Clear Sky Science · en
A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations
Why smarter medical questions matter
When you visit a doctor, the first diagnosis you hear rarely comes from a single symptom you mention. Instead, doctors ask a series of follow‑up questions—about timing, intensity, related problems—to gradually narrow down what might be wrong. As powerful as today’s AI systems are, most are still tested as if they were taking multiple‑choice exams, not talking to real people. This paper introduces Q4Dx, a new way to judge how well large language models (LLMs) can play the “curious doctor”: choosing the right questions, in the right order, to reach the right diagnosis efficiently.
From exam questions to real conversations
Most existing medical AI tests give models neat, fully specified cases—like a textbook problem—and ask them to pick a diagnosis. That shows what the system “knows,” but not how it would behave in a messy, real‑world conversation with a patient who forgets details or describes symptoms in everyday language. The authors argue that this is a serious blind spot. In clinics, information comes out slowly and often inexactly; a good clinician’s skill lies as much in what they ask as in what they already know. Q4Dx is designed to close this gap by shifting the focus from static question answering to the strategy of asking questions over time.
Building lifelike patient stories
To create this new testbed, the researchers start from a curated medical resource that links specific diseases with hallmark symptom sets. They randomly select 100 such disease–symptom pairs and then use an AI model to transform sterile symptom lists into natural‑sounding patient self‑descriptions—stories like a person might actually tell in a clinic. From each full case, they generate shorter versions where only about 80 percent or 50 percent of the key symptoms are mentioned. This controlled “hiding” of information lets them study how well different models adapt when important clues are missing or only hinted at. Checks on symptom overlap confirm that the shorter versions really do contain less usable information, not just fewer words.
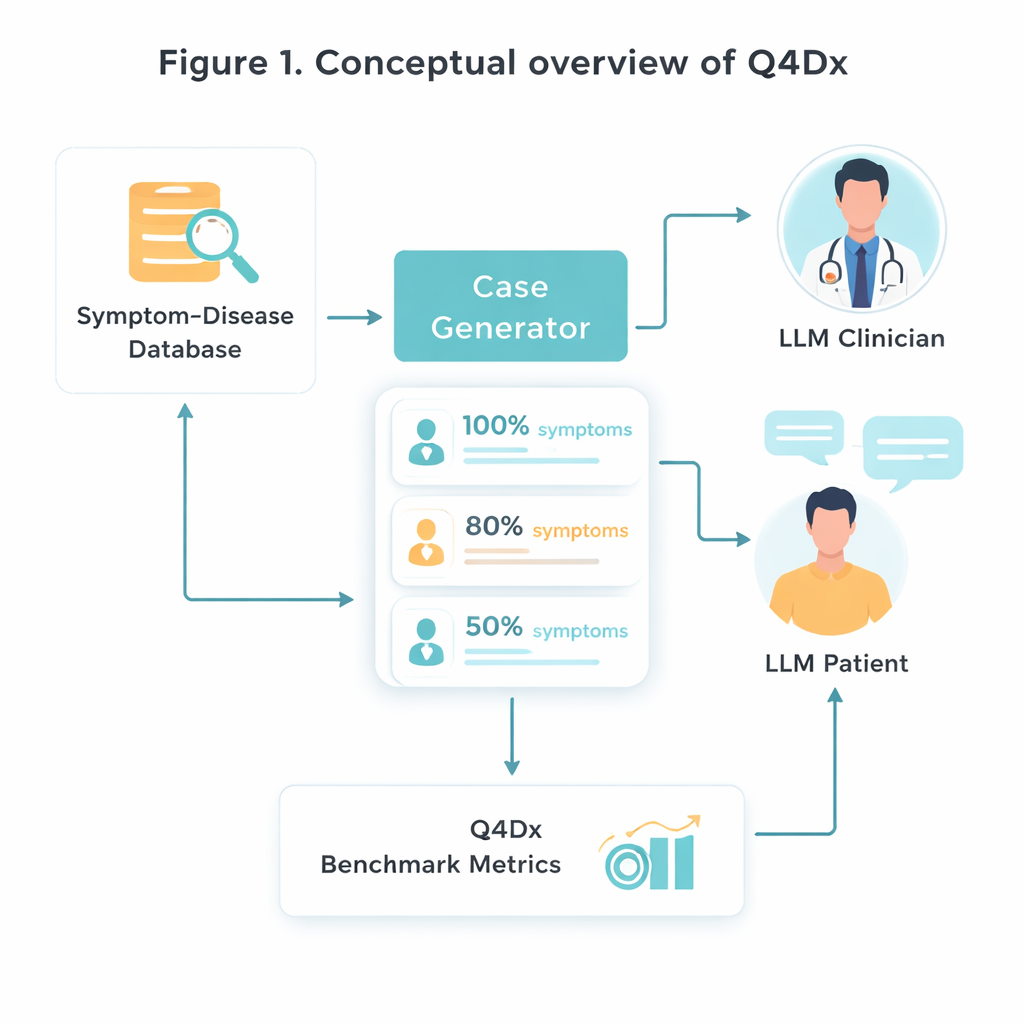
Simulated doctor–patient dialogues
The heart of Q4Dx is a large collection of simulated conversations between two AI agents. One plays the role of the patient, with full access to the underlying disease and its complete symptom set. The other acts as the doctor: it only sees a partial, possibly vague case description at the start and must decide what to ask next. After every patient reply, the doctor agent makes a provisional diagnosis, creating a step‑by‑step trail of how its thinking evolves. By recording all questions, answers, and intermediate guesses, the benchmark captures not just whether the model is right, but how it gets there. These AI‑generated question sequences are used as reference strategies—not as perfect medical truth, but as a consistent yardstick against which future models and even human trainees can be compared.
Measuring good questions, not just right answers
To judge performance, the authors design three simple but complementary measures. Zero‑Shot Diagnostic Accuracy (ZDA) asks: if you give the model the full case up front, can it immediately name the correct disease? Mean Questions to Correct Diagnosis (MQD) reflects efficiency: on average, how many patient questions does the model need before it first lands on the right diagnosis, within a cap of five? Finally, Interrogation Sequence Efficiency (ISE) looks at the quality of the questioning path itself—how similar the model’s chosen questions are, in meaning, to the reference sequence. Using these metrics, the team shows that a strong general‑purpose model (GPT‑4.1) diagnoses correctly about half the time with complete information, but its accuracy drops as symptoms are hidden. At the same time, its interactive sessions typically succeed after just a few well‑chosen questions, and its questions grow more aligned with expert‑like strategies over successive turns.

What this means for future medical AI
For non‑specialists, the message of this work is straightforward: in medicine, asking smart questions is as important as having the right answers, and AI needs to be evaluated on both. Q4Dx offers a reusable, publicly available framework for doing exactly that. By providing realistic patient stories with varying amounts of missing information, detailed conversation traces, and clear measures of both accuracy and efficiency, the benchmark allows researchers to compare different AI systems and even pit them against human clinicians under controlled conditions. Over time, tools like Q4Dx could help train safer, more reliable clinical assistants and improve how doctors and students learn diagnostic interviewing—ultimately supporting better care for real patients.
Citation: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Keywords: medical AI, diagnostic reasoning, clinical dialogue, large language models, questioning strategy