servers so that patient data never left the health system. Instead of retraining the model from scratch, they carefully designed prompts—sets of written instructions and definitions—to teach the model what to look for. They tried “zero‑shot” prompts, which give only instructions, and “few‑shot” prompts, which also include a handful of example notes. They then analyzed where the model went wrong and crafted an “error‑informed” prompt that spelled out what to include, what to ignore (such as future treatment plans), and how to handle tricky cases like falls, dizziness, or wheelchair use. The AI was asked, for each note section and each mobility category, whether mobility was mentioned at all and, if so, whether the patient was impaired.
Strong performance improves at the patient level
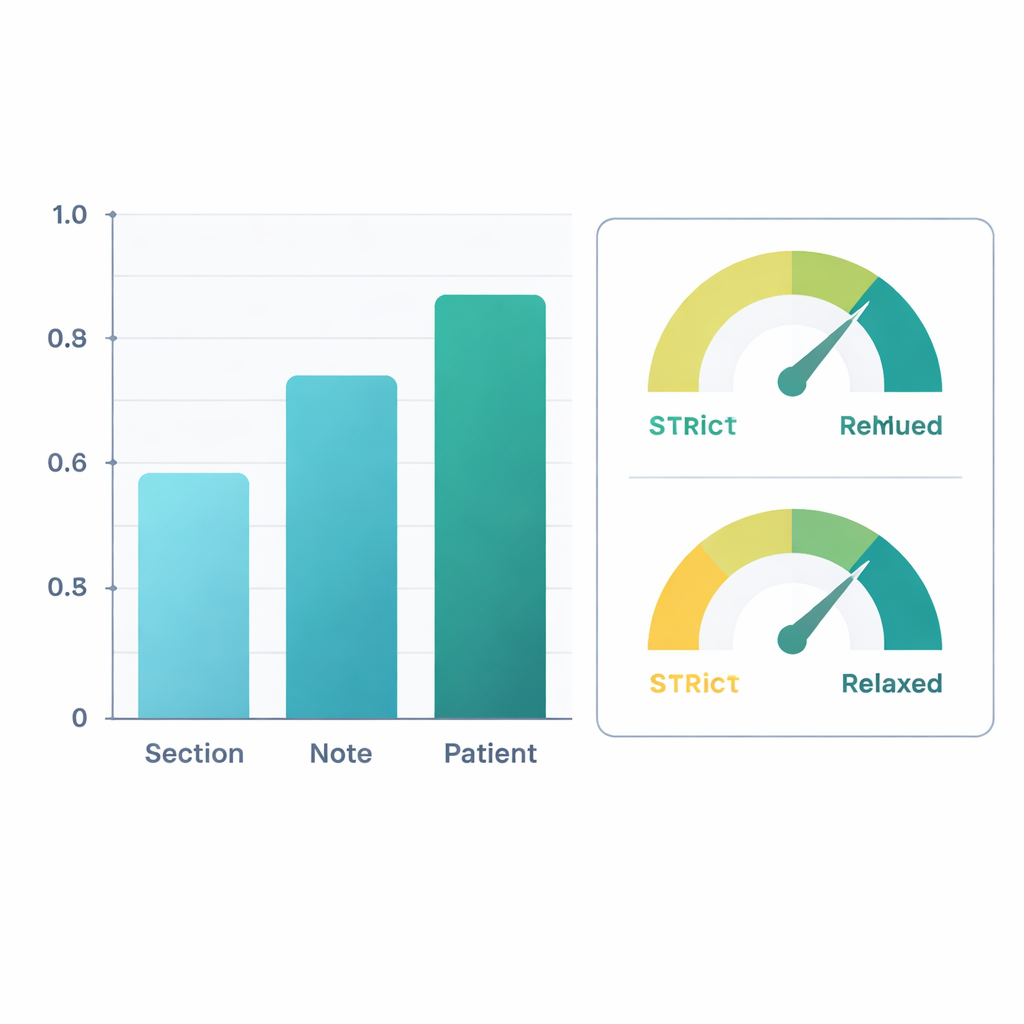
When judged against the expert labels, the refined system performed well. At the level of entire patients—combining information across all their notes—the AI reached an F1‑score (a common accuracy measure) of about 0.88 for simply finding mobility information and 0.90 for deciding whether the person was impaired. That means its judgments closely matched those of human reviewers. Performance was somewhat lower when looking at individual sections of notes, where wording can be sparse or ambiguous, but accuracy improved as information was pooled across whole notes and then across all notes for a patient. In a second analysis, the researchers counted “clinically reasonable inferences” as correct—for example, assuming that severe knee pain during walking likely limits walking, even if not stated outright. Under this more forgiving view, patient‑level F1‑scores rose above 0.96 for extraction and 0.95 for impairment classification.
What the AI got wrong—and why that still matters
Most errors came from the model reading between the lines. It often inferred mobility problems based on pain, dizziness, or future therapy plans, even when the note never clearly said the patient was limited. Other errors reflected gray areas in the definitions, such as whether repeated falls should be treated as a walking problem or a problem with balance while changing position. The class called “mobility, unspecified,” meant to capture everyday activities and exercise, was especially hard to pin down. Despite these issues, the mistakes were usually sensible from a clinical standpoint rather than random or bizarre. By running the model deterministically (with no built‑in randomness) on locked‑down local servers, the team also ensured that results were reproducible and that patient privacy was preserved.
How this could change care for older adults
For a layperson, the takeaway is that an AI system can now read routine doctor and therapist notes well enough to summarize how well patients move and where they struggle. That means health systems could track changes in walking, balance, and daily activities over time without adding new questionnaires or tests, flag people at high risk of falls or hospital stays, and identify who might benefit from physical therapy or home safety evaluations. By converting millions of free‑text notes into structured mobility data, this approach helps doctors see the bigger picture of how aging and disease affect everyday life—bringing health care a step closer to truly personalized, function‑centered medicine.
Citation: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Keywords: mobility, electronic health records, large language models, functional status, clinical AI