Clear Sky Science · en
Benchmarking action recognition models for self-harm detection in studio and real-world datasets
Watching Over Patients with Digital Eyes
In psychiatric hospitals, nurses work tirelessly to keep patients safe, especially those at risk of hurting themselves. Yet even the most dedicated staff cannot watch every room, every second. This study explores whether artificial intelligence (AI) can help by automatically scanning video from ward cameras to spot early signs of self-harm—offering an extra layer of protection without replacing human care.
Why Self-Harm Is So Hard to Catch
Self-harm—any intentional injury people inflict on themselves—often happens in brief, hidden moments: a quick scratch under a blanket, or a small tool used out of sight. Psychiatric wards rely on regular checks and camera surveillance, but blind spots, staff fatigue, and limited night or holiday staffing make constant vigilance impossible. At the same time, recording and sharing real patient footage raises serious privacy and ethical concerns. As a result, researchers have had very little realistic video to train AI systems that might detect dangerous behavior in real time.
Building Safer Test Beds for AI
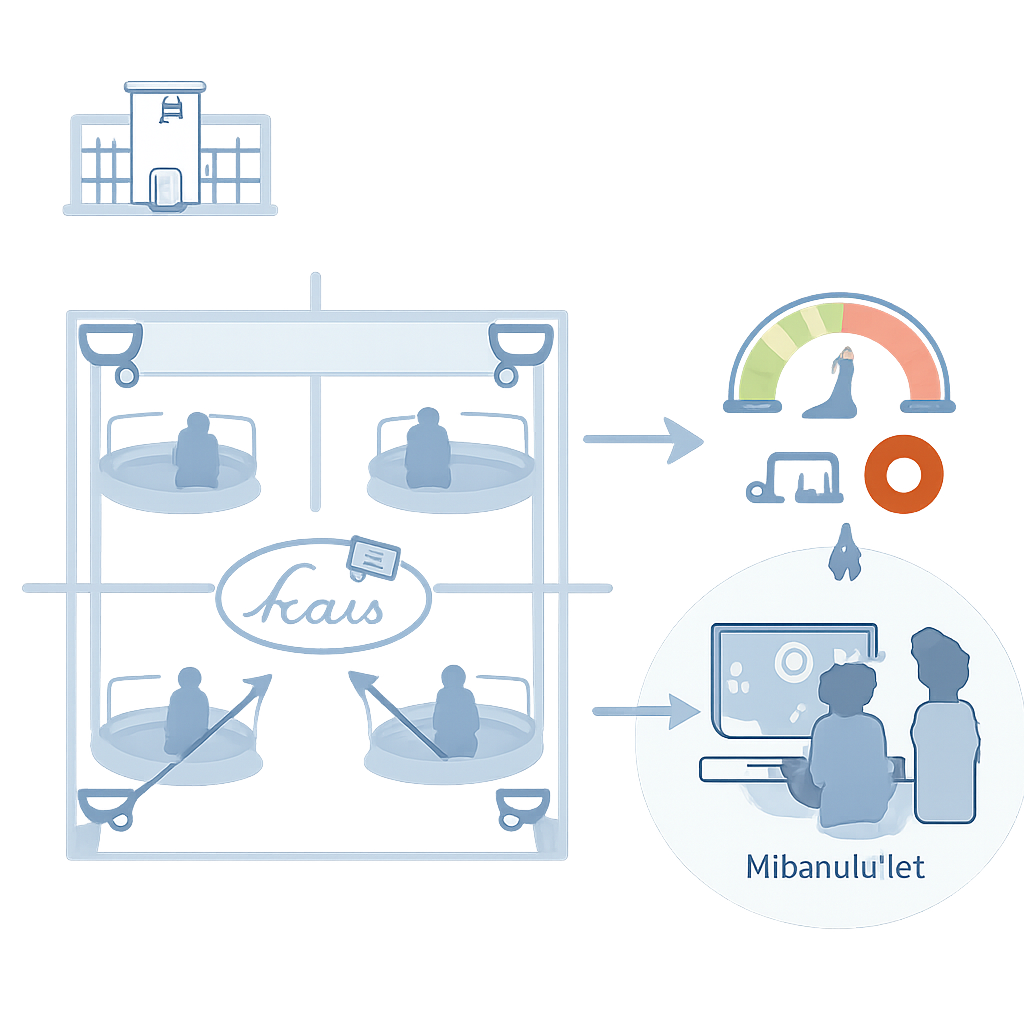
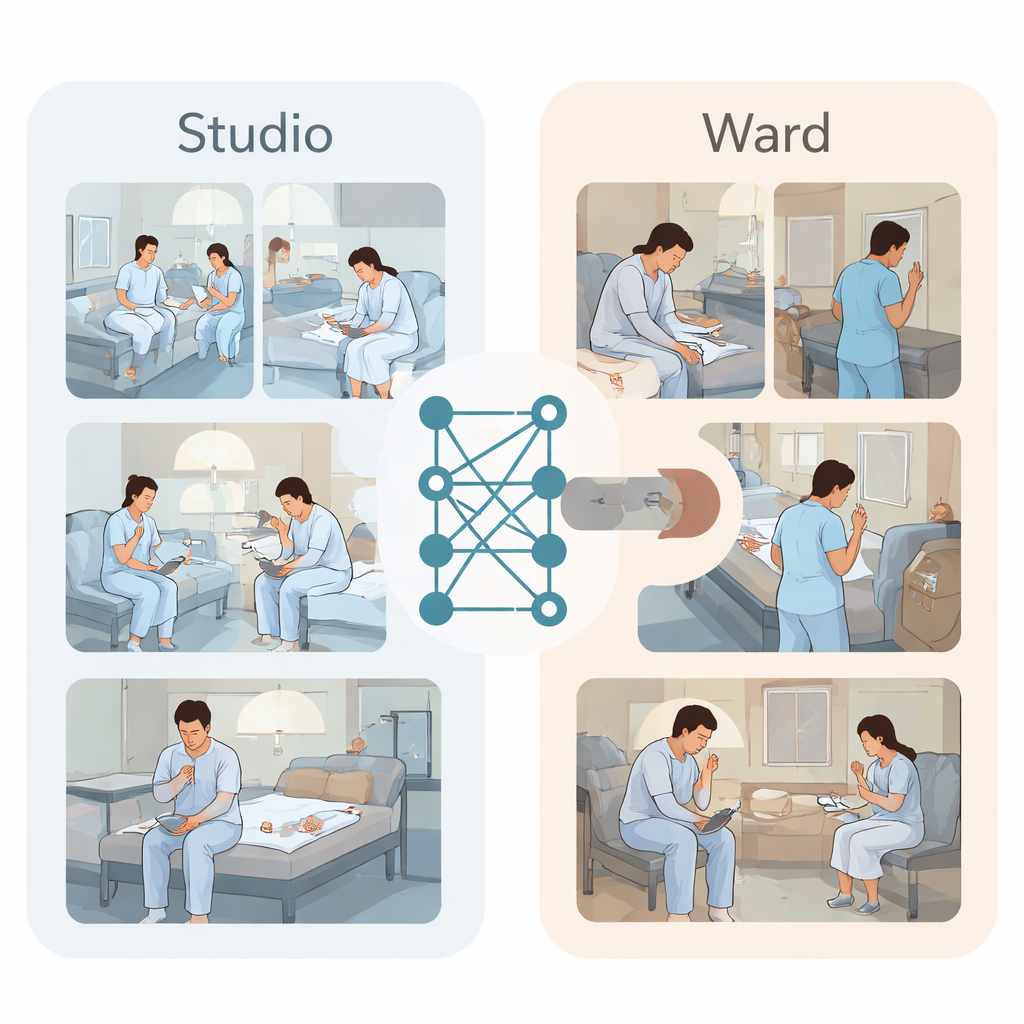
To break this deadlock, the researchers created two kinds of video datasets. First, in a studio made to look like a four-bed psychiatric room, seven young actors in patient gowns performed carefully planned scenes. They searched for everyday objects such as plastic caps, lip balm tubes, or small nails, then acted out short sequences of self-harming motions on the wrist, forearm, or thigh, with overhead cameras recording from all corners. Experts labeled each video segment as either normal behavior or self-harm, building a clean, balanced collection of 1120 clips. Second, the team gathered real surveillance footage from secure psychiatric wards over ten months. Clinicians searched medical records for notes about behaviors like scratching, picking, or cutting and then tracked down the matching video. After blurring faces and removing identifying details, they assembled 59 clips showing actual self-harm and 59 normal clips for comparison.
Putting Today’s Best Video AI to the Test
With these datasets in hand, the team benchmarked leading action-recognition systems—computer programs designed to understand what people are doing in a video. Some were based on older convolutional networks, which analyze short sequences of frames, while newer transformer-based models use attention mechanisms to connect patterns across space and time. All models were trained only on the studio videos to decide whether a clip showed self-harm or normal behavior. Importantly, the researchers used a strict testing scheme: in each round, all clips from one actor were held out as completely new test data, ensuring the algorithms could not simply memorize individual people.
When Clean Lab Videos Meet Messy Reality
On the tidy studio footage, the most advanced transformer model, called VideoMAEv2, stood out. It correctly balanced missed and false alarms better than the others, reaching an F1 score (a combined measure of precision and recall) of about 0.65, while simpler methods hovered near random guessing. Visual explanations showed that this model focused tightly on where a tool met the skin, rather than being distracted by background motion. But once the same trained systems were turned loose on the real ward recordings—without any retraining—their performance dropped. VideoMAEv2 still did better than chance, with an F1 score around 0.61, yet it struggled particularly with subtle behaviors like picking and scratching that had never appeared in the simulated data, and with patients who were small, far from the camera, or partly hidden.
What This Means for Patient Safety
Taken together, the results reveal a clear “simulation-to-reality” gap. AI systems that look promising on carefully staged videos can falter when confronted with the clutter, odd angles, and varied behaviors of real hospital life. The study’s main contribution is not a finished safety product but a starting point: a public, well-annotated studio dataset, a carefully collected real-world test set, and a transparent benchmark showing where current methods break down. For non-specialists, the message is straightforward: AI can already help highlight suspicious moments in ward video streams, but it cannot yet be trusted as a standalone guardian. Closing this gap will require richer, more diverse training data and smarter models, developed with privacy, fairness, and clinical judgment at the forefront.
Citation: Lee, K., Lee, D., Ham, HS. et al. Benchmarking action recognition models for self-harm detection in studio and real-world datasets. Sci Rep 16, 6850 (2026). https://doi.org/10.1038/s41598-026-36999-w
Keywords: self-harm detection, psychiatric wards, video action recognition, artificial intelligence in healthcare, patient safety