Clear Sky Science · en
MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering
Why smarter object finders matter
Phones, cars, home robots, and search engines increasingly rely on software that can find objects in pictures: a child crossing the street, your lost keys on a table, or a specific product on a shelf. But most of today’s systems only understand short, simple labels like “dog” or “car.” When you ask for “the little dog with a red collar lying behind the sofa cushion,” they often get confused. This paper introduces MQADet, a way to upgrade existing object-finding systems so they can understand such rich, detailed descriptions without retraining the underlying models.
From fixed lists to open-ended understanding
Traditional object detectors are trained on fixed lists of categories, such as the 80 everyday items in the popular COCO dataset. They work well as long as the object belongs to one of those categories and the request is short and clear. However, the real world is messy. People refer to things using long phrases, subtle attributes, and relationships like “the man in the yellow vest standing behind the truck.” Newer “open-vocabulary” detectors try to break free of fixed lists by tying images to text, but they still struggle with complex wording and with rare, “long‑tailed” categories that appear infrequently in training data. They also require a lot of computation and data to improve.
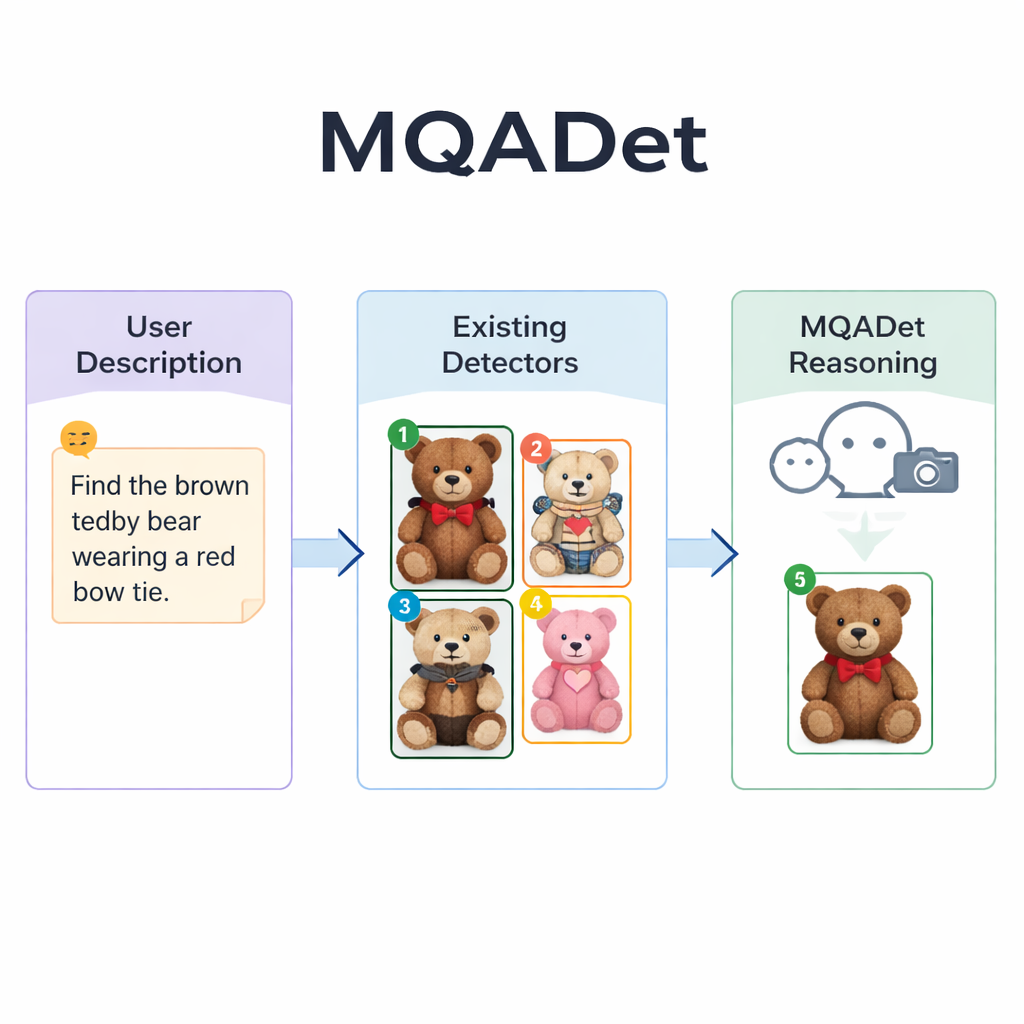
Letting language models guide the search
MQADet tackles these problems by placing a multimodal large language model—a system that can look at images and read text—on top of existing detectors in a three-step question‑answering process. First, a stage called Text‑Aware Subject Extraction reads the user’s whole sentence and pulls out the true targets, such as “umbrella” and “pedestrian” from a long description. This mirrors how a person might quickly identify the main nouns in a sentence before scanning a scene. Crucially, this stage uses the language model’s strong grasp of natural language, so it can handle long, descriptive phrases instead of just single words.
Marking candidate objects in the image
In the second stage, Text‑Guided Multimodal Object Positioning, MQADet hands those extracted subjects plus the image to an existing open‑vocabulary detector—such as Grounding DINO, YOLO‑World, or OmDet‑Turbo. The detector proposes several possible locations in the image where each subject might be, drawing a box around each candidate and placing a simple number inside the box. The result is a “marked image” showing all plausible options. Importantly, MQADet does not retrain these detectors; it simply uses them as they are. This makes the approach plug‑and‑play: whenever a better detector appears, it can be dropped into the pipeline without extra data or tuning.

Reasoning its way to the best match
The third stage, called MLLMs‑Driven Optimal Object Selection, turns the final choice into a multiple‑choice question for the language model: given the original description and the marked image with numbered boxes, which number best matches the text? Because the model sees both the detailed wording and the visual layout, it can weigh fine‑grained clues—patterns, colors, spatial relations like “on the left,” and interactions between objects. The authors show that removing this reasoning step sharply reduces accuracy, underscoring its importance. Using this three‑step design, MQADet improved accuracy across four demanding benchmarks with long, natural sentences, often boosting existing detectors’ performance by 10–40 percentage points without changing their internal weights.
What this means for everyday technology
To a non‑specialist, the key message is that we no longer need to rebuild object detectors from scratch to make them smarter. MQADet acts like an intelligent assistant sitting on top of current systems, helping them interpret rich human descriptions and pick the right object in complex scenes. This could make visual search, assistive tools, and autonomous machines more reliable when dealing with the way people naturally speak—full of detail, nuance, and context—paving the way for more intuitive, language‑driven interaction with the visual world.
Citation: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Keywords: open-vocabulary object detection, multimodal large language models, visual question answering, computer vision, image understanding